IRON AIE Programming Guide(非公式日本語訳)

AI Engine(AIE)アレイは、空間演算アーキテクチャ(spatial compute architecture)です。空間的に分散された演算ユニットとメモリを持つ、モジュラーでスケーラブルなシステムです。その演算密度の高いベクトル処理は、明示的にスケジュールされたデータ移動と独立して並行実行されます。各AIEのベクトル演算コア(緑色)は、そのL1スクラッチパッドメモリ(水色)内のデータに対してのみ動作できるため、Direct Memory Access(DMA)チャネル(紫色)が、メモリ階層の任意のレベルから、スイッチ型(濃青色)相互接続ネットワークを介して双方向にデータを転送します。
AIE配列のプログラミングでは、すべての空間的構成要素を設定します:演算コアのプログラムメモリ、データムーバーのバッファディスクリプタ、スイッチを含む相互接続など。本ガイドでは、AIE配列のIRON(Interface Representation for hands-ON)プログラミングを紹介します。IRONは、mlir-aie(AIE配列のMLIRベース表現)を中心とした一連のPython言語バインディングを通じて、パフォーマンスエンジニアが高速で効率的な、しばしば特化した設計を構築できるようにするオープンアクセスツールキットです。mlir-aieは、複雑で高性能なAI Engine設計を定義できる基盤を提供し、シミュレーションとハードウェア実装インフラストラクチャによってサポートされています。
IRONは、ユーザーの経験レベルに合わせてAIE配列のプログラミングへの複数のエントリーポイントを提供します。最も高い抽象化レベルでは、基盤となるハードウェアアーキテクチャの深い知識を必要とせずに、専用タスクをワーカーに割り当てるプログラムを作成できます。AIE配列の設定をより細かく制御したいユーザーには、IRONは明示的な配置を行うAPIをサポートしています。本ガイドは、両方のプログラミングレベルが各セクションで説明されるように構成されています。
注意: NPUをIRONでプログラミングする方法を素早く理解したい方は、ミニチュートリアルをご覧ください!
このIRON AIEプログラミングガイドでは、まずAIE配列の構造要素に対する言語バインディングを紹介します(セクション1)。必要なデータを転送するための明示的なデータ移動の設定方法を説明した後(セクション2)、AIE演算コアで最初のプログラムを実行できます(セクション3)。セクション4では、性能分析のためのトレース機能を追加し、演算密度の高いベクトル演算の活用方法を説明します。基本的なものから大規模なもの(機械学習やコンピュータビジョン)まで、より多くのベクトル設計例をセクション5と6で紹介します。最後に、クイックリファレンスで最も重要なAPI要素をまとめています。
目次
-
Section 0 - Getting Set Up for IRON
- IRONでターゲットとする推奨ハードウェアの紹介
- ハードウェア、ツール、環境のセットアップ手順
-
Section 1 - Basic AI Engine building blocks
- アプリケーション設計を表現するためのAI Engine構成要素の紹介
- AIEタイルを定義するMLIRソースのPythonバインディング例
-
Section 2 - Data Movement (Object FIFOs)
- objectfifoとそれがタイル間の接続とAIE配列メモリ内のデータをどのように抽象化するかを紹介
- 主要なobjectfifoデータ移動パターンの説明
- より複雑なobjectfifo接続パターン(broadcast、implicit copy、join、distribute)の紹介
- 実践的な例でobjectfifoを実演
- ホストとAIE配列間のランタイムデータ移動の説明
-
- 最初のシンプルなプログラム(ベクトルスカラー乗算)の例を紹介
- Ryzen™ AI対応ハードウェアで設計を実行する方法を説明
-
Section 4 - Performance Measurement & Vector Programming
- 性能測定(タイマー、トレース)の紹介
- カーネルレベルでのベクトルプログラミングの説明
-
Section 5 - Example Vector Designs
- 性能測定の演習を含む追加のベクトル設計例:
- パススルー
- ベクトル $e^x$
- ベクトルスカラー加算
- GEMM
- CONV2D
- その他
- 性能測定の演習を含む追加のベクトル設計例:
-
Section 6 - Larger Example Designs
- 複数のコアで性能を測定した大規模設計例:
- エッジ検出
- ResNet
- その他
- 複数のコアで性能を測定した大規模設計例:
AI Engineアーキテクチャドキュメント
AMD XDNA™ リファレンス
注意: これは公式プログラミングガイドの非公式日本語訳です。正確な情報については、常に公式の英語版ドキュメントを参照してください。
ライセンス: 元のドキュメントは Apache License v2.0 with LLVM Exceptions の下でライセンスされています。
Section 0 - Getting Set Up for IRON
このプログラミングガイドは、Ryzen™ AIラップトップおよびミニPCに搭載されているNPUのアプリケーションプログラミングに焦点を当てています。Ryzen™ AI CPUの最新情報はこちらでご確認いただけます。
推奨ハードウェアの例
- Phoenix Point Mini PC: Minisforum EM780 : AMD Ryzen™ 7 7840U
- Hawk Point Mini PC: Minisforum UM890 Pro : AMD Ryzen™ 9 8945HS
- Strix Point Mini PC: Minisforum AI X1 Pro : AMD Ryzen™ AI 9 HX 370
- Krackan Point Mini PC: ASRock 4x4 BOX-AI350 : AMD Ryzen™ AI 7 350
AMD Ryzen™ AI 初期セットアップ
クイックセットアップの手順に必ず従ってください。
注意: このページは公式ドキュメントの非公式日本語訳です。
Section 1 - Basic AI Engine building blocks
AIE配列をプログラミングする際、その構造的な構成要素を宣言して設定する必要があります:ベクトル処理のためのコンピュートタイル(compute tiles)、より大きなレベル2の共有スクラッチパッドとしてのメモリタイル(memory tiles)、NPU外部メモリ(つまりメインメモリ)へのデータ移動をサポートするシムタイル(shim tiles)です。このプログラミングガイドでは、IRON Pythonライブラリを使用します。これにより、使用するAI Engineタイルの選択、各タイルが実行すべきコード、タイル間のデータ移動方法、CPU側からの設計呼び出し方法など、NPU設計全体を記述できます。後ほど、C/C++でのベクトルプログラミングを探求します。これは個々のコンピュートタイル用の計算カーネルを最適化するのに役立ちます。
Pythonソースファイル(aie2.py)のウォークスルー
まず、IRON設計の最も高い抽象化レベルでの基本的なPythonソースファイル(aie2.pyという名前)を見てみましょう:
このPythonソースの先頭で、IRONライブラリを定義するモジュールをインポートします:高レベル抽象化構造のためのaie.iron、リソース配置アルゴリズムのためのaie.iron.placers、ターゲットアーキテクチャのためのaie.iron.deviceです。
from aie.iron import Program, Runtime, Worker, LocalBuffer
from aie.iron.placers import SequentialPlacer
from aie.iron.device import NPU1Col1, Tile
AIE配列内部のデータ移動も通常この段階で宣言されますが、設計設定のその部分は専用のセクションがあり、ここでは詳しく説明しません。
# データフロー設定
# ガイドの今後のセクションで説明...
AIE配列では、計算カーネルはコンピュートタイル上で実行され、これはWorkerで表されます。Workerは実行するルーチンと、それを実行するために必要な引数のリストを入力として受け取ります。Workerクラスは以下に定義されており、worker.pyで見つけることができます。Workerは、AIE配列内のplacementタイルに明示的に配置することも、このセクションでさらに説明するように、配置をコンパイラに任せることもできます。最後に、while_true入力はデフォルトでTrueに設定されています。これは、Workerが設計開始後に通常継続的に実行されるためです。
class Worker(ObjectFifoEndpoint):
def __init__(
self,
core_fn: Callable | None,
fn_args: list = [],
placement: PlacementTile | None = AnyComputeTile,
while_true: bool = True,
)
この単純な設計では、core_fnルーチンを実行する1つのWorkerのみがあります。計算ルーチンはローカルデータバッファを繰り返し処理し、各エントリをゼロに初期化します。この場合、計算ルーチンには入力がありません。ガイドの次のセクションで見るように、計算タスクは通常、外部メモリからAIE配列に持ち込まれたデータ上で実行され、生成された出力は外部に送り返されます。この例では、WorkerはAIE配列の座標(0,2)のコンピュートタイルに明示的に配置されていることに注意してください。
# Workerが実行するタスク
def core_fn():
local = LocalBuffer(data_ty, name="local")
for i in range_(data_size):
local[i] = 0
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [], placement=Tile(0, 2), while_true=False)
注意 1:
range_のアンダースコアに気付きましたか?IRONはNPU設計を通常のPythonプログラムのように見せますが、ここで書くコードがNPU上で直接実行されるわけ ではない ことを理解することが重要です。代わりに、IRON設計で書くコードは 他のコードを生成します (メタプログラミング)。これは、コード文字列を含むprint文を書くようなものです。その後、ツールチェーンがこの生成された他のコードをコンパイルし、それがNPU上で直接実行できるようになります。これは、上記の例で
range_の代わりにrangeを書くと、生成されるNPUコードには多くのlocal[i] = 0命令が含まれますが、ループは全くないということを意味します(ループは「展開」され、バイナリが大きくなり、ループの反復回数はコード生成時に固定されている必要があります)。一方、range_を使用すると、Pythonはループ本体を1回だけ実行して(そこに含まれる命令を収集し)、NPUコードにループを発行します。そしてNPUがループを実行します。 同じことはifのような他の分岐構造にも当てはまります。Pythonのネイティブ構造を使用すると、NPUコードに実際の分岐が発行されないことを意味します!
注意 2: 上記のコードのWorkerは
while_true=Falseでインスタンス化されています。デフォルトでは、この属性はTrueに設定されており、その場合、タスクで表現されるカーネルコードは、ステップ1でsys.maxsizeまで反復するforループでラップされます。これは、Workerのコードを無限にループさせる意図でwhile(True)をシミュレートします。一意の名前でローカルバッファを作成する場合など、タスクコードによっては、これによりコンパイラの問題が発生する可能性があります。
前のコードスニペットで、Worker間のデータ移動を設定する必要があると述べました。これには、Runtimeシーケンス内で処理されるAIE配列との間のデータ移動は含まれません。プログラミングガイドには、ランタイムデータ移動の専用セクションがあります。この例では、データ移動設定を詳しく見ないため、ランタイムシーケンスはWorkerを開始するだけです。
# AIE配列との間でデータを移動するランタイム操作
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, _):
rt.start(my_worker)
すべてのコンポーネントは、デバイス上で設計を実行するために必要なすべての設計情報を表すProgramにまとめられます。また、この段階で、以前に配置されていないWorkerがPlacerを使用してAIEタイルにマッピングされます。現在、IRONで利用可能な配置アルゴリズムは1つだけで、以下のコードスニペットに見られるSequentialPlacer()です。他のplacerは最小限の労力で追加でき、placers.pyにあるこれらのツールを試すことをすべてのユーザーに推奨します。最後に、プログラムが印刷され、IRONライブラリとPython言語バインディングから対応するMLIR定義が生成されます。
# デバイスタイプとランタイムからプログラムを作成
my_program = Program(NPU1Col1(), rt)
# コンポーネントを配置(デバイス上のリソースを割り当て)してMLIRモジュールを生成
module = my_program.resolve_program(SequentialPlacer())
# 生成されたMLIRを印刷
print(module)
注意: 上記で説明または言及されたすべてのコンポーネントは、
resolvableインターフェースを継承しており、resolve()関数が呼び出されるまでMLIR操作の作成を延期します。それがProgramのresolve_program()関数のタスクであり、IRONクラスの1つがMLIR等価物を生成するのに十分な情報を持っていない場合、エラーが発生します。
Pythonソースファイル(aie2_placed.py)のウォークスルー
IRONは、コンポーネントが座標を使用してAIEタイルに明示的に配置されるタイルレベルの粒度で設計を記述することもできます。このレベルでのIRON設計の基本的なPythonソースファイル(aie2_placed.pyという名前)を再度見てみましょう。
このPythonソースの先頭で、IRON AIEライブラリaie.dialects.aieとmlir-aieコンテキストaie.extras.contextを定義するモジュールをインポートします。これらはAI EnginesのMLIR定義にバインドされます。
from aie.dialects.aie import * # プライマリmlir-aieダイアレクト定義
from aie.extras.context import mlir_mod_ctx # mlir-aieコンテキスト
次に、mlir-aieコンテキスト内から呼び出されたときにMLIRコードに展開される構造設計関数を宣言します(このサブセクションの最後の部分を参照)。
# AI Engine構造設計関数
def mlir_aie_design():
<... AI Engineデバイス、ブロック、接続 ...>
AI Engineデバイス、ブロック、接続の宣言方法を見てみましょう。まず、@device(AIEDevice.npu1_1col)または@device(AIEDevice.npu2)を介してAIEデバイスを宣言します。ブロックと接続自体は、def device_body():内で宣言されます。ここで、AI Engineブロックをインスタンス化します。この最初の例ではAIEコンピュートタイルです。
タイル宣言の引数はタイル座標(列、行)です。宣言された各タイルをPythonプログラムの変数に割り当てます。
注意: プログラムが実行されるときにデバイス上で使用される実際のタイル座標は、ここで宣言されたものと異なる場合があります。たとえば、Ryzen™ AI上のNPU(
@device(AIEDevice.npu))では、これらの座標は相対座標である傾向があり、ランタイムスケジューラがランタイム中に別の利用可能な列に割り当てる場合があります。
# デバイス宣言 - ここではaie2デバイスNPUを使用
@device(AIEDevice.npu1)
def device_body():
# タイル宣言
ComputeTile1 = tile(1, 3)
ComputeTile2 = tile(2, 3)
ComputeTile3 = tile(2, 4)
コンピュートコアはコンピュートタイルにマッピングできます。また、コアの本体内から呼び出すことができる外部カーネル関数にリンクすることもできますが、それはこのセクションの範囲を超えており、ガイドでさらに説明されます。この例の設計では、コンピュートコアはローカルデータテンソルを宣言し、それを繰り返し処理し、各エントリをゼロに初期化します。
data_size = 48
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
# コンピュートコア宣言
@core(ComputeTile1)
def core_body():
local = buffer(ComputeTile1, data_ty, name="local")
for i in range_(data_size):
local[i] = 0
設計関数内でブロック(と接続)の宣言が完了したら、プログラムのメイン本体に移り、関数を呼び出してMLIRで設計を出力します。これは、まずwith mlir_mod_ctx() as ctx:の行を介してMLIRコンテキストを宣言することによって行われます。これは、後続のインデントされたPythonコードがMLIRコンテキストにあることを示し、以前に定義した設計関数mlir_aie_design()を呼び出します。これは、設計関数内のすべてのコードがMLIRコンテキストにあると理解され、より詳細なMLIRブロック定義のIRONカスタムPythonバインディング定義を含むことを意味します。最後の行はprint(ctx.module)で、MLIRコンテキストで定義されたコードを取得してstdoutに印刷します。これにより、Pythonバインドコードが対応するMLIRに変換され、stdoutに印刷されます。
# 後続のコードがmlir-aieコンテキストにあることを宣言
with mlir_mod_ctx() as ctx:
mlir_aie_design() # mlir-aieコンテキスト内で設計関数を呼び出す
print(ctx.module) # PythonからMLIRへの変換をstdoutに印刷
その他のタイルタイプ
コンピュートタイルの他に、AIE配列にはL3メモリにアクセスするためのデータムーバー(シムDMAとも呼ばれる)と、より大きなL2スクラッチパッド(メモリタイルと呼ばれる)も含まれます。これらはAIE-ML世代以降で利用可能です - このプログラミングガイドの序文を参照してください。これらの他のタイプの構造ブロックの宣言は同じ構文に従いますが、特定のターゲットデバイスの物理レイアウトの詳細が必要です。シムDMAは通常行0を占め、メモリタイル(利用可能な場合)は行1に存在することが多いです。次のコードセグメントは、単一のNPU列で見つかるすべての異なるタイルタイプを宣言しています。
# デバイス宣言 - ここではaie2デバイスNPUを使用
@device(AIEDevice.npu1)
def device_body():
# タイル宣言
ShimTile = tile(0, 0)
MemTile = tile(0, 1)
ComputeTile1 = tile(0, 2)
ComputeTile2 = tile(0, 3)
ComputeTile3 = tile(0, 4)
ComputeTile4 = tile(0, 5)
演習
-
コマンドラインからPythonプログラムを実行するには、
python3 aie2.pyと入力します。これにより、Python構造設計がMLIRソースコードに変換されます。設計環境にmlir-aie Pythonバインドダイアレクトモジュールが既に含まれている場合、コマンドラインから機能します。これをMakefileに含めたので、今すぐmakeを実行してください。次に、build/aie.mlirで生成されたMLIRソースを確認します。 -
make cleanを実行して生成されたファイルを削除します。Workerのコード(core_fn)でrange_をrange(アンダースコアなし)に置き換えます。何が起こると予想しますか?build/aie.mlirの生成されたコードを調査し、生成されたコードがどのように変更されたかを観察してください。答えを見る
生成されたMLIRコードにはループが含まれず、代わりに同じ命令が何度も繰り返されます。 -
再び
make cleanを実行します。次に、sequenceをsequencにスペルミスするなど、Pythonソースにエラーを導入し、再びmakeを実行します。どのようなメッセージが表示されますか?答えを見る
sequencが認識されないため、Pythonエラーがあります。 -
再び
make cleanを実行します。次に、sequencをsequenceに戻してエラーを変更しますが、Workerを座標(-1, 3)のタイルに配置します。これは無効な場所です。再びmakeを実行します。今度はどのようなメッセージが表示されますか?答えを見る
部分配置エラーがあります。 -
再び
make cleanを実行します。Workerタイルを元の座標に戻します。Workerからwhile_true=False属性を削除し、再びmakeを実行します。何が観察されますか?答えを見る
Workerタスクコードがforループ内にネストされています。 -
次に、配置されたバージョンのコードを見てみましょう。
make placedを実行し、build/aie_placed.mlirで生成されたMLIRソースを確認します。 -
make cleanを実行して生成されたファイルを削除します。ComputeTile1の座標を(-1,3)に変更して、上記と同じエラーを導入します。再びmake placedを実行します。今度はどのようなメッセージが表示されますか?答えを見る
エラーは生成されません。 -
エラーは生成されませんが、コードは無効です。
build/aie_placed.mlirで生成されたMLIRコードを確認してください。この生成された出力は無効なMLIR構文であり、このMLIRソースでmlir-aieツールを実行するとエラーが生成されます。ただし、関数ctx.module.operation.verify()を使用すると有効化できる追加のPython構造構文チェックがあります。これは、Pythonバインドコードがmlir-aieコンテキスト内で有効な操作を持っているかどうかを検証します。次のようなコードブロックを使用して、
ctx.module.operation.verify()のチェックでprint(ctx.module)呼び出しを限定します:res = ctx.module.operation.verify() if res == True: print(ctx.module) else: print(res)この変更を行い、再び
make placedを実行します。今度はどのようなメッセージが表示されますか?答えを見る
最小値が0であるため、'column value fails to satisfy the constraint'と表示されるようになります。
注意: このページは公式ドキュメントの非公式日本語訳です。
Section 2 - データ移動(Object FIFO)
このセクションでは、AIE配列内のデータ移動を記述するために使用される高レベル通信プリミティブ「Object FIFO」を紹介します。このガイドの最後には、以下ができるようになります:
- 通信プリミティブAPIの高レベルな理解を得る
- 意味のある設計例を通じてObject FIFOの初期化とアクセス方法を学ぶ
- Object FIFO設計における現在の制限や制約につながった設計上の決定を理解する
- Object FIFOの実装とより低レベルの変換に関するより詳細な資料がどこにあるかを知る
データ移動抽象化の必要性を理解するには、まず扱っているハードウェアアーキテクチャを理解する必要があります。AIE配列は、明示的なデータ移動要件を持つ空間演算アーキテクチャです。配列の各コンピュートユニットは、そのL1メモリモジュール内に格納されているデータを処理します。そのデータは、AIE配列のグローバルデータ移動設定の一部として、そこに明示的に移動される必要があります。この設定には、データが損失なく目的地に到着するように配列全体でデータ移動を処理するいくつかの特殊なハードウェアリソースが含まれます。Object FIFOは、ハードウェアが提供するより高度な制御可能性を犠牲にすることなく、より人間が理解しやすくアクセスしやすい方法でデータ移動を指定する方法をユーザーに提供します。
注意: MLIRでのObject FIFOプログラミングに関するより詳細で低レベルな資料については、MLIR-AIEチュートリアルを参照してください。
このガイドは5つのセクションに分かれており、各セクションは前のセクションの上に構築されます:
注意: Section 2fには、Object FIFOを使用した一般的な設計パターンを含む実践的なコード例が多数含まれており、すぐに取得して目的の用途に合わせて調整できます。
-
- Object FIFOの初期化
- Object FIFOのオブジェクトへのアクセス
- 同じプロデューサ/コンシューマを持つObject FIFO
-
Section 2b - 主要なObject FIFOパターン
- Object FIFOがサポートするデータ移動パターンの紹介
- 再利用(Reuse)
- ブロードキャスト(Broadcast)
- 分散(Distribute)
- 結合(Join)
- Object FIFOがサポートするデータ移動パターンの紹介
-
- データレイアウト変換機能の紹介
-
- ホストメモリとAIE配列間のランタイムデータ移動を管理するプロセスのウォークスルー
-
- 複数コアを持つ設計への効率的なアップグレードプロセスのウォークスルー
-
- Object FIFOを使用した実践的な例
- シングル/ダブルバッファ
- 外部メモリからコアへ
- L2を使用した外部メモリからコアへ
- L2での分散
- L2での結合
- Object FIFOを使用した実践的な例
-
Section 2g - Object FIFOを使用しないデータ移動
- DMAリージョンをプログラミングするプロセスのウォークスルー
Section 2a - はじめに
Object FIFOの初期化
Object FIFOは、ソースと1つまたは複数の宛先間のデータ移動接続を表します。Object FIFOのエンドポイントは、プログラムの残りの部分での使用方法に基づいて推論されます。IRONでは、ObjectFifoクラスコンストラクタ(objectfifo.pyで定義)を使用してObject FIFOを初期化できます:
class ObjectFifo(Resolvable):
def __init__(
self,
obj_type: type[np.ndarray],
depth: int | None = 2,
name: str | None = None,
dims_to_stream: list[Sequence[int]] | None = None,
dims_from_stream_per_cons: list[Sequence[int]] | None = None,
plio: bool = False,
)
Object FIFOは、depth個のオブジェクトのカウントを持つ順序付けバッファとして機能します。デフォルトでは2に設定されており、これはダブルまたはピンポンバッファリングを表します。Object FIFO内のすべてのオブジェクトは、同じobj_typeデータ型である必要があります。データ型はテンソルのような属性で、テンソルのサイズと個々の要素の型が同時に指定されます(例:np.ndarray[(16,), np.dtype[np.int32]])。name入力は一意である必要があり、ユーザーが指定するか、コンパイラが完成させるために空のままにすることができます。これは、コンパイラフローの後続の変換ステップに必要です。
AIE配列を横断する際、Direct Memory Access(DMA)チャネルの機能を使用してデータを再構成できます。これらのコンポーネントについてはこちらで詳しく説明していますが、簡単な紹介として、DMAは配列の各タイルに存在し、AXIストリーム相互接続に到着するデータをタイルのローカルメモリに書き込む責任があります(逆も同様)。DMAには、Object FIFOのプロデューサ(dims_to_stream入力を使用)または各コンシューマ(dims_from_stream_per_cons入力を使用)によってAXIストリームに送信されるデータの順序を表現するアクセスパターンを与えることができます。これらの入力には専用のセクションがあります(section-2cのデータレイアウト変換を参照)。plio入力は、Object FIFOのエンドポイントの1つがシムタイルである場合に使用でき、通信が専用のplioポートを介して配線されることをコンパイラに示します。
以下は、データ型<256xi32>で深さ3のinという名前のObject FIFOを初期化する例です:
# テンソル型を定義
line_size = 256
line_type = np.ndarray[(line_size,), np.dtype[np.int32]]
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(line_type, name="in", depth=3)
Object FIFOのエンドポイントはプロデューサとコンシューマに分けられ、Object FIFOは1つのプロデューサと1つまたは複数のコンシューマのみを持つことができます。これらのエンドポイントは、データフロー理論の用語に基づいて、Object FIFOの「アクター」とも呼ばれます。この抽象化レベルでは、エンドポイントは通常、ObjectFifoHandleにアクセスできるWorkerです。もう1つの使用例は、実行時にObject FIFOが外部メモリから満たされる、または外部メモリに排出される場合です(ランタイムデータ移動セクションで説明)。
以下のコードスニペットは、core_fnとcore_fn2で定義されたプロセスを実行する2つのWorkerを示しており、それぞれof_inのプロデューサハンドルまたはコンシューマハンドルを入力として受け取ります:
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(line_type, name="in", depth=3)
# 外部バイナリカーネル定義
test_fn = Kernel(
"test_func",
"test_func.cc.o",
[line_type, np.int32],
)
test_fn2 = Kernel(
"test_func2",
"test_func2.cc.o",
[line_type, np.int32],
)
# コアが実行するタスク
def core_fn(of_in, test_func):
# ...
def core_fn2(of_in, test_func2):
# ...
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of_in.prod(), test_fn])
my_worker = Worker(core_fn2, [of_in.cons(), test_fn2])
Object FIFOは1つのプロデューサプロセスのみを持つことができるため、prod()への各呼び出しは同じObjectFifoHandleへの参照を返しますが、cons()の各呼び出しは、そのコンシューマプロセス用の新しいObjectFifoHandleへの参照を返します。
このセクションの冒頭で、コンパイラは使用方法に基づいてObject FIFOのエンドポイントを推論できると述べました。これは具体的には、Object FIFOのプロデューサとコンシューマを収集するために使用できるObjectFifoHandleの使用を指します。したがって、次のセクションの主題である異なるデータ移動パターンを観察できます。
コンパイラフローの次のステップでは、Object FIFOプロデューサとコンシューマのWorkerプロセスは、Placerを使用して明示的なAIEタイルにマッピングされます(Section 1 - AI Engineの基本構成要素を参照)。内部的には、異なるタイプのタイル(シムタイル、メモリタイル、コンピュートタイル)のデータ移動設定は異なりますが、Object FIFOを使用する場合、それらの間に違いはありません。
より低レベルのIRON APIを使用してObject FIFOを初期化するには、object_fifoクラスコンストラクタ(aie.pyで定義)を使用できます:
class object_fifo:
def __init__(
self,
name,
producerTile,
consumerTiles,
depth,
datatype: MemRefType | type[np.ndarray],
dimensionsToStream=None,
dimensionsFromStreamPerConsumer=None,
initValues=None,
via_DMA=None,
plio=None,
disable_synchronization=None,
)
一部の入力は高レベルと同じですが、他の入力はわずかに異なります。各入力が何を表し、なぜ抽象化に必要なのかを説明します。まず必須の入力に焦点を当て、後でデフォルト値を持つ入力について説明します。dimensionsToStreamとdimensionsFromStreamPerConsumer入力には専用のセクションがあります(section-2cのデータレイアウト変換を参照)。
最高レベルの抽象化と同様に、Object FIFOは、指定されたdatatypeのdepth個のオブジェクトのカウントを持つ順序付けバッファとして機能します。現在、Object FIFO内のすべてのオブジェクトは同じデータ型である必要があります。datatypeはテンソルのような属性で、テンソルのサイズと個々の要素の型が同時に指定されます(例:<16xi32>)。以前とは異なり、depthは整数または整数の配列として定義できます。後者については、このセクションで後述します。
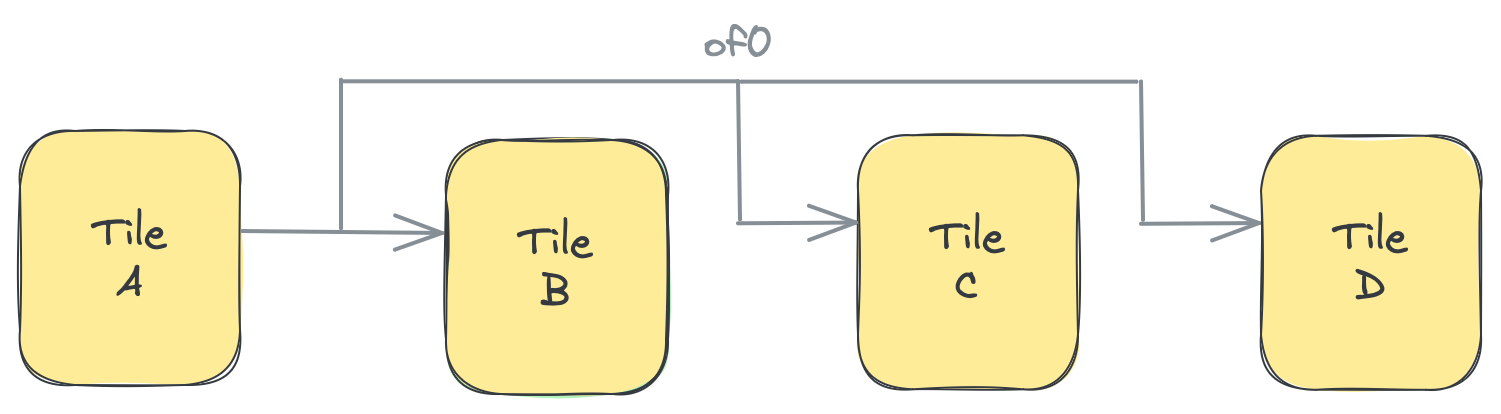
Object FIFOは、プロデューサまたはソースタイルと、コンシューマまたは宛先タイル間で作成されます。タイルは、Object FIFOにアクセスするプロデューサおよびコンシューマプロセスが実行される場所です。これらのプロセスは、データフロー理論の用語に基づいて、Object FIFOの「アクター」とも呼ばれます。以下は、プロデューサタイルAとコンシューマタイルB間に深さ3でof_inが作成される例です:
A = tile(1, 3)
B = tile(2, 4)
of_in = object_fifo("in", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]])
以下の図は、タイルとObject FIFOリソースがどこに配置されるかについて仮定を立てないof_inの論理ビューを表しています:

「主要なObject FIFOパターン」セクションで説明するように、Object FIFOは複数のコンシューマタイルを持つことができ、これはソースタイルからすべてのコンシューマタイルへのブロードキャスト接続を記述します。そのため、consumerTiles入力は単一のタイルまたはタイルの配列のいずれかになります。これはproducerTile入力には当てはまりません。現在、Object FIFOは複数のプロデューサをサポートしていません。
Object FIFOのオブジェクトへのアクセス
Object FIFOは、それに登録されたプロデューサおよびコンシューマプロセスによってアクセスできます。プロセスがオブジェクトにアクセスする前に、Object FIFOからそれらを取得する必要があります。これは、Object FIFOが、2つのプロセスが同時に同じオブジェクトにアクセスできないことを保証するために、ターゲットハードウェアアーキテクチャで利用可能な同期メカニズムを活用する同期通信プリミティブであるためです。プロセスがオブジェクトの使用を終え、それ以上必要がなくなったら、別のプロセスがそれを取得してアクセスできるように解放する必要があります。プロデューサまたはコンシューマプロセスがObject FIFOからオブジェクトを取得および解放するパターンは、「アクセスパターン」と呼ばれます。取得パターンと解放パターンを具体的に参照することもできます。
_acquire()関数は、Object FIFOから1つまたは複数のオブジェクトを取得するために使用されます:
def _acquire(
self,
port: ObjectFifoPort,
num_elem: int,
)
取得された要素の数を表すnum_elem入力に基づいて、関数はオブジェクトを直接返すか、オブジェクトの配列を返します。port入力については、このセクションで後述します。
Object FIFOは順序付けられたプリミティブであり、APIは各プロセスについて、取得および解放した数に基づいて、取得時に次にアクセスできるオブジェクトを追跡します。具体的には、プロセスが初めてオブジェクトを取得すると、Object FIFOの最初のオブジェクトにアクセスでき、それを解放して新しいものを取得すると、2番目のオブジェクトにアクセスでき、最後のオブジェクトまで続き、その後、順序は最初のものから再び始まります。複数のオブジェクトを取得し、返された配列でそれらにアクセスする場合、インデックス0のオブジェクトは常に、そのプロセスがアクセスできる最も古いオブジェクトになります。これは、そのObject FIFOのプール内の最初のオブジェクトではない可能性があります。
_release()関数は、1つまたは複数のオブジェクトを解放するために使用されます:
def _release(
self,
port: ObjectFifoPort,
num_elem: int,
)
プロセスは、取得したオブジェクトの1つ、一部、またはすべてを解放できます。解放関数は、取得された順序で最も古いものから最も新しいものへオブジェクトを解放します。プロセスが取得したすべてのオブジェクトを解放しない場合、次にオブジェクトを取得するときに、最も古いオブジェクトは解放されなかったものになります。この機能は、Object FIFOプリミティブを通じてスライディングウィンドウの動作を実現することを目的としています。これについては、「主要なObject FIFOパターン」セクションで詳しく説明します。
Object FIFOのオブジェクトを取得する際に注意すべき重要な点は、以前の取得から解放されていないオブジェクトも最新の取得呼び出しによって返されることです。解放されていないオブジェクトは、プロセスが以前の取得から解放されていないオブジェクトへの単独アクセス権をすでに持つように、内部で使用される同期メカニズムがすでに設定されているという意味で再取得されません。そのため、間に解放呼び出しがない場合、連続して2回の取得呼び出しを行うと、両方の取得呼び出しで同じオブジェクトが返されます。この決定は、取得関数呼び出し間のオブジェクト解放の理解を容易にし、Object FIFOプリミティブを通じた適切な変換を確保するために行われました。この動作のコード例は、「主要なObject FIFOパターン」セクションで入手できます。
取得関数と解放関数の両方のport入力は、そのプロセスがObject FIFO抽象化の低レベルでプロデューサプロセスかコンシューマプロセスかを表し、基盤となる同期メカニズムを適切に活用するためのObject FIFO変換の重要な指標です。その値はObjectFifoPort.ProduceまたはObjectFifoPort.Consumeのいずれかです。ただし、注意すべき重要な点は、プロデューサとコンシューマという用語は、主に人間のユーザーがどのプロセスがデータ移動のどの端にあるかを追跡するための論理的な参照を提供する手段として使用されますが、そのプロセスの動作を制限するものではないということです。つまり、プロデューサプロセスは単にオブジェクトを読み取るためにアクセスすることができ、それを変更する必要はありません。
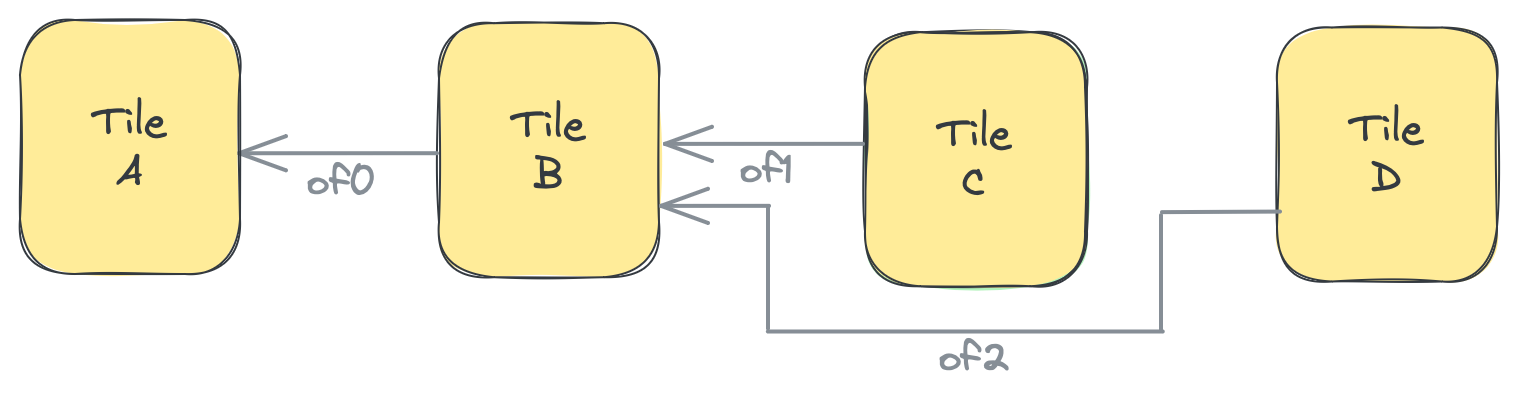
以下は、前のセクションで初期化したof_inというObject FIFOのオブジェクトを反復処理する2つのプロセスの例です。1つはプロデューサハンドルにアクセスし、もう1つはコンシューマハンドルにアクセスします。これを行うために、プロデューサプロセスはof_inの深さに等しい3回の反復のループを実行し、各反復中にof_inから1つのオブジェクトを取得し、取得したオブジェクトに対してtest_func関数を呼び出し、オブジェクトを解放します。コンシューマプロセスは1回だけ実行され、of_inから3つのオブジェクトすべてを一度に取得し、elems配列に格納します。そこから、任意の順序で各オブジェクトに個別にアクセスできます。その後、test_func2関数を3回呼び出し、各呼び出しで取得したオブジェクトの1つを入力として与え、最後に3つのオブジェクトすべてを解放します。
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(line_type, name="in", depth=3)
# 外部バイナリカーネル定義
# ...
# コアが実行するタスク
def core_fn(of_in, test_func):
for _ in range_(3):
elemIn = of_in.acquire(1)
test_func(elemIn, line_size)
of_in.release(1)
def core_fn2(of_in, test_func2):
elems = of_in.acquire(3)
test_func2(elems[0], line_size)
test_func2(elems[1], line_size)
test_func2(elems[2], line_size)
of_in.release(3)
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of_in.prod(), test_fn])
my_worker = Worker(core_fn2, [of_in.cons(), test_fn2])
object_fifoクラスのacquire()およびrelease()関数の低レベルAPIバリアントを以下に示します:
def acquire(self, port, num_elem)
def release(self, port, num_elem)
以下のコードスニペットは、上記と同じ例が明示的に配置されたエンドポイントを持つより低い抽象化レベルでどのように記述されるかを示しています。
A = tile(1, 3)
B = tile(2, 4)
of_in = object_fifo("in", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]])
@core(A)
def core_body():
for _ in range_(3):
elem0 = of_in.acquire(ObjectFifoPort.Produce, 1)
test_func(elem0)
of_in.release(ObjectFifoPort.Produce, 1)
@core(B)
def core_body():
elems = of_in.acquire(ObjectFifoPort.Consume, 3)
test_func2(elems[0])
test_func2(elems[1])
test_func2(elems[2])
of_in.release(ObjectFifoPort.Consume, 3)
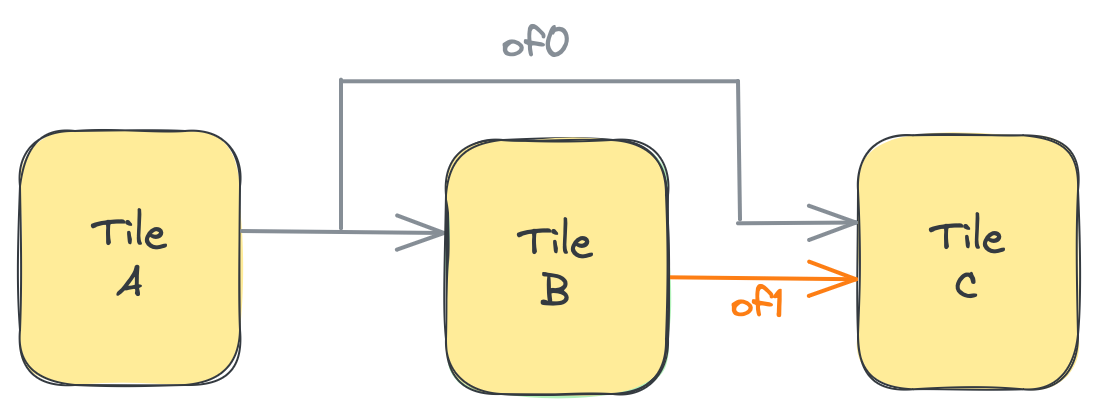
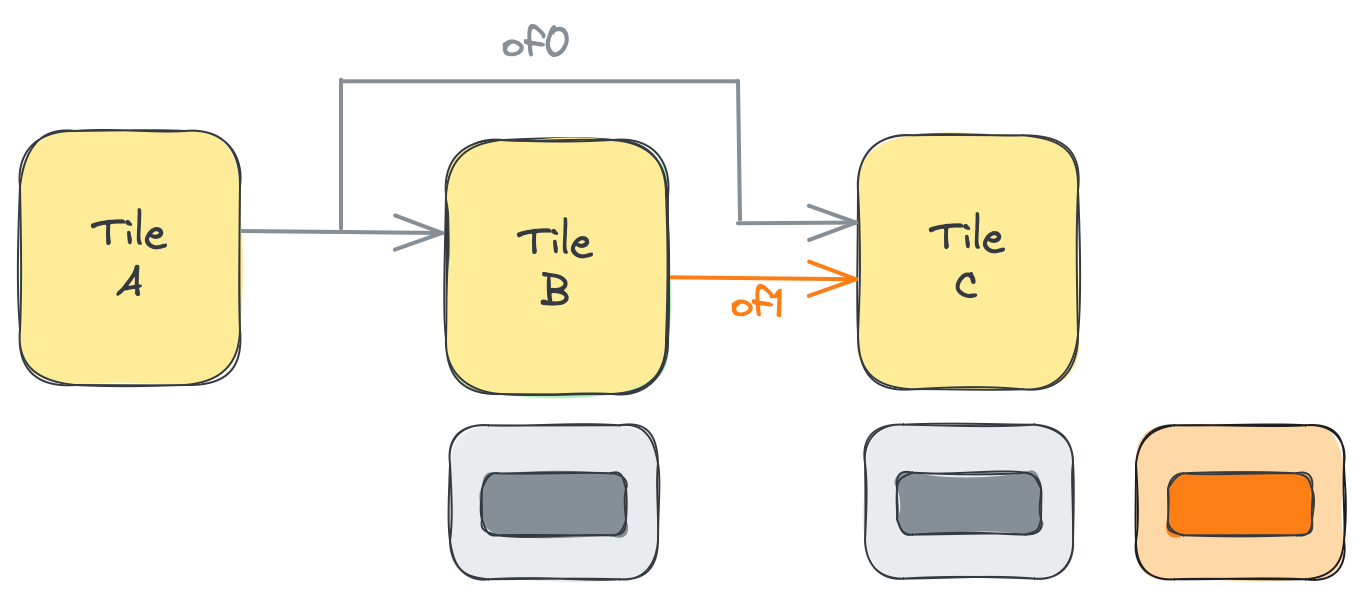
以下の図は、このコードを示しています:4つの図のそれぞれは、実行の1回の反復中のシステムの状態を表しています。最初の3回の反復では、青で描かれたタイルA上のプロデューサプロセスが、of0の要素を1つずつ段階的に取得および解放します。4回目の反復で3番目の要素が解放されると、緑で描かれたタイルB上のコンシューマプロセスが3つのオブジェクトすべてを一度に取得できます。
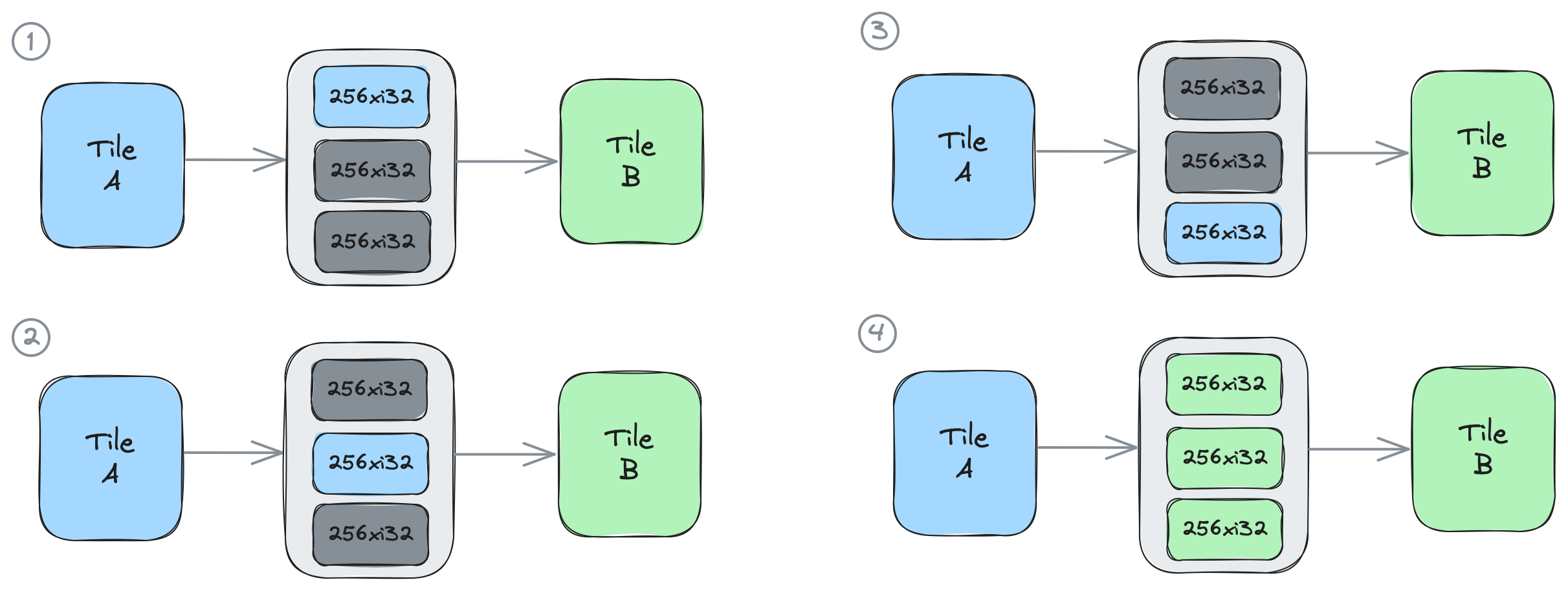
これらの機能を使用する設計の例は、Section 2fの01_single_double_bufferおよび02_external_mem_to_coreで入手できます。
同じプロデューサ/コンシューマを持つObject FIFO
Object FIFOは、同じタイルをプロデューサタイルとコンシューマタイルの両方として作成できます。これは主に、これまでの例で見てきたような異なるタイル上で実行される複数のプロセス間の同期とは対照的に、プロセス自体内で適切な同期を確保するために行われます。共有バッファへのアクセスを持つ2つのカーネルを構成することは、Object FIFOのこのプロパティを活用するアプリケーションです。以下のコードスニペットで示されているように、test_funcとtest_func2はof0を使用して構成されています:
# ObjectFifosを使用したデータフロー
of0 = ObjectFifo(line_type, name="objfifo0", depth=3)
# 外部バイナリカーネル定義
# ...
# コアが実行するタスク
def core_fn(of_in, of_out, test_func, test_func2):
for _ in range_(3):
elemIn = of_in.acquire(1)
test_func(elemIn, line_size)
of_in.release(1)
elemOut = of_out.acquire(1)
test_func2(elemIn, line_size)
of_out.release(1)
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of0.prod(), of0.cons(), test_fn, test_fn2])
以下のコードスニペットは、上記と同じ例が明示的に配置されたエンドポイントを持つより低い抽象化レベルでどのように記述されるかを示しています:
A = tile(1, 3)
of0 = object_fifo("objfifo0", A, A, 3, np.ndarray[(256,), np.dtype[np.int32]])
@core(A)
def core_body():
for _ in range_(3):
elem0 = of0.acquire(ObjectFifoPort.Produce, 1)
test_func(elem0)
of0.release(ObjectFifoPort.Produce, 1)
elem1 = of0.acquire(ObjectFifoPort.Consume, 1)
test_func2(elem1)
of0.release(ObjectFifoPort.Consume, 1)
Object FIFO深さを配列として指定
AIEアーキテクチャは、明示的なデータ移動を必要とする空間アーキテクチャです。そのため、Object FIFOの概念的な設計は2つ以上のAIEタイル間の順序付けバッファですが、実際には、その概念的な深さは、メモリ階層の異なるレベルに配置され、異なるタイル上にある可能性のある複数のリソースプールに分散されています。
Object FIFOの深さのより詳細でありながら抽象的なビューは、プロデューサと各コンシューマが、Object FIFOによって記述されるデータ移動に関してデータを送受信するために使用できる独自の作業リソースプールをローカルメモリモジュールで利用できるというものです。Object FIFOプリミティブとその変換は通常、これらのプールの深さを、結果の動作が概念的な深さと一致するように割り当てます。
ただし、ユーザーはこれらのプールの深さを手動で選択する可能性があります。この機能が利用可能なのは、Object FIFOプリミティブがAIE配列全体でのデータ移動の統一表現を提供しようとする一方で、パフォーマンスプログラマーがそれをより細かく制御するためのツールを提供することも目的としているためです。この機能は、Object FIFO抽象化の明示的に配置されたレベルで利用できます。
たとえば、以下のコードスニペットでは、of0はプロデューサAとコンシューマB間のデータ移動を記述しています:
A = tile(1, 3)
B = tile(2, 4)
of0 = object_fifo("objfifo0", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]])
Object FIFOの概念的な深さは3です。この深さの選択の背後にある理由は、2つのアクターの取得および解放パターンを見ることで理解できます:
@core(A)
def core_body():
for _ in range_(9):
elem0 = of0.acquire(ObjectFifoPort.Produce, 1)
produce_func(elem0)
of0.release(ObjectFifoPort.Produce, 1)
@core(B)
def core_body():
for _ in range_(9):
elems = of0.acquire(ObjectFifoPort.Consume, 2)
consume_func(elems[0], elems[1])
of0.release(ObjectFifoPort.Consume, 2)
各反復:
- プロデューサAは、プロデュースする1つのオブジェクトを取得し、カーネル関数
produce_funcを呼び出してBが消費する新しいデータを格納し、オブジェクトを解放します。 - コンシューマBは、消費する2つのオブジェクトを取得し、データを読み取ってカーネル関数
consume_funcを適用し、両方のオブジェクトを解放します。
このシステムがデッドロックせずに機能するには、概念的な深さ2で十分でした。ただし、深さが3の場合、AとBは同時に実行できます。つまり、Bが2つのオブジェクトを消費してカーネル関数を適用している間、Aは同時にプロデュースできる1つのオブジェクトが利用可能です。
深さの配列を使用したこの概念的な深さ3の同等物は次のとおりです:
of0 = object_fifo("objfifo0", A, B, [2, 3], np.ndarray[(256,), np.dtype[np.int32]])
ここで、2はプロデューサAにローカルで利用可能なリソースの数であり、3はコンシューマBで利用可能な数です。
注意: 正しい変換のために、この機能は、Object FIFOのプロデューサとコンシューマが異なるタイル上で実行されている状況で使用する必要があります。
異なるObject FIFOのアクター用のリソースプールの深さを指定する機能は、複数のObject FIFOを使用する場合に発生する可能性のある特定の依存関係をサポートするために使用され、「主要なObject FIFOパターン」セクションでさらに説明されています。
Object FIFOの追加入力
これまで、このセクションではObject FIFOの必須入力を紹介してきました。ガイドのこの部分では、残りの入力に焦点を当て、Object FIFO変換をガイドする上でどのような役割を果たすかを説明します。
class object_fifo:
def __init__(
...
initValues=None,
via_DMA=None,
plio=None,
disable_synchronization=None,
)
念のため、dimensionsToStreamおよびdimensionsFromStreamPerConsumer入力には専用のセクションがあります(section-2cのデータレイアウト変換を参照)。
Object FIFOのインスタンス化時に、initValues入力に初期値の配列を提供することで、そのオブジェクトを初期化することができます。これは、以下のコードスニペットで示されており、of0の2つのオブジェクトがそれぞれ配列[0, 1, 2, 3]と[4, 5, 6, 7]で初期化されています:
A = tile(1, 3)
B = tile(2, 4)
of0 = object_fifo(
"of0",
A,
B,
2,
np.ndarray[(2, 2), np.dtype[np.int32]],
initValues=[
np.arange(4, dtype=np.int32),
np.arange(4, 8, dtype=np.int32)
],
)
初期値はObject FIFOのdatatypeと一致する必要があることに注意することが重要です。このプロセスを支援するために、Object FIFO APIは指定された初期値の形状を変更しようとします。上記の例では、初期値は<2x2xi32>データ型と一致するように[[0, 1], [2, 3]]および[[4, 5], [6, 7]]として形状が変更されます。
Object FIFOが作成時に初期化されると、基盤となる同期メカニズムは、コンシューマが読み取る時間を持つ前に初期値が新しいデータで上書きされないように、Object FIFOのプロデューサがすぐに新しいオブジェクトを取得できないように設定されます。
Object FIFOの残りの入力は高度なトピックと見なされ、このガイドの残りの部分を理解するために必要ありません。
Object FIFOのvia_DMA入力は、主にデバッグまたはベンチマークの目的で使用されます。変換されたデータ移動設定がタイルのDirect Memory Access(DMA)チャネルを使用することを強制するために、trueに設定できます。DMAについては、以下の高度なトピックセクションでさらに説明します。Object FIFO変換とvia_DMA属性がそれにどのように影響するかについての詳細は、ローカルメモリまたはDMAを使用した通信に関するMLIR-AIEチュートリアルのセクションを参照してください。
plio入力は、Object FIFO変換にデータ移動設定に関する情報を提供するために使用されます。Object FIFOが変換されると、そのタイル間で確立される通信フローは専用のplioポートを介して配線されます。
Object FIFOは、オブジェクトに専用の同期リソースを結合して、一度に1つのアクターのみがそれらにアクセスできるようにし、データの破損を防ぐ同期データ移動プリミティブです。これらの同期リソースは実行時に追加のサイクルを消費するため、必要ない場合は削除することが望ましい場合があります。そのような状況の1つの例は、同じプロデューサ/コンシューマを持つObject FIFOを使用する場合です。コア内のアクセスは順次実行されるためです。Object FIFOのdisable_synchronization入力はまさにその目的を果たし、trueに設定されると、オブジェクトに結合された同期リソースはありません。
Object FIFOコンパイラフラグ
Object FIFO変換パスは、aiecc.pyコンパイラパイプラインを通じて利用可能な2つのコンパイラフラグを提供します。これらのフラグにより、ユーザーは、オブジェクトアクセス用に生成されるWorkerコードの複雑さと、Object FIFOで表されるデータ移動にどのハードウェア機能が活用されるかに影響を与える変換の決定の一部を駆動できます。
これらのフラグは次のとおりです:
dynamic-objFifos: 有効にすると、コンパイラはMLIRscf.index_switch操作を生成して、Workerの実行中に取得されたオブジェクトと解放されたオブジェクトの数を追跡します。この機能は、Workerの実行の反復間でこれらの数が異なる場合に特に役立ちます。これにより、アクセスされたオブジェクトの数の動的な実行時解決が可能になります。packet-sw-objFifos: 有効にすると、コンパイラは(デフォルトの回路交換フローの代わりに)パケット交換フローを使用してAXIストリームデータ移動を設定します。この機能は開発の初期段階にあり、現在、Worker間およびWorkerと外部メモリ間のObject FIFOのみをサポートしています。
これらのフラグは、次のようにaiecc.pyへの呼び出し、またはObject FIFO変換パスへの直接呼び出しと組み合わせることができます:
aiecc.py --packet-sw-objFifos <MLIRデザインファイルへのパス>
aie-opt --aie-objectFifo-stateful-transform="packet-sw-objFifos" <MLIRデザインファイルへのパス>
高度なトピック:オブジェクトの指向的割り当て
Object FIFO変換は、AIE配列のメモリ内でメモリ要素を割り当てる場所について決定を下します。場合によっては、これらの割り当てに使用する特定のAIEタイルをターゲットにすることが望ましい場合があります。これらのケースでは、allocate()関数を次のように使用できます:
A = tile(1, 2)
B = tile(1, 3)
of_in = object_fifo("in", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]])
of_in.allocate(B)
注意: 現在、Object FIFOのプロデューサとコンシューマの両方が、ターゲットAIEタイルへの直接共有メモリアクセスを持つ必要があります。
高度なトピック:Direct Memory Accessチャネル
以下のトピックは、このガイドの残りの部分を理解するために必要ありません。
ガイドのこの部分では、AIEハードウェアのいくつかの低レベル概念を紹介し、各タイル上の個々のリソースプールとその深さの背後にある理由を詳しく見ていきます。
AIE配列の各タイルには、専用のDirect Memory Access(DMA)があります。DMAは、タイルのメモリモジュールからAXIストリーム相互接続へ、またはストリームからメモリモジュールへデータを移動する責任があります。コンピュートタイルの場合、コンピュートコアとタイルのDMAの両方がタイルのメモリモジュールにアクセスできます。このため、データの破損を避けるために、コンピュートコアとDMAが相互にデータが読み取りまたは書き込み可能であることを信号できるようにする同期メカニズムが必要です。これは、プロデューサとコンシューマがオブジェクトにアクセスする前にまずオブジェクトを取得し、他の当事者が取得できるように完了したら解放する必要があるObject FIFOの概念と非常に似ています。
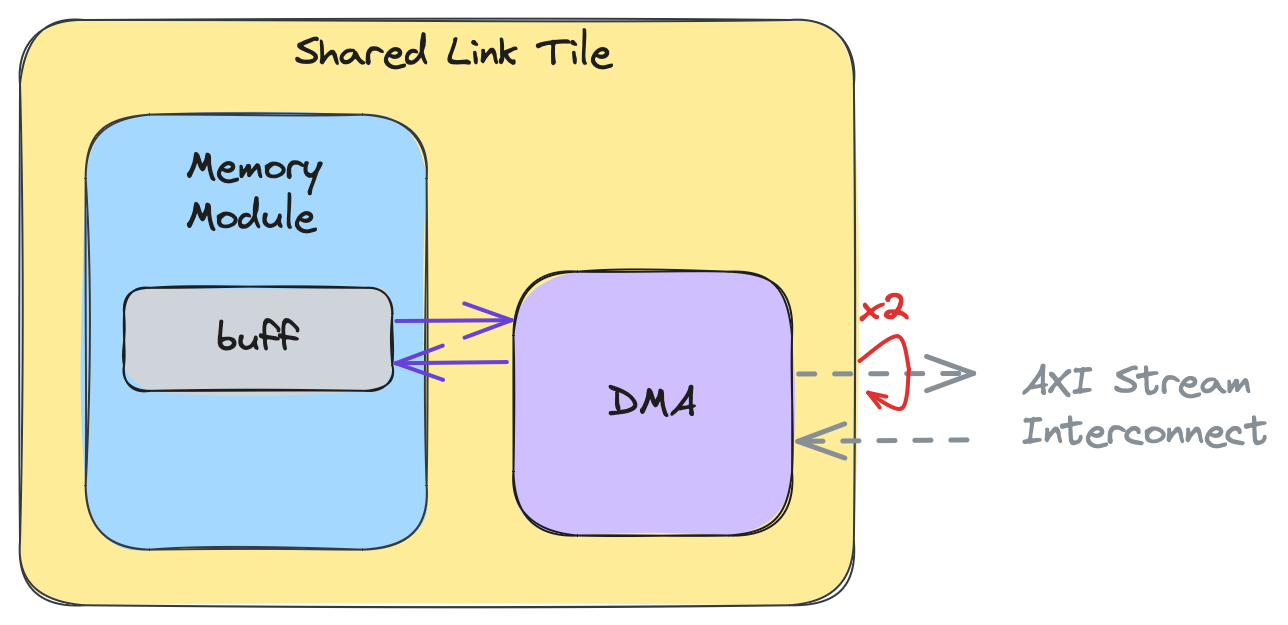
以下の図は、コンピュートタイルの高レベルビューを示しており、コンピュートコアとDMAの両方がローカルメモリモジュール内の場所buffにデータを読み書きしています:
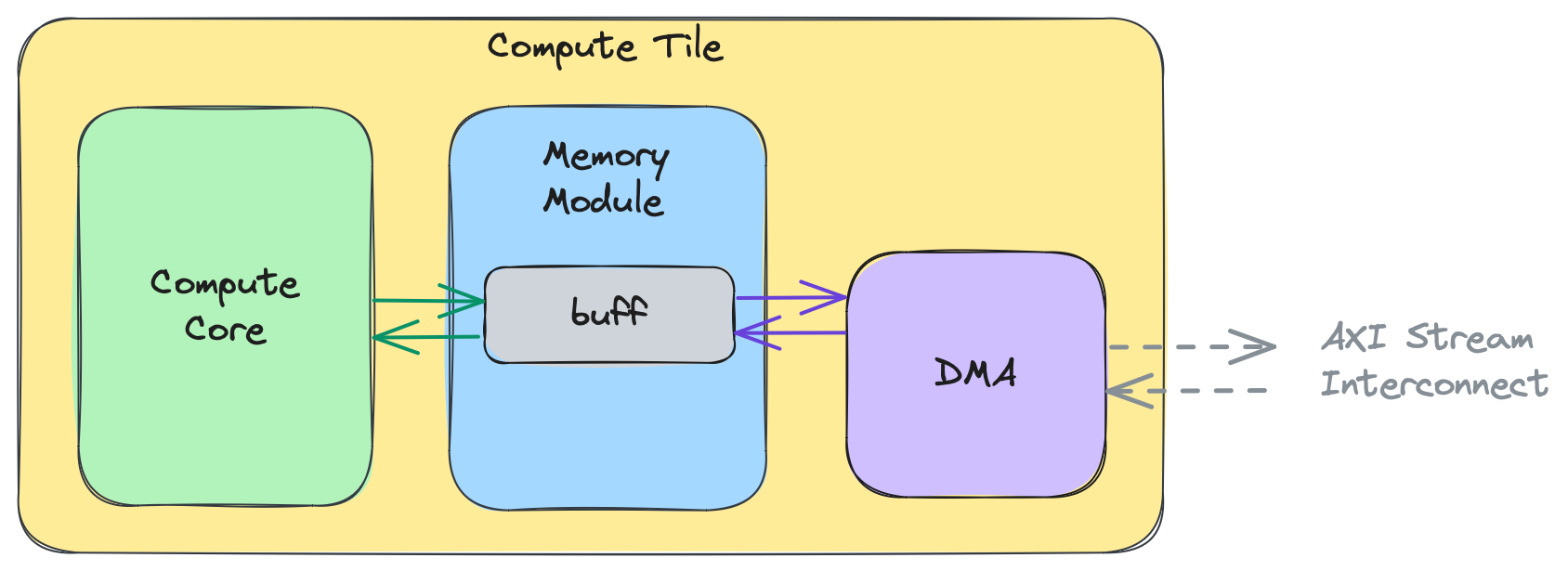
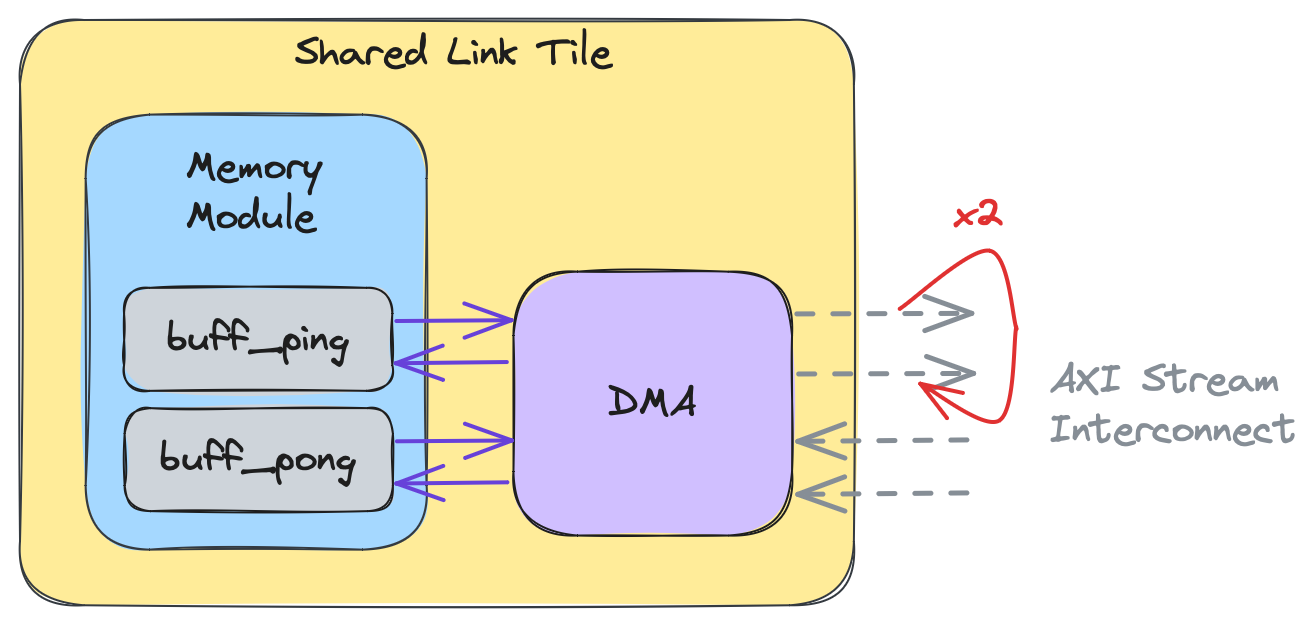
この高レベルビューの意図は、コアが同時にメモリバッファにアクセスしている間、DMAがメモリバッファと対話できることを示すことです。DMAはバッファからAXIストリームにデータを送信し、ストリームからデータを受信してコアが処理しているバッファに書き込むことができます。この並行性はデータ競合につながる可能性があるため、単一のバッファの代わりにピンポンバッファ(ダブルバッファとも呼ばれます)がよく使用されます。これは以下の図で示されており、buffがbuff_pingとbuff_pongに拡張されています:
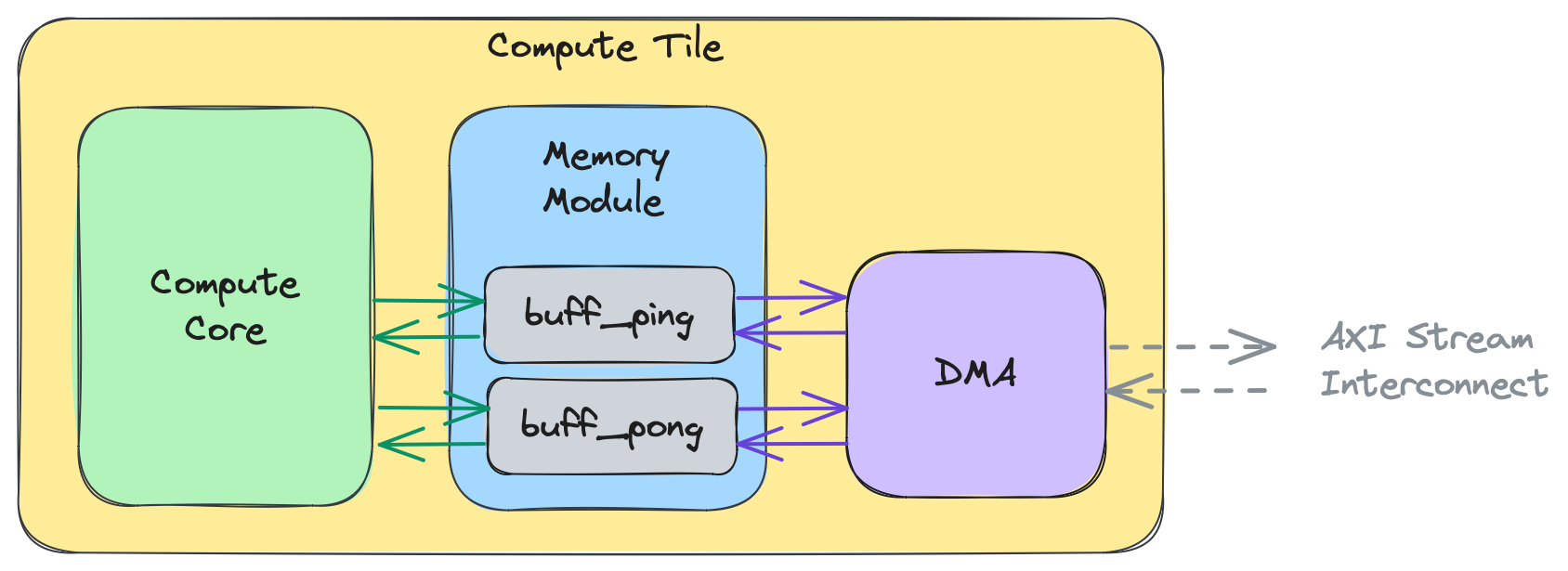
注意: Object FIFOプリミティブを使用せずにDMAを直接設定して、タイル間のデータ移動をセットアップすることができます。これについてはSection 2gで説明します。
演習
-
前のサブセクションでは、
of0の概念的な深さ3を深さの配列[2, 3]として表すことができると説明しました。DMAに関する高度な知識があれば、これらがデッドロックせずに設計を実行するために必要な最小の深さだと思いますか?答えを見る
いいえ。プロデューサAの場合、単一のオブジェクトのみを割り当てる必要があります。その場合、コンピュートコアとDMAは、他の当事者がそれぞれ計算またはデータを移動している間待機する必要があります。これはコンシューマBでも同様で、深さ2で十分です。したがって、デッドロックせずに設計を実行するための最小の深さは[1, 2]です。 -
深さ
[2, 3]は、AとB両方のコンピュートコアがDMAと同時に実行するのに十分だと思いますか?答えを見る
プロデューサAは、DMAと同時に機能するためにピンポンバッファを必要とします。同様に、コンシューマBは、Bが計算している間にDMAが新しいデータを書き込むことができる2つの追加オブジェクトを必要とします。更新された深さは[2, 4]です。
Section 2b - Object FIFOの主要パターン
Object FIFOプリミティブは、いくつかのデータ移動パターンをサポートしています。このセクションでは、現在サポートされている4つのパターンをそれぞれ説明し、各パターンを実演する詳細な実践的コード例へのリンクを提供します。
概要
Object FIFOは、柔軟なデータ移動パターンをサポートしており、単純な1対1の接続から複雑なマルチキャスト、データ分散、集約まで対応します。このセクションでは、4つの主要なパターンを紹介します。
1. 再利用パターン(Reuse Pattern)
概念:
Object FIFO内の解放されていないオブジェクトを再利用します。
用途:
- スライディングウィンドウ処理
- 畳み込み演算でのデータ再利用
- 時系列データの重複アクセス
特徴:
- 以前に取得したがまだ解放していないオブジェクトに再度アクセス可能
- メモリ効率的なデータアクセスパターン
- 明示的なコピー操作なしでデータ共有
詳細な実装例: 01_Reuse/
2. ブロードキャストパターン(Broadcast Pattern)
概念:
単一のプロデューサソースから複数のコンシューマ宛先へデータをブロードキャストします。
用途:
- 同じデータを複数のコアで並列処理
- ニューラルネットワークの重みの配信
- 複数のパイプラインへの同時データ供給
特徴:
- 1つのプロデューサ、複数のコンシューマ
- すべてのコンシューマが同一のデータを受信
- 効率的な帯域幅使用
実装例のイメージ:
プロデューサ → Object FIFO → コンシューマ1
├→ コンシューマ2
└→ コンシューマ3
詳細な実装例: 02_Broadcast/
3. 暗黙的コピーパターン(Implicit Copy): 分散(Distribute)と結合(Join)
このパターンでは、Object FIFO間でのデータの暗黙的コピーをサポートし、以下の機能を提供します:
- Object FIFO間の暗黙的コピー: あるObject FIFOから別のObject FIFOへデータを自動的に転送
- 分散(Distribute): 入力データの異なる部分を複数のコンシューマに配布
- 結合(Join): 異なるプロデューサからの出力をより大きなデータテンソルに結合
分散(Distribute)
概念:
入力データセグメントを複数のコンシューマ間で分割します。
用途:
- データ並列処理
- 大きなデータセットの分割処理
- マルチコアスケーリング
実装例のイメージ:
プロデューサ → Object FIFO → [0:N/3] → コンシューマ1
├→ [N/3:2N/3] → コンシューマ2
└→ [2N/3:N] → コンシューマ3
結合(Join)
概念:
複数のプロデューサからの出力を統合されたデータ構造に集約します。
用途:
- 並列処理結果の集約
- マルチコアからの出力統合
- パイプライン結果の結合
実装例のイメージ:
プロデューサ1 → Object FIFO → [0:N/3] →
プロデューサ2 → Object FIFO → [N/3:2N/3] → 結合 → 出力
プロデューサ3 → Object FIFO → [2N/3:N] →
詳細な実装例: 03_Implicit_Copy/
4. リピートパターン(Repeat Pattern)
概念:
Object FIFO Link機能を活用して、プロデューサからのデータを繰り返します。
用途:
- 同じデータの繰り返し処理
- 反復アルゴリズム
- データの再利用が必要な処理
特徴:
- データの効率的な再利用
- 追加のメモリコピー不要
- パイプライン処理での活用
詳細な実装例: 04_Repeat/
パターンの組み合わせ
これらのパターンは単独でも、組み合わせても使用できます。例えば:
- ブロードキャスト + 結合: 複数のコアで並列処理して結果を集約
- 分散 + 再利用: データを分割して各コアでスライディングウィンドウ処理
- リピート + ブロードキャスト: データを複数回、複数のコアで処理
実践的な例
各パターンには、リンクされた実践的なコード例が用意されています。これらの例を参照することで、パターンの具体的な実装方法を理解できます。
詳細な実装例については、公式のSection 2bドキュメントを参照してください。
注意: 各パターンの完全なコード例と詳細な説明については、公式ドキュメントを参照してください。
Object FIFO再利用パターン
前のセクションで、Object FIFOのacquireおよびrelease関数を組み合わせることで、データ再利用を伴うスライディングウィンドウの動作を実現できることが述べられました。具体的には、この通信パターンは、Object FIFOのプロデューサまたはコンシューマが、以前にacquireしたオブジェクトよりも少ない数のオブジェクトをreleaseする場合に発生します。Object FIFOからのacquireはデータを破壊しないため、releaseされていないオブジェクトはデータの新しいコピーを必要とせずに使用し続けることができます。
重要な点として、新しいacquire関数を呼び出すたびに、プロセスがアクセスできる新しいオブジェクトまたはオブジェクトの配列が返されますが、これには以前のacquire呼び出しからのreleaseされていないオブジェクトが含まれます。Object FIFOプリミティブを通じた適切な低レベル化を保証するために、プロセスは常に最新のacquire呼び出しの結果を使用してreleaseされていないオブジェクトにアクセスする必要があります。
以下の例では、of0は3つのオブジェクト(object0、object1、object2)の深さで作成されています。コンシューマWorkerで実行されるプロセスは次の図に示され、以下で詳しく説明されます。
of0 = ObjectFifo(line_type, name="objfifo0", depth=3) # 3つのオブジェクト: object0, object1, object2
# 外部バイナリカーネル定義
test_fn2 = Kernel(
"test_func2",
"test_func2.cc.o",
[line_type, line_type, np.int32],
)
# コアが実行するタスク
def core_fn(of_in, test_func2):
### 状況1
elems = of_in.acquire(2) # object0とobject1をacquire
test_func2(elems[0], elems[1], line_size)
of_in.release(1) # object0をrelease
### 状況2
elems_2 = of_in.acquire(2) # object2をacquire; object1は以前にacquireされていた
test_func2(elems_2[0], elems_2[1], line_size)
of_in.release(1) # object1をrelease
### 状況3
elems_3 = of_in.acquire(2) # object0をacquire; object2は以前にacquireされていた
test_func2(elems_3[0], elems_3[1], line_size)
of_in.release(1) # object2をrelease
### 状況4
elems_4 = of_in.acquire(2) # object1をacquire; object0は以前にacquireされていた
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of0.cons(), test_fn2])
以下の図は、マークされた状況1から4のそれぞれにおけるシステムの状態を表しています。ここで、コンシューマWorkerはTile Bにマッピングされています(Tile Aは、上記のコードの一部ではない暗黙のプロデューサプロセスを実行しています):
- コンシューマBは最初に、変数
elemsでof0から2つの要素をacquireします。これがBが初めてacquireするため、object0とobject1にアクセスできます。次に、Bは2つのacquireされた要素に対してtest_func2を適用します。最後に、Bは1つのオブジェクト(最も古くacquireされたもの)をreleaseし、object1を保持します。 - Bは変数
elems_2で2つの要素をacquireします。これで、object1(ステップ1の最初のacquire呼び出しからacquireされたまま)と、新しくacquireされたobject2にアクセスできます。Bは再び関数を適用し、その後1つのオブジェクトのみをreleaseし、object2を保持します。 - Bは
elems_3で2つのオブジェクトをacquireし、object2とobject0にアクセスできます。Bは1つのオブジェクトをreleaseし、object0を保持します。 - Bは
elems_4で2つのオブジェクトをacquireし、object0とobject1にアクセスできます。これにより、ステップ1の開始時の状況に戻ります。
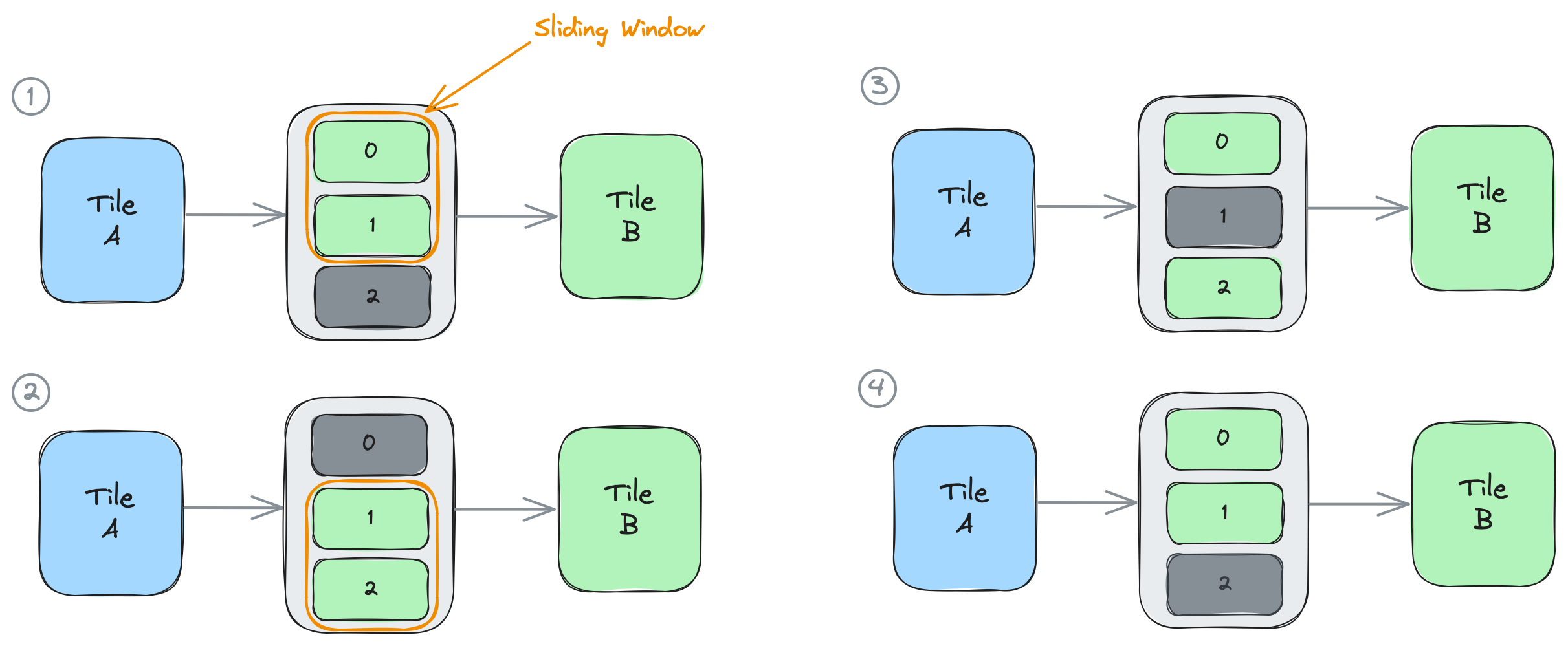
上記の状況は、4回の反復を持つforループに融合できます。コンシューマプロセスは、各反復でacquireした要素よりも1つ少ない要素を継続的にreleaseすることで、各反復で1つずつスライドする2つのオブジェクトのスライディングウィンドウの動作を実装しています:
# ObjectFifosを使用したデータフロー
of0 = ObjectFifo(line_type, name="objfifo0", depth=3) # 3つのオブジェクト: object0, object1, object2
# 外部バイナリカーネル定義
test_fn2 = Kernel(
"test_func2",
"test_func2.cc.o",
[line_type, line_type, np.int32],
)
# コアが実行するタスク
def core_fn(of_in, test_func2):
for _ in range_(4):
elems = of_in.acquire(2) # object0とobject1をacquire
test_func2(elems[0], elems[1], line_size)
of_in.release(1) # object0をrelease
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of0.cons(), test_fn2])
注意: より詳細な情報については、公式ドキュメントを参照してください。
Object FIFOブロードキャストパターン
導入セクションで説明したように、Object FIFOは1つまたは複数のコンシューマを持つことができます。最高レベルの抽象化では、cons()を呼び出すたびに、そのコンシューマ用の新しいObjectFifoHandleが返されます。明示的に配置された抽象化レベルでは、consumerTiles入力は単一のタイルまたはタイルの配列のいずれかになります。入力がタイルの配列として指定されている場合、これは単一のプロデューサタイルから複数のコンシューマタイルへのブロードキャスト通信を作成します。プロデューサタイルのメモリモジュールからのデータは、AXIストリームインターコネクトを介して各コンシューマタイルのメモリモジュールに送信されます。AXIストリームインターコネクトは、実行時間が異なるコンシューマからのバックプレッシャーを処理します。AXIストリームは、各コンシューマに送信される前にデータの低レベルコピーが作成される場所でもあります。ブロードキャストを実現するために、低レベル化ではプロデューサタイルの1つの出力ポートを使用してすべてのコンシューマタイルへの接続を確立します。以下の図に示すとおりです:
Object FIFOのオブジェクトがプロデューサおよびコンシューマタイルのDMAを介してAXIストリームを通じて転送される方法の詳細については、mlir-aieのチュートリアルを参照してください。ただし、Object FIFO APIを理解または使用するために必要ではありません。
以下は、前の図に示されているObject FIFO of0の例です。深さは3で、1つのWorkerがプロデューサプロセスを実行し、3つのWorkerがコンシューマプロセスを実行します:
# ObjectFifosを使用したデータフロー
of0 = ObjectFifo(line_type, name="objfifo0", depth=3)
# 外部バイナリカーネル定義
# ...
# コアが実行するタスク
# ...
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of0.prod(), test_fn])
my_worker2 = Worker(core_fn2, [of0.cons(), test_fn2])
my_worker3 = Worker(core_fn3, [of0.cons(), test_fn2])
my_worker4 = Worker(core_fn4, [of0.cons(), test_fn2])
次のコードスニペットは、上記と同じ例を、プロデューサWorkerがタイルAにマッピングされ、コンシューマWorkerがタイルB、C、Dにマッピングされている、エンドポイントが明示的に配置されたより低レベルの抽象化でどのように記述されるかを示しています:
A = tile(1, 1)
B = tile(1, 3)
C = tile(2, 3)
D = tile(3, 3)
of0 = object_fifo("objfifo0", A, [B, C, D], 3, np.ndarray[(256,), np.dtype[np.int32]])
スキップ接続を伴うブロードキャスト
明示的に配置された抽象化レベルでは、Object FIFOのdepth入力も整数の配列として指定できます。これは、Object FIFOにアクセスするときに各タイル(プロデューサタイルと各コンシューマタイル)が利用できるオブジェクトの数を記述します。前の例では、4つのタイルのそれぞれが、of_0のデータ移動を実行するために利用可能な3つのオブジェクトのリソースプールを持っています。
注意: Object FIFOプリミティブのこの機能は、ブロードキャストのためにデータ移動が確立されたときにハードウェアレベルで実際に何が起こっているかを公開します。Object FIFOのオブジェクトプールは単一の構造ではなく、データ移動に関与する各タイルのメモリモジュールに割り当てられたオブジェクトのいくつかのプールで構成されています。
depthを整数の配列として指定すると、ユーザーは各個別タイルのプールのサイズを設定するための完全な制御を得ることができます。詳細については、セクション2aを参照してください。
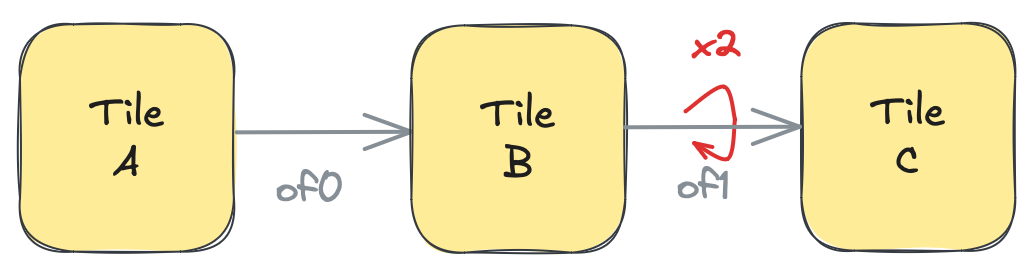
この機能の主な利点は、以下の例に示すような状況で明らかになります。これをスキップ接続を伴うブロードキャストと呼びます。以下の例では、2つのObject FIFOが作成されています:of0はプロデューサタイルAからコンシューマタイルBおよびCへのブロードキャストであり、of1はプロデューサタイルBからコンシューマタイルCへの1対1のデータ移動です。A → B → Cチェーンでbを飛び越してA → Cを接続するため、of0をスキップ接続と呼びます。
A = tile(1, 3)
B = tile(2, 3)
C = tile(2, 4)
of0 = object_fifo("objfifo0", A, [B, C], 1, np.ndarray[(256,), np.dtype[np.int32]])
of1 = object_fifo("objfifo1", B, C, 1, np.ndarray[(256,), np.dtype[np.int32]])
この状況は、以下の図のように見ることができます:
ここで、of0の2つのコンシューマで実行されているプロセスが以下のコードスニペットのようであると仮定します。
@core(B)
def core_body():
elem0 = of0.acquire(ObjectFifoPort.Consume, 1)
elem1 = of1.acquire(ObjectFifoPort.Produce, 1)
test_func2(elem0, elem1)
of0.release(ObjectFifoPort.Consume, 1)
of1.release(ObjectFifoPort.Produce, 1)
@core(C)
def core_body():
elem0 = of0.acquire(ObjectFifoPort.Consume, 1)
elem1 = of1.acquire(ObjectFifoPort.Consume, 1)
test_func2(elem0, elem1)
of0.release(ObjectFifoPort.Consume, 1)
of1.release(ObjectFifoPort.Consume, 1)
Cは実行を進める前にof0とof1の両方から1つのオブジェクトを必要とすることがわかります。ただし、Bもof1のデータを生成する前にof0からオブジェクトを必要とします。CがBを待っているため、2つのタイルはブロードキャスト接続からの消費レートが同じではなく、これによりAの生産レートが影響を受けます。
これをさらに表現するために、コンシューマタイルがそれぞれのObject FIFOに割り当てられたオブジェクトのプールを持っているという、わずかに低レベルの見方をすることができます。簡単にするために、コンシューマが使用するプールのみが表示されています(たとえば、of1の場合、コンシューマタイルC側のプールのみが表示されています)。現在、すべてのプールの深さは1です。
スキップ接続によってAの生産が影響を受けないようにするには、of0のためにCに追加のオブジェクトが必要です。これは、of1を介してBからのデータを待っている間にof0から来るデータのバッファリングスペースとして使用できます。これを実現するために、of0はdepthに整数の配列を使用して作成されます:
of0 = object_fifo("objfifo0", A, [B, C], [1, 1, 2], np.ndarray[(256,), np.dtype[np.int32]])
ここで、タイルAとBは元の深さ1を保持し、Cは深さ2のオブジェクトを持つようになりました。この変更は、以下の図のように視覚化できます。タイルCのof0のオブジェクトプールが増加しています:

注意: より詳細な情報については、公式ドキュメントを参照してください。
Object FIFO間の暗黙的コピー:DistributeとJoinパターン
Object FIFOの暗黙的コピー
設計上、Object FIFOはプロデューサとコンシューマ間のデータ移動の構成と、Workerのメモリモジュール上のオブジェクトの割り当ての両方を処理します。1つのObject FIFOから消費されたデータは、2つのFIFO間で共有されるWorkerのコアコードで別のObject FIFOに明示的にコピーできます。これは、以下のコードスニペットに示されており、Workerはof_inからof_outにデータをコピーします:
of_in = ObjectFifo(line_type, name="in")
of_out = ObjectFifo(line_type, name="out")
def core_fn(of_in, of_out, copy_fn):
elem_in = of_in.acquire(1)
elem_out = of_out.acquire(1)
copy_fn(elem_in, elem_out)
of_in.release(1)
out.release(1)
my_worker = Worker(core_fn, [of_in.cons(), of_out.prod(), copy_fn])
ただし、目標がデータを変更せずに単に1つのObject FIFOから別のObject FIFOにコピーすることである場合、上記の方法で行うと、必要以上に多くのオブジェクトを割り当てることになります。つまり、2番目のObject FIFOにコピーされるデータは、最初のObject FIFOですでに利用可能です。さらに、ShimタイルとMemタイルには、コピーを明示的に実行できるコアがありません。
明示的コピーの代わりに、Object FIFO APIはforward()関数(objectfifo.pyで定義)を介して暗黙的コピーを提供します。ここで、コンシューマ型のObjectFifoHandleが新しく構築されたObject FIFOのプロデューサに転送されます:
def forward(
self,
placement: PlacementTile = AnyMemTile,
obj_type: type[np.ndarray] | None = None,
depth: int | None = None,
name: str | None = None,
dims_to_stream: list[Sequence[int]] | None = None,
dims_from_stream: list[Sequence[int]] | None = None,
plio: bool = False,
)
forward()関数は、ユーザーが通常のObject FIFOと同じ入力を追加で指定できる新しいObject FIFOを作成します。placementタイルは暗黙的コピーが実行される場所であり、デフォルトではMemタイルに設定されています。
暗黙的コピーを使用すると、前のコードは次のように記述できます:
of_in = ObjectFifo(line_type, name="in")
of_out = of_in.cons().forward(obj_type=line_type, name="out")
ここで、of_inへのコンシューマObjectFifoHandleがof_outのプロデューサとして転送されます。
この機能は、明示的に配置された抽象化レベルでも使用できます。Object FIFO APIは、object_fifo_linkを介して暗黙的コピーを提供します。これは、クラスコンストラクタ(aie.pyで定義)を使用して初期化できます:
class object_fifo_link(ObjectFifoLinkOp):
def __init__(
self,
fifoIns,
fifoOuts,
srcOffsets=[],
dstOffsets=[],
)
リンクを使用すると、ユーザーはfifoIns入力を介して入力Object FIFOのセットを指定し、fifoOuts入力を介して出力Object FIFOのセットを指定できます。各Object FIFOは、そのnameまたはそのPythonオブジェクトのいずれかを使用して指定できます。両方の入力は、単一のObject FIFOまたはそれらの配列のいずれかになります。リンクが有効であるためには、fifoInsのコンシューマタイルとfifoOutsのプロデューサタイルの間に少なくとも1つの共有タイルが存在する必要があります。これは、データの暗黙的コピーがそのタイルのダイレクトメモリアクセスチャネル(DMA)を使用して行われるためです。
以下は、2つのFIFO of_inとof_outの間に作成されたリンクの例です。ここで、タイルBはそれらの間の共有タイルです:
A = tile(1, 0)
B = tile(1, 1)
C = tile(1, 3)
of_in = object_fifo("in", A, B, 2, np.ndarray[(256,), np.dtype[np.int32]])
of_out = object_fifo("out", B, C, 2, np.ndarray[(256,), np.dtype[np.int32]])
object_fifo_link(of_in, of_out)
fifoInsとfifoOutsで指定されているObject FIFOの数に応じて、2つの異なるデータパターンを実現できます:DistributeまたはJoinです。これらは次の2つのサブセクションで説明されています。現在、両方のパターンを一度に実行することはできません。つまり、fifoInsが配列の場合、fifoOutsは単一のObject FIFOのみであり、その逆も同様です。最高レベルの抽象化では、これらのパターンも利用可能です。
この機能を使用する完全なデザイン例は、セクション2fで利用できます:03_external_mem_to_core_L2。
Distribute
ユーザーは、Object FIFO APIを使用して、プロデューサからのすべてのオブジェクトのデータの一部が複数のコンシューマに分散されるdistributeパターンを記述できます。これはsplit()関数(objectfifo.pyで定義)で実行できます:
def split(
self,
offsets: list[int],
placement: PlacementTile = AnyMemTile,
depths: list[int] | None = None,
obj_types: list[type[np.ndarray]] = None,
names: list[str] | None = None,
dims_to_stream: list[list[Sequence[int]]] | None = None,
dims_from_stream: list[list[Sequence[int]]] | None = None,
plio: bool = False,
) -> list[ObjectFifo]
split()関数は、ユーザーが通常のObject FIFOと同じ入力を追加で指定できる複数のコンシューマObject FIFOを作成します。offsetsは、プロデューサObject FIFOの割り当てられたメモリのどの場所から各コンシューマObject FIFOにデータを送信するかを指定するために使用されます。
以下は、Object FIFOのコンシューマObjectFifoHandleが2つのコンシューマに分割される例です。つまり、デザインで使用されるコアの数です。split()関数には、各コンシューマObject FIFOにデータが送信されるオフセット、そのオブジェクトのデータ型、およびそれらの名前が追加で与えられます。
of0 = ObjectFifo(mem_tile_ty, name="objfifo0")
n_cores = 2
of_offsets = [
(np.prod(np_ndarray_type_get_shape(mem_tile_ty)) // n_cores) * i
for i in range(n_cores)
]
of0_fifos = of0.cons().split(
of_offsets,
obj_types=[aie_tile_ty] * n_cores,
names=[f"objfifo{i}" for i in range(n_cores)],
)
コンシューマ型のObjectFifoHandleのみを分割できます。出力FIFOのobj_typesは入力FIFOよりも小さいサイズである必要があり、出力FIFOのサイズの合計は入力FIFOのobj_typeのサイズと等しくなければなりません。
1つの入力Object FIFOと複数の出力Object FIFOを持つリンクを使用することで、ユーザーはプロデューサタイルからのすべてのオブジェクトのデータの一部が各出力FIFOに分散されるdistributeパターンを記述できます。出力FIFOのdatatypeは入力FIFOよりも小さいサイズである必要があり、出力FIFOのサイズの合計は入力FIFOのdatatypeのサイズと等しくなければなりません。
現在、Object FIFOの低レベル化では、fifoOutsで出力FIFOが指定されている順序を使用して、入力オブジェクトのどの部分が各出力FIFOに行くべきかを知ります。distributeを実現するために、低レベル化では、共有タイルの1つの出力ポートを使用して、以下の図のように出力FIFOごとに接続を確立します:

次のコードスニペットは、上記の図を説明しています。3つのObject FIFOがあります:of0はプロデューサタイルAとコンシューマタイルBを持ち、of1とof2はBをプロデューサタイルとし、それぞれCとDをコンシューマタイルとして持ちます。リンクは、of0からのデータがof1とof2に分散されることを指定します。このリンクでは、BはBのDMAを介して暗黙的データコピーが行われる共有タイルです。また、of1とof2のデータ型がof0の半分であることにも注意できます。これは、of0のオブジェクトの前半がof1に、後半がof2に行くことを意味します。これはリンク内の順序に基づいています。これは、リンクのdstOffsetsオプションを指定することで明示的に設定されます。
A = tile(1, 0)
B = tile(1, 1)
C = tile(1, 3)
D = tile(2, 3)
of0 = object_fifo("objfifo0", A, B, 2, np.ndarray[(256,), np.dtype[np.int32]])
of1 = object_fifo("objfifo1", B, C, 2, np.ndarray[(128,), np.dtype[np.int32]])
of2 = object_fifo("objfifo2", B, D, 2, np.ndarray[(128,), np.dtype[np.int32]])
object_fifo_link(of0, [of1, of2], [], [0, 128])
この機能を使用する完全なデザイン例は、セクション2fで利用できます:04_distribute_L2。
Join
joinパターンは、複数のObject FIFOから受信されたデータが結合され、単一の出力Object FIFOに送信されるdistributeパターンの逆です。これはjoin()関数(objectfifo.pyで定義)で実行できます:
def join(
self,
offsets: list[int],
placement: PlacementTile = AnyMemTile,
depths: list[int] | None = None,
obj_types: list[type[np.ndarray]] = None,
names: list[str] | None = None,
dims_to_stream: list[list[Sequence[int] | None]] | None = None,
dims_from_stream: list[list[Sequence[int] | None]] | None = None,
plio: bool = False,
) -> list[ObjectFifo]
join()関数は、ユーザーが通常のObject FIFOと同じ入力を追加で指定できる複数のプロデューサObject FIFOを作成します。offsetsは、各プロデューサObject FIFOからプロデューサObject FIFOの割り当てられたメモリのどの場所にデータを書き込むかを指定するために使用されます。
以下は、2つのObject FIFOが作成され、of0のプロデューサObjectFifoHandleに結合される例です。join()関数には、各プロデューサObject FIFOによってデータが書き込まれるオフセット、そのオブジェクトのデータ型、およびそれらの名前が追加で与えられます。
of0 = ObjectFifo(mem_tile_ty, name="objfifo0")
n_cores = 2
of_offsets = [
(np.prod(np_ndarray_type_get_shape(mem_tile_ty)) // n_cores) * i
for i in range(n_cores)
]
of0_fifos = of0.prod().join(
of_offsets,
obj_types=[aie_tile_ty] * n_cores,
names=[f"objfifo{i}" for i in range(n_cores)],
)
プロデューサ型のObjectFifoHandleのみを結合できます。入力FIFOのobj_typesは出力FIFOよりも小さいサイズである必要があり、入力FIFOのサイズの合計は出力FIFOのobj_typeのサイズと等しくなければなりません。
リンクを使用したjoinパターンは、複数の入力Object FIFOと単一の出力Object FIFOを持ちます。このパターンを使用すると、ユーザーは複数のソースからの小さな入力を単一の大きな出力データ移動に結合できます。入力FIFOのdatatypeは出力FIFOよりも小さいサイズである必要があり、入力FIFOのサイズの合計は出力FIFOのdatatypeのサイズと等しくなければなりません。
同様に、fifoIns内の順序は、どの入力オブジェクトが出力Object FIFOのより大きなオブジェクトのどの部分を構成するかを指定します。joinを実現するために、低レベル化では、共有タイルの1つの入力ポートを使用して、以下の図のように入力FIFOごとに接続を確立します:
次のコードスニペットは、上記の図を説明しています。3つのObject FIFOがあります:of0はプロデューサタイルBとコンシューマタイルAを持ち、of1とof2はそれぞれCとDをプロデューサタイルとし、Bをコンシューマタイルとして持ちます。リンクは、of1とof2からのデータがof0に結合されることを指定します。このリンクでは、BはBのDMAを介して暗黙的データコピーが行われる共有タイルです。また、of1とof2のデータ型がof0の半分であることにも注意できます。これは、of1からのオブジェクトがof0のオブジェクトの前半になり、of2のオブジェクトが後半になることを意味します。これはリンク内の順序に基づいています。
A = tile(1, 0)
B = tile(1, 1)
C = tile(1, 3)
D = tile(2, 3)
of0 = object_fifo("objfifo0", B, A, 2, np.ndarray[(256,), np.dtype[np.int32]])
of1 = object_fifo("objfifo1", C, B, 2, np.ndarray[(128,), np.dtype[np.int32]])
of2 = object_fifo("objfifo2", D, B, 2, np.ndarray[(128,), np.dtype[np.int32]])
object_fifo_link([of1, of2], of0, [0, 128], [])
これらの機能を使用する完全なデザイン例は、セクション2fで利用できます:05_join_L2。
注意: より詳細な情報については、公式ドキュメントを参照してください。
Object FIFO繰り返しパターン
低レベルのObject FIFOは、プロデューサからのデータを繰り返すことを指定する方法をユーザーに提供します。この機能は、次の構文を使用して利用できます:
of0 = object_fifo("objfifo0", A, B, 2, np.ndarray[(256,), np.dtype[np.int32]])
of0.set_repeat_count(2) # 各オブジェクトのデータはコンシューマCに2回送信されます
この繰り返しは、Object FIFOのプロデューサタイルのダイレクトメモリアクセス(DMA)を使用して実現されます。特に、DMAバッファディスクリプタは、データの破損を避けるために、データが正しいタイミングで処理されることを保証する同期ロジックに依存しています。繰り返しパターンをプログラムするために、プロデューサタイルのバッファディスクリプタに関連する同期ロジックは、データの追加コピーを送信するように生成されます。これらのデータコピーは、以下の図の赤い矢印で示されているように、DMAレベルで作成されるため、追加のメモリが割り当てられることはありません:
DMAとそのバッファディスクリプタの詳細については、セクション2aの高度なトピックおよびセクション2gを参照してください。
繰り返しパターンは同期ロジックに依存しているため、Object FIFOの低レベル化では、利用可能な情報を使用してObject FIFOのacquireおよびrelease操作の値を変更し、DMAが繰り返すことを可能にするために計算タイルによって十分なトークンが生成され、これらのトークンがDMA繰り返し後の最初のacquire操作によって考慮されることを保証します。深さが1より大きいObject FIFOに対してこの調整を行うことは自明ではなく、現在サポートされていません。
この機能の特殊性の1つは、サイズが1より大きいObject FIFOの繰り返しパターンです。Object FIFOに対して生成されるデータ移動は、First In First Outの循環パターンに従い、これが繰り返しと組み合わされると、個々のオブジェクトの繰り返しではなく、循環パターン全体の繰り返しになります。これは、以下の図に示されており、赤い矢印は繰り返し値を表しています:
具体的には、上の図で見られるパターンは次のようになります:buff_ping - buff_pong - buff_ping - buff_pong。ここで、各バッファのデータは各インスタンスで同じままです。
リンクと繰り返し
前のセクションで説明したリンクで繰り返しを使用することもできます。次の構文を使用します:
of0 = object_fifo("objfifo0", A, B, 2, np.ndarray[(256,), np.dtype[np.int32]])
of1 = object_fifo("objfifo1", B, C, 2, np.ndarray[(256,), np.dtype[np.int32]])
object_fifo_link(of0, of1)
of1.set_repeat_count(2) # 各オブジェクトのデータはコンシューマCに2回送信されます
この場合、繰り返しはObject FIFOリンクの共有タイルのダイレクトメモリアクセス(DMA)を使用して実現されます。
特に、繰り返し機能は前のセクションで紹介されたdistributeパターンと組み合わせて使用できます。現在、機能的正しさを保証するために、各distribute宛先に指定された繰り返し値は同じである必要があります。さらに、現在の構文は、同じdistributeパターン内で繰り返しありと繰り返しなしの両方の出力Object FIFOを同時にサポートしていません。以下のコードは、distributeパターンの2つの出力Object FIFOをそれぞれ3回繰り返すように設定する方法を示しています:
of0 = object_fifo("objfifo0", A, B, 2, np.ndarray[(256,), np.dtype[np.int32]])
of1 = object_fifo("objfifo1", B, C, 2, np.ndarray[(256,), np.dtype[np.int32]])
of2 = object_fifo("objfifo2", B, D, 2, np.ndarray[(256,), np.dtype[np.int32]])
object_fifo_link(of0, [of1, of2])
of1.set_repeat_count(3)
of2.set_repeat_count(3)
上記のコードスニペットは、こちらにあるテストの一部です。
注意: より詳細な情報については、公式ドキュメントを参照してください。
Section 2c - データレイアウト変換
このセクションでは、タイルの専用ハードウェアを使用したオンザフライのデータレイアウト変換について説明します。この機能はAIE-MLデバイスでのみ利用可能です。Direct Memory Access(DMA)チャネルは、ローカルメモリモジュールとAXIストリーム相互接続の間でデータを移動し、プログラマブルなn次元アドレス生成スキームを可能にします。
バッファディスクリプタ操作
MLIRでのバッファディスクリプタ操作(AIE_DMABDOp)は、移動するデータ、移動するデータの量、移動元のバッファ内の場所を指定します。この操作のPythonバインディング(dma_bdという名前)は、次のシグネチャを持ちます:
def dma_bd(
buffer,
*,
offset=None,
len=None,
dimensions=None,
bd_id=None,
next_bd_id=None,
loc=None,
ip=None,
)
このセクションでは、特にそのdimensionsパラメータについて詳しく説明します。以下の小さなコードスニペットを使用します。これは、<MLIR_AIE_INSTALL_PATH>/python/aie/dialects/_aie_ops_gen.pyファイルにあります。
データレイアウト変換の形式
データレイアウト変換は、size(サイズ)とstride(ストライド)のペアのタプルとして指定されます。実際のハードウェア実装の制約により、最大次元数は、コンピュートタイルとシムタイルで3、メモリタイルで4に制限されています。以下の形式で指定します:
[<size_2, stride_2>, <size_1, stride_1>, <size_0, stride_0>]
すべてのストライドは要素幅の倍数で表現されます。
注意: 4Bデータ型の場合のみ、最内次元のストライドは設計上1でなければなりません。
ネストループモデル
基本的に、このデータレイアウト変換スキームはネストループとして見ることができ、ループボディ内の各反復でアクセス/保存する要素は、対応するバッファ内の連続した位置です。以下のCコードの例をご覧ください:
int *buffer;
for(int i = 0; i < size_2; i++)
for(int j = 0; j < size_1; j++)
for(int k = 0; k < size_0; k++)
// access/store element at
// buffer[i * stride_2 + j * stride_1 + k * stride_0]
実践的な例
128要素のバッファから、偶数要素と奇数要素を交互に8要素のグループで4回(合計32要素)アクセスするMLIRでの例を見てみましょう:
aie.dma_bd(%buf : memref<128xi32>, 0, 128, [<8, 16>, <2, 1>, <8, 2>])
実際にアクセスされるのは128要素中の64要素のみで、このアクセスパターンは以下のCコードで表現されます:
int *buffer;
for(int i = 0; i < 8; i++) // size_2
for(int j = 0; j < 2; j++) // size_1
for(int k = 0; k < 8; k++) // size_0
// access/store element at
// buffer[i * 16 + j * 1 + k * 2]
// = buffer[16 * i + j + 2 * k]
Object FIFOでのデータレイアウト変換
Object FIFOを使用してデータ移動を表現する場合、データレイアウト変換はMLIRにおけるobject_fifoクラスコンストラクタに渡すことができます。以下のクラスシグネチャをご覧ください:
class object_fifo:
def __init__(
self,
name,
producerTile,
consumerTiles,
depth,
datatype,
dimensionsToStream=None,
dimensionsFromStreamPerConsumer=None,
):
dimensionsToStreamとdimensionsFromStreamPerConsumerは、それぞれプロデューサとコンシューマのDMAに対してデータレイアウト変換を指定します。
例
<4x8xi8>データ型のオブジェクトを持つObject FIFOを考えます。以下の例では、プロデューサがこのオブジェクトをストリームに送信する際、偶数行の最初の2要素のみを選択します。コンシューマ側では、ストリームからこれらの要素を取得し、メモリにデータとして保存します:
A = tile(1, 1)
B = tile(1, 3)
of0 = object_fifo("objfifo0", A, B, 3, np.ndarray[(4, 8), np.dtype[np.int8]],
[(2, 16), (3, 2)])
[(2, 16), (3, 2)]の変換を対応するCコードで表現すると:
int8_t *buffer; // 4x8 = 32 elements
for(int i = 0; i < 2; i++) // size_1: 2回の反復
for(int j = 0; j < 3; j++) // size_0: 3回の反復
// access/store element at
// buffer[i * 16 + j * 2]
これにより、要素インデックス0, 2, 4(1行目)と16, 18, 20(3行目)にアクセスします。
ランタイムシーケンスでのデータレイアウト変換
Section 2dでランタイムシーケンスプログラミングについて詳しく学びますが、ここで重要なのは、ランタイムシーケンス操作(fill()やdrain()など)は、オプションでtapを入力として受け取り、外部メモリとの間のアクセスパターンをオンザフライで変更できるということです。IRONでのAI Engine用のテンソルアクセスパターンは、こちらで紹介されているtaplibライブラリによって提供されています。
データレイアウト変換を使用した注目すべき実装例については、programming_examplesディレクトリ(例えばmatrix_vector_multiplicationやmatrix_multiplication_whole_array)や、dma_transpose、row_wise_bias_addなどのプログラミング例を参照してください。
注意: より詳細な情報と完全なコード例については、公式ドキュメントを参照してください。
Section 2d - ランタイムデータ移動
これまでのセクションではAIE配列内のデータ移動に焦点を当ててきましたが、ここではNPUデバイス上のホストとAIE配列間のデータ移動について説明します。
ホストと配列間の通信のための操作は、高レベルIRONではRuntimeクラス内の専用sequence()関数に、明示的配置IRONではaie.runtime_sequence操作に配置する必要があります。この関数の引数は、ホスト側からアクセス可能なバッファを表し、関数本体はそれらのバッファとAIE配列間の移動メカニズムを指定します。これらの関数の使用方法については、Section 3で多くの例を見ることができます。
ホストメモリとのランタイムデータ移動管理ガイド
高性能コンピューティングや機械学習アプリケーションでは、データをホストメモリとIRON(AIE配列のMLIRベース表現)で実装されたRyzen AI NPUの加速コア間で効率的に移動させることが重要です。このガイドでは、ユーザーのニーズに応じた抽象化レベルに対応する2つの異なるアプローチを提供します:
- 高レベル構造(RuntimeTasks):
RuntimeクラスとRuntimeTasksを使用した高レベルなデータ移動管理を好む方はこちらをご覧ください。 - 低レベル関数(DMATasks):
npu_dma_memcpy_ndやdma_waitなどの低レベル関数を使用した詳細な制御を好む方はこちらをご覧ください。
注意: より詳細な情報については、公式ドキュメントを参照してください。
Section 2d - ランタイムデータ移動(RuntimeTasks)
IRONは、Workerを起動し、外部メモリとの間でObject FIFOにデータを充填および排出するRuntimeTasksでプログラムできるsequence()関数を持つRuntimeクラスを提案します。このセクションで紹介されるすべてのIRON構造はこちらで利用できます。
Runtimeシーケンスを作成するために、ユーザーは次のように記述できます:
# AIE配列との間のランタイムデータ移動
rt = Runtime()
with rt.sequence(data_ty_a, data_ty_b, data_ty_c) as (a, b, c):
# ランタイムタスク
この関数の引数は、ホスト側で利用可能なバッファを記述します。関数の本体は、それらのバッファがAIE配列にどのように移動されるかを記述します。
ランタイムタスク
ランタイムタスクはランタイム中に実行され、同期または非同期の場合があります。タスクは、IRONデザインの作成中にランタイムシーケンスに追加でき、ランタイム中にもキューに入れることができます。
start()操作は、IRONデザインで宣言された1つまたは複数のWorkerを開始するために使用されます。以下に示され、runtime.pyで定義されています:
def start(self, *args: Worker)
複数のWorkerが入力として与えられた場合、それらは順番に開始されます。
以下のコードスニペットは、1つのmy_worker Workerが開始される方法を示しています:
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, _):
rt.start(my_worker)
この操作を1回使用して複数のWorkerを開始するには、ユーザーは次のように記述できます:
workers = []
# Workerを作成して"workers"配列に追加
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, _):
rt.start(*workers)
fill()操作は、sourceランタイムバッファからのデータでプロデューサ型のin_fifo ObjectFifoHandleを充填するために使用されます。以下に示され、runtime.pyで定義されています:
def fill(
self,
in_fifo: ObjectFifoHandle,
source: RuntimeData,
tap: TensorAccessPattern | None = None,
task_group: RuntimeTaskGroup | None = None,
wait: bool = False,
placement: PlacementTile = AnyShimTile,
)
wait入力がTrueに設定されている場合、この操作は待機されます。つまり、操作が終了したときにコントローラが待機しているトークンが生成されます。placement Shimタイルも明示的に指定できます。そうでない場合、コンパイラは配置アルゴリズムに基づいて選択します。task_groupはこのセクションでさらに説明されます。
以下のコードスニペットは、ソースランタイムバッファa_inからのデータがof_inのプロデューサObjectFifoHandleに送信される方法を示しています。このデータは、同じObject FIFOのコンシューマObjectFifoHandleを介して読み取ることができます。
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (a_in, _, _):
rt.fill(of_in.prod(), a_in)
drain()操作は、データのコンシューマ型のout_fifo ObjectFifoHandleを充填し、そのデータをdestランタイムバッファに書き込むために使用されます。以下に示され、runtime.pyで定義されています:
def drain(
self,
out_fifo: ObjectFifoHandle,
dest: RuntimeData,
tap: TensorAccessPattern | None = None,
task_group: RuntimeTaskGroup | None = None,
wait: bool = False,
placement: PlacementTile = AnyShimTile,
)
wait入力がTrueに設定されている場合、この操作は待機されます。つまり、操作が終了したときにコントローラが待機しているトークンが生成されます。placement Shimタイルも明示的に指定できます。そうでない場合、コンパイラは配置アルゴリズムに基づいて選択します。task_groupはこのセクションでさらに説明されます。
以下のコードスニペットは、of_outのコンシューマObjectFifoHandleからのデータが宛先ランタイムバッファc_outに排出される方法を示しています。データは、そのプロデューサObjectFifoHandleを介してof_outに生成できます。さらに、drain()タスクのwait入力が設定されているため、このタスクは完了まで待機されます。つまり、c_outランタイムバッファがdata_tyで記述されているように十分なデータを受信するまでです。
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, c_out):
rt.drain(of_out.cons(), c_out, wait=True)
ランタイムシーケンスへの操作のインライン化
場合によっては、任意のMLIR操作を生成するPython関数をランタイムシーケンスに挿入することが望ましい場合があります。そのような例の1つは、ユーザーがランタイムパラメータを設定したい場合です。これらは、ランタイム時にWorkerのローカルメモリモジュールにロードされます。
ランタイムシーケンスに操作をインライン化するには、ユーザーはinline_ops()操作を使用できます。以下に示され、runtime.pyで定義されています:
def inline_ops(self, inline_func: Callable, inline_args: list)
inline_funcはMLIRコンテキスト内で実行する関数であり、inline_argsは関数が実行するために必要な状態です。
次のコードスニペットでは、GlobalBuffersの配列が作成され、各バッファは16xi32型のランタイムパラメータを保持します。GlobalBufferは、IRONデザインのトップレベルで宣言されたメモリ領域で、Workerとランタイムの両方が操作に利用できます。use_write_rtpが設定されている場合、ランタイムパラメータ固有の操作が、コンパイラ抽象化の下位レベルでランタイムシーケンス内に生成されます。
# ランタイムパラメータ
rtps = []
for i in range(4):
rtps.append(
GlobalBuffer(
np.ndarray[(16,), np.dtype[np.int32]],
name=f"rtp{i}",
use_write_rtp=True,
)
)
ランタイムパラメータの実際の値は、ランタイム時に各バッファにロードされます:
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, _):
# ランタイムパラメータを設定
def set_rtps(*args):
for rtp in args:
rtp[0] = 50
rtp[1] = 255
rtp[2] = 0
rt.inline_ops(set_rtps, rtps)
これらのグローバルバッファへのデータの伝播は瞬時ではなく、Workerがランタイムパラメータが利用可能になる前にそれらを読み取る可能性があります。これを解決するために、worker.pyで定義されているWorkerRuntimeBarrierをインスタンス化することができます:
class WorkerRuntimeBarrier:
def __init__(self, initial_value: int = 0)
これらのバリアは、個々のWorkerがランタイムシーケンスと同期できるようにします:
workerBarriers = []
for i in range(4):
workerBarriers.append(WorkerRuntimeBarrier())
...
def core_fn(of_in, of_out, rtp, barrier):
barrier.wait_for_value(1)
runtime_parameter = rtp
...
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, _):
...
rt.inline_ops(set_rtps, rtps)
for i in range(4):
rt.set_barrier(workerBarriers[i], 1)
現在、WorkerRuntimeBarrierは0から63の間の任意の値を取ることができます。これは、これらのバリアがアーキテクチャのロックメカニズムを内部で活用しているためです。
注意:
GlobalBufferと同様に、単一のバリアを作成して複数のWorkerへの入力として渡すことができます。コンパイラ抽象化の下位ステージでは、これにより各Workerに対して異なるロックが使用されます。
ランタイムタスクグループ
ランタイムシーケンスを再構成し、以前の構成からいくつかのリソースを再利用することが望ましい場合があります。特に、DMAタスクキュー内のBDなどの一部のリソースが制限されている場合です。
この再構成ステップを容易にするために、IRONはRuntimeTaskGroupを導入します。これは、runtime.pyで定義されているtask_group()関数を使用して作成できます。
RuntimeTaskは、task_group入力を指定することでタスクグループに追加できます。同じグループ内のタスクは、ランタイムシーケンスに追加され、順番に実行されます。finish_task_group()操作は、タスクグループの終わりをマークするために使用されます。つまり、この操作の後、グループ内のすべてのタスクが完了まで待機され、その後すべてが同時に解放され、ランタイムシーケンスが次のタスクグループによって再構成されます。
注意: 完了までランタイムタスクを待機し、すべてのリソースを同時に解放する能力により、タスクグループはランタイムデータ移動タスクの非同期性を処理するのに適しています。
以下のコードスニペットのランタイムシーケンスには、2つのタスクグループがあります。2番目のタスクグループの作成は、最初のタスクグループの実行の終わりに発生することがわかります。
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (a_in, _, c_out):
rt.start(*workers)
tg = rt.task_group() # 最初のタスクグループを開始
for groups in [0, 1]:
rt.fill(of_in.prod(), a_in, task_group=tg)
rt.drain(of_out.cons(), c_out, task_group=tg, wait=True)
rt.finish_task_group(tg)
tg = rt.task_group() # 2番目のタスクグループを開始
rt.finish_task_group(tg)
注意: より詳細な情報については、公式ドキュメントを参照してください。
Section 2d - ランタイムデータ移動(DMATasks)
npu_dma_memcpy_ndによる効率的なデータ移動
npu_dma_memcpy_nd関数は、AI Engine配列と外部メモリ間の異なるメモリ領域間で、ノンブロッキングの多次元データ転送を可能にするための鍵となります。この関数は、信号処理、機械学習、ビデオ処理などの実際のアプリケーションを開発する上で不可欠です。
関数シグネチャとパラメータ:
npu_dma_memcpy_nd(metadata, bd_id, mem, offsets=None, sizes=None, strides=None)
metadata: これは、ホスト側のメモリ転送に割り当てられたShim Tileとそのその1つのDMAチャネルを記録するObject FIFOへの参照、またはObject FIFOの文字列名です。memcpy操作をObject FIFOに関連付けるために、このメタデータ文字列はObject FIFO名文字列と一致する必要があります。bd_id: このmemcpyに使用される特定のバッファディスクリプタ制御レジスタの識別整数。バッファディスクリプタには、以下のパラメータで説明されるDMA転送に必要なすべての情報が含まれています。mem: シーケンス関数への引数として与えられたホストバッファへの参照。この転送はこのバッファから読み取るか書き込みます。tap(オプション):TensorAccessPatternは、memバッファ上のアクセスパターンを決定するためのoffset/sizes/stridesを指定する代替方法です。offsets(オプション): 各次元でのデータ転送の開始点。最大4つのオフセット次元があります。sizes: 各次元で転送されるデータの範囲。最大4つのサイズ次元があります。strides(オプション): 各次元のデータポイント間の間隔ステップ。ストライドとデータの再形成に役立ちます。burst_length(オプション): DMAタスクのバースト長の構成。0の場合、利用可能な最高値にデフォルト設定されます。
stridesとsizesは、セクション2Cで説明されているものと同様にデータ変換を表現します。
使用例:
npu_dma_memcpy_nd(of_in, 0, input_buffer, sizes=[1, 1, 1, 30])
上記の例は、ホストメモリのinput_bufferから30データ要素(120バイト)の線形転送を、「of_in」とラベル付けされた一致するメタデータを持つObject FIFOに記述しています。size次元は右から左に表現され、右が次元0で左が次元3です。使用されない上位次元は1に設定する必要があります。
多次元npu_dma_memcpy_ndの高度な技術
AMDのAI Engineでの高性能コンピューティングアプリケーションでは、複雑なデータ移動のためのnpu_dma_memcpy_nd関数を習得することが重要です。ここでは、sizes、strides、offsetsパラメータを使用して、複雑なデータ転送を効果的に管理することに焦点を当てます。
大きな行列のタイル化
2D行列のタイル化などの一般的なタスクは、npu_dma_memcpy_nd操作を使用して実装できます。ここに説明を示す簡単な例があります。
シナリオ: 2D行列を[100, 200]から[20, 20]の形状にタイル化し、データ型はint16です。規約は[row, col]です。
1. 1つのタイルを転送する構成:
metadata = of_in
bd_id = 3
mem = matrix_memory # 行列のメモリオブジェクト
# サイズはコピーするタイルの範囲を定義します
sizes = [1, 1, 20, 10]
# ストライドは上位(未使用)次元では'0'に、下位次元では'100'(4Bまたは"i32s"での行の長さ)に設定されます
strides = [0, 0, 0, 100]
# オフセットは先頭から開始するためゼロに設定されます
offsets = [0, 0, 0, 0]
npu_dma_memcpy_nd(metadata, bd_id, mem, offsets, sizes, strides)
2. 行列全体をタイル化する構成:
metadata = of_in
bd_id = 3
mem = matrix_memory # 行列のメモリオブジェクト
# サイズはコピーするタイルの範囲を定義します。
# 次元0は10で、タイルの1行に対して20個のint16を転送します、
# 次元1はその行転送を20回繰り返して[20, 20]タイルを完成させます、
# 次元2はそのタイル転送を行に沿って10回繰り返します、
# 次元3はタイルの行の転送を5回繰り返して完成させます。
sizes = [5, 10, 20, 10]
# ストライドは最高(未使用)次元では'0'に、
# 次の行のタイルには'2000'(200 x 20 x 2B / 4B)に、
# 最後の[20, 20]タイルの「右」の次のタイルには'10'に、
# 次元0では'100'(4Bまたは"i32s"での行の長さ)に設定されます。
strides = [0, 2000, 10, 100]
# オフセットは先頭から開始するためゼロに設定されます
offsets = [0, 0, 0, 0]
npu_dma_memcpy_nd(metadata, bd_id, mem, offsets, sizes, strides)
1つ以上のnpu_dma_memcpy_nd操作後のdma_waitによるホスト同期
DMAチャネルとホスト間の同期は、dma_wait操作によって促進され、データの整合性と適切な実行順序が保証されます。dma_wait操作は、ObjectFifoに関連付けられたBDが完了するまで待機し、タスク完了トークンを発行します。
関数シグネチャ:
dma_wait(metadata)
metadata: 待機するDMAオプションに関連付けられたObjectFifo pythonオブジェクトまたはObject FIFOの名前。
使用例:
1つのObject FIFOに関連付けられたDMAを待機:
# 出力データが出力Object FIFOからホストに転送されるのを待ちます
dma_wait(of_out)
複数のObject FIFOに関連付けられたDMAを待機:
dma_wait(of_in, of_out)
npu_dma_memcpy_ndによるデータ移動と同期のベストプラクティス
- バッファディスクリプタを再利用するための同期: 各
npu_dma_memcpy_ndにはbd_idが割り当てられます。各Shim Tileで使用可能なBDは最大16個です。すべての転送が完了したらBDを再利用することが「安全」です。これは、計算操作を完了するために配列にデータを転送するために完了する必要があるBDを考慮して、適切に同期することで管理できます。次に、計算操作によって生成されたデータを受信するBDで同期して、ホストメモリに書き戻します。 - ノンブロッキング転送の注意:
npu_dma_memcpy_ndのノンブロッキング性質を活用して、データ転送と計算を重複させます。 - 同期オーバーヘッドを最小化: 性能を低下させる可能性のある過度のオーバーヘッドを避けるために、慎重に同期/待機します。
dma_task操作による効率的なデータ移動
npu_dma_memcpy_ndとdma_waitの代替として、同様の目的を果たすことができるDMAタスクに関する一連の操作があります。
npu_dma_memcpy_ndを使用するよりもDMAタスク操作を使用する利点が2つあります:
- ユーザーはBD番号を指定する必要がありません
- DMAタスク操作はBD操作のチェーンが可能です。ただし、これはこのガイドの範囲を超えた高度なユースケースです。
すべてのプログラミング例には、DMAタスク操作を使用して記述された*_placed.pyバージョンがあります。
関数シグネチャとパラメータ:
def shim_dma_single_bd_task(
alloc,
mem,
tap: TensorAccessPatter | None = None,
offset: int | None = None,
sizes: MixedValues | None = None,
strides: MixedValues | None = None,
transfer_len: int | None = None,
issue_token: bool = False,
)
alloc:alloc引数はDMAタスクをObjectFIFOに関連付けます。この引数はallocと呼ばれます。これは、データ転送のshim側のエンドポイント(具体的にはshimタイルのチャネル)が、いわゆる「shim DMA allocation」を通じて参照されるためです。ObjectFIFOがShim Tileエンドポイントで作成されると、ObjectFIFOと同じ名前の割り当てが自動的に生成されます。mem: シーケンス関数への引数として与えられたホストバッファへの参照。この転送はこのバッファから読み取るか書き込みます。tap(オプション):TensorAccessPatternは、memバッファ上のアクセスパターンを決定するためのoffset/sizes/stridesを指定する代替方法です。offset(オプション): データ転送の開始点。デフォルト値は0です。sizes: 各次元で転送されるデータの範囲。最大4つのサイズ次元があります。strides(オプション): 各次元のデータポイント間の間隔ステップ。ストライドとデータの再形成に役立ちます。issue_token(オプション): トークンが発行された場合、返されたタスクに対してdma_await_taskを呼び出すことができます。デフォルトはFalseです。burst_length(オプション): DMAタスクのバースト長の構成。0の場合、利用可能な最高値にデフォルト設定されます。
stridesとstridesは、セクション2Cで説明されているものと同様にデータ変換を表現します。
使用例:
out_task = shim_dma_single_bd_task(of_out, C, sizes=[1, 1, 1, N], issue_token=True)
上記の例は、ホストメモリのCバッファから「of_out」とラベル付けされた一致するメタデータを持つObject FIFOへのNデータ要素の線形転送を記述しています。sizes次元は右から左に表現され、右が次元0で左が次元3です。使用されない上位次元は1に設定する必要があります。
dma_await_taskによるホスト同期
DMAチャネルとホスト間の同期は、dma_await_task操作によって促進され、データの整合性と適切な実行順序が保証されます。dma_await_task操作は、タスクに関連付けられたすべてのBDが完了するまで待機します。
関数シグネチャ:
def dma_await_task(*args: DMAConfigureTaskForOp)
args: 1つ以上のdma_taskオブジェクト。dma_taskオブジェクトはshim_dma_single_bd_taskによって返される値です。
使用例:
1つのDMAタスクのタスク完了を待機:
# 出力タスクが完了するのを待ちます
dma_await_task(out_task)
複数のDMAタスクのタスク完了を待機:
# 入力タスクが完了し、次に出力タスクが完了するのを待ちます
dma_await_task(in_task, out_task)
dma_free_taskで待機せずにBDを解放
dma_await_taskは、issue_token=Trueで作成されたタスクに対してのみ呼び出すことができます。issue_token=False(デフォルト)の場合、プログラマがタスクが完了したことを知っているときにdma_free_taskを呼び出す必要があります。dma_free_taskを使用すると、コンパイラは同期なしでタスクのBDを再利用できます。タスクXが完了する前にdma_free_task(X)を使用すると、競合状態と予測不可能な動作につながります。dma_free_task(X)は、他の同期手段と組み合わせてのみ使用してください。たとえば、タスクYがタスクXが完了した後にのみ完了できると推論できる場合、dma_await_task(Y)の呼び出しの後にdma_free_task(X)を発行できます。
関数シグネチャ:
def dma_free_task(*args: DMAConfigureTaskForOp)
args: 1つ以上のdma_taskオブジェクト。dma_taskオブジェクトはshim_dma_single_bd_taskによって返される値です。
使用例:
1つのタスクに関連付けられたDMAに属するBDを解放:
# コンパイラがタスクのBDを再利用できるようにします。プログラマがタスクが完了したことを確認している場合にのみ呼び出す必要があります。
dma_free_task(out_task)
複数のタスクに関連付けられたDMAに属するBDを解放:
# コンパイラが複数のタスクのBDを再利用できるようにします。プログラマがすべてのタスクが完了したことを確認している場合にのみ呼び出す必要があります。
dma_free_task(in_task, out_task)
dma_task操作によるデータ移動と同期のベストプラクティス
- バッファディスクリプタを再利用するための待機または解放:
dma_task操作では、各操作に使用される正確なバッファディスクリプタ(BD)はユーザーには見えませんが、依然として有限数(Shim Tileで最大16)があります。したがって、BDの数が使い果たされる前にdma_await_taskまたはdma_free_taskを使用して再利用できるようにすることが重要です。 - ノンブロッキング転送の注意:
dma_start_taskのノンブロッキング性質を活用して、データ転送と計算を重複させます。 - 同期オーバーヘッドを最小化: 性能を低下させる可能性のある過度のオーバーヘッドを避けるために、慎重に同期/待機します。
結論
npu_dma_memcpy_ndとdma_wait関数は、Ryzen™ AI NPUのAI Engineでデータ転送と同期を管理するための強力なツールです。これらの関数を活用するアプリケーションを理解し効果的に実装することで、開発者は高性能コンピューティングアプリケーションの性能、効率、精度を向上させることができます。
注意: より詳細な情報については、公式ドキュメントを参照してください。
Section 2e - マルチコアプログラミング
このセクションでは、単一コア設計をマルチコア設計に変換する方法を実演します。高レベルIRONと明示的配置レベルIRONの両方について説明します。
高レベルIRON
初期設定とデータ移動
最初のシンプルな設計(aie2.py)では、<48xi32>データ型のオブジェクトを持つ4つのObject FIFOを使用します:外部メモリとメモリタイル間の入力用に1つ(of_in)、メモリタイルとWorker間の入力用に1つ(of_in1)、Worker実行出力用に1つ(of_out1)、出力をメモリタイルから外部メモリに戻すために1つ(of_out)です。Workerのタスクは、入力を取得し、エントリを1ずつ増加させ、その結果を出力に格納し、両方を解放することです。
単一Worker設計のデータ移動:
data_size = 48
# テンソル型の定義
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
# 入力データ移動
of_in = ObjectFifo(data_ty, name="in")
of_in1 = of_in.cons().forward(obj_type=data_ty, name="in1")
# 出力データ移動
of_out1 = ObjectFifo(data_ty, name="out1")
of_out = of_out1.cons().forward(obj_type=data_ty, name="out")
スケールアウトした設計(aie2_multi.py)では、単一のメモリタイルを維持しますが、3つのWorkerに拡張します。Object FIFOオブジェクトのデータ型は<16xi32>に変更され、複数のWorker間でデータを分散および結合するためのObject FIFOリンク(分散と結合パターンを参照)が追加されました:
マルチWorker設計のデータ移動:
n_workers = 3
data_size = 48
tile_size = data_size // 3
# テンソル型の定義
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
tile_ty = np.ndarray[(tile_size,), np.dtype[np.int32]]
# 入力データ移動
of_offsets = [tile_size * worker for worker in range(n_workers)]
of_in = ObjectFifo(data_ty, name="in")
of_ins = (
of_in
.cons()
.split(
of_offsets,
obj_types=[tile_ty] * n_workers,
names=[f"in{worker}" for worker in range(n_workers)],
)
)
# 出力データ移動
of_out = ObjectFifo(data_ty, name="out")
of_outs = (
of_out.prod().join(
of_offsets,
obj_types=[tile_ty] * n_workers,
names=[f"out{worker}" for worker in range(n_workers)],
)
)
Worker実装
最初のWorkerの実装では、配列演算が可能なPythonスクリプトを参照するだけです。
単一Worker:
# コアが実行するタスク
def core_fn(of_in, of_out):
elem_in = of_in.acquire(1)
elem_out = of_out.acquire(1)
for i in range_(data_size):
elem_out[i] = elem_in[i] + 1
of_in.release(1)
of_out.release(1)
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of_in1.cons(), of_out1.prod()])
マルチWorker設計では、同じカーネルが異なるオブジェクトサイズで3回インスタンス化されます。
複数のWorker:
# タスクを実行するWorkerを作成
workers = []
for worker in range(n_workers):
workers.append(
Worker(
core_fn,
[
of_ins[worker].cons(),
of_outs[worker].prod(),
],
)
)
ランタイムシーケンス
最後に、ランタイムシーケンスは、AIE配列との間でデータを移動させるホスト実行コードを定義します。
単一Workerランタイム:
# AIE配列との間でデータを移動するランタイム操作
rt = Runtime()
with rt.sequence(data_size, data_size, data_size) as (a_in, b_out, _):
rt.start(my_worker)
rt.fill(of_in.prod(), a_in)
rt.drain(of_out.cons(), b_out, wait=True)
マルチWorker設計では、rt.start()への呼び出しが少し変わるだけです。
マルチWorkerランタイム:
# AIE配列との間でデータを移動するランタイム操作
rt = Runtime()
with rt.sequence(data_size, data_size, data_size) as (a_in, b_out, _):
rt.start(*workers)
rt.fill(of_in.prod(), a_in)
rt.drain(of_out.cons(), b_out, wait=True)
コンパイル
両方の設計を次のコマンドでコンパイルして実行できます:
make all
明示的配置レベルIRON
タイル宣言
最初の設計(aie2_placed.py)では、3つのタイルを宣言します:1つのコンピュートタイル、1つのメモリタイル、1つのshimタイルです。これらのタイルのリソースは、それぞれデータ処理、ストレージ、外部メモリアクセスの目的で割り当てられます。
単一コア設計のタイル:
ShimTile = tile(0, 0)
MemTile = tile(0, 1)
ComputeTile = tile(0, 2)
マルチコア設計(aie2_placed_multi.py)では、1つのコンピュートタイルの代わりに3つのコンピュートタイルを宣言します。
マルチコア設計のタイル:
n_cores = 3
ShimTile = tile(0, 0)
MemTile = tile(0, 1)
ComputeTiles = [tile(0, 2 + i) for i in range(n_cores)]
データ移動の設定
次に、タイル間のデータ移動を設定します。高レベルIRONでのアプローチと同様に、最初の設計では4つのObject FIFOを使用し、マルチコア設計ではObject FIFOリンクを使用します。
単一コア設計のObject FIFO:
data_size = 48
buffer_depth = 2
data_ty = np.ndarray[(48,), np.dtype[np.int32]]
# 入力データ移動
of_in = object_fifo("in", ShimTile, MemTile, buffer_depth, data_ty)
of_in0 = object_fifo("in0", MemTile, ComputeTile, buffer_depth, data_ty)
object_fifo_link(of_in, of_in0)
# 出力データ移動
of_out = object_fifo("out", MemTile, ShimTile, buffer_depth, data_ty)
of_out0 = object_fifo("out0", ComputeTile, MemTile, buffer_depth, data_ty)
object_fifo_link(of_out0, of_out)

マルチコア設計のObject FIFOは、最初の設計から大きく変更されています(分散と結合パターンを参照)。
マルチコア設計のObject FIFO:
n_cores = 3
data_size = 48
tile_size = data_size // 3
buffer_depth = 2
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
tile_ty = np.ndarray[(tile_size,), np.dtype[np.int32]]
# 入力データ移動
inX_fifos = []
of_in = object_fifo("in", ShimTile, MemTile, buffer_depth, data_ty)
for i in range(n_cores):
inX_fifos.append(object_fifo(
f"in{i}", MemTile, ComputeTiles[i], buffer_depth, tile_ty
))
# 入力/出力データの結合/分散のためのオフセットを計算
if n_cores > 1:
of_offsets = [16 * i for i in range(n_cores)]
else:
of_offsets = []
object_fifo_link(of_in, inX_fifos, [], of_offsets)
# 出力データ移動
outX_fifos = []
of_out = object_fifo("out", MemTile, ShimTile, buffer_depth, data_ty)
for i in range(n_cores):
outX_fifos.append(object_fifo(
f"out{i}", ComputeTiles[i], MemTile, buffer_depth, tile_ty
))
object_fifo_link(outX_fifos, of_out, of_offsets, [])

コア実装
この段階では、各コンピュートタイルがどのコードを実行するかを指定します。
単一コア:
@core(ComputeTile)
def core_body():
# 実質的にwhile(1)
for _ in range_(0xFFFFFFFF):
elem_in = of_in0.acquire(ObjectFifoPort.Consume, 1)
elem_out = of_out0.acquire(ObjectFifoPort.Produce, 1)
for i in range_(data_size):
elem_out[i] = elem_in[i] + 1
of_in0.release(ObjectFifoPort.Consume, 1)
of_out0.release(ObjectFifoPort.Produce, 1)
マルチコア設計では、各コアは前のステップのObject FIFO設定に応じて、適切なObject FIFOのインデックスを使用します。重要な違いは、data_sizeではなくtile_sizeを処理することです。
マルチコア:
for i in range(n_cores):
# コンピュートタイル i
@core(ComputeTiles[i])
def core_body():
for _ in range_(0xFFFFFFFF):
elem_in = inX_fifos[i].acquire(ObjectFifoPort.Consume, 1)
elem_out = outX_fifos[i].acquire(ObjectFifoPort.Produce, 1)
for j in range_(tile_size):
elem_out[j] = elem_in[j] + 1
inX_fifos[i].release(ObjectFifoPort.Consume, 1)
outX_fifos[i].release(ObjectFifoPort.Produce, 1)
コンパイル
両方の設計を次のコマンドでコンパイルして実行できます:
make placed
注意: より詳細な情報と完全なコード例については、公式ドキュメントを参照してください。
Section 2f - 実践的な例
このセクションでは、一般的なObject FIFOデータ移動パターンを含むいくつかの例を紹介します。これらの例は、他の設計に簡単にインポートして適応できるように十分にシンプルに設計されています。
例1 - シングル/ダブルバッファ
シングル/ダブルバッファを使用したコア間のデータ移動
例2 - 外部メモリからコアへ
ダブルバッファを使用した外部メモリとコア間の往復データ移動
例3 - L2を経由した外部メモリからコアへ
ダブルバッファを使用してL2を経由した外部メモリとコア間の往復データ移動
例4 - L2からの分散
L2を通じて外部メモリから複数のコアにデータを分散
例5 - L2での結合
L2を通じて複数のコアから外部メモリにデータを結合
注意: 各例の完全なソースコードと詳細な説明については、公式ドキュメントを参照してください。
シングル/ダブルバッファ
single_buffer.pyのデザインは、Object FIFO of_inを使用してmy_workerの出力をmy_worker2に転送し、Object FIFO of_outを使用してmy_worker2の出力を外部メモリに転送します。of_inの深さは1で、以下の図に示すように、2つのWorker間の単一バッファを記述しています。

注意: 上の図は、Workerが既に
ComputeTile2とComputeTile3にマッピングされていることを前提としています。ただし、これが唯一可能なマッピングではなく、Workerを作成する際、その配置はコンパイラに任せることができます。
このデザインのプロデューサおよびコンシューマプロセスの両方が、些細なタスクを持っています。my_workerで実行されているプロデューサプロセスは、単一バッファをacquireし、消費のためにreleaseする前にそのすべてのエントリに1を書き込みます。my_worker2で実行されているコンシューマプロセスは、of_inから単一バッファとof_outから単一バッファをacquireし、入力Object FIFOから出力Object FIFOにデータをコピーし、他のプロセスのために両方のオブジェクトをreleaseします。
このデザインでデータ転送にダブルバッファ(またはピンポンバッファ)を使用するには、ユーザーはObject FIFOの深さを2に設定するだけです。Object FIFOの低レベル化がピンバッファとポンバッファの間を適切に循環させるため、他の変更は必要ありません。深さを変更するには、ユーザーは次のように記述する必要があります:
of_in = ObjectFifo(data_ty, name="in", depth=2) # ダブルバッファ
of_out = ObjectFifo(data_ty, name="out", depth=2) # ダブルバッファ
この変更により、以下の図に示すように、Object FIFOの利用可能なリソースの数が効果的に増加します:

programming_examplesで利用可能なすべての例には、このデータ移動パターンが含まれています。
このデザインをコンパイル、実行、テストするには、次のコマンドを使用できます:
make
make run
このデザインの明示的に配置されたレベルのIRONプログラミングは、single_buffer_placed.pyで利用できます。次のコマンドでコンパイル、実行、テストできます:
env use_placed=1 make
make run
注意: より詳細な情報については、公式ドキュメントを参照してください。
外部メモリからコアへ
ext_to_core.pyのデザインは、Object FIFO of_inを使用して外部メモリからmy_workerにデータを持ち込み、別のObject FIFO of_outを使用してWorkerから外部メモリにデータを送信します。各FIFOはダブルバッファを使用します。

# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(tile_ty, name="in")
of_out = ObjectFifo(tile_ty, name="out")
コンシューマとプロデューサの両方のプロセスがmy_workerで実行されています。プロデューサプロセスは、消費するためにof_inから1つのオブジェクトをacquireし、生成するためにof_outから1つのオブジェクトをacquireします。次に、入力オブジェクトの値を読み取り、両方のオブジェクトをreleaseする前に、そのすべてのエントリに1を追加します。
このデザインをコンパイル、実行、テストするには、次のコマンドを使用できます:
make
make run
このデザインの明示的に配置されたレベルのIRONプログラミングは、ext_to_core_placed.pyで利用できます。次のコマンドでコンパイル、実行、テストできます:
env use_placed=1 make
make run
test.cppおよびデザインコードの# To/from AIE-array data movementセクションについては、セクション2dで詳しく説明されます。
このデータ移動パターンを含む他の例は、programming_examplesで利用できます。注目すべき例としては、vector_reduce_addとvector_scalar_addがあります。
注意: より詳細な情報については、公式ドキュメントを参照してください。
L2を経由した外部メモリからコアへ
ext_to_coreL2.pyのデザインは、前の例と非常に似ていますが、このデザインでは最初にof_in0を使用して外部メモリからL2メモリ(つまりMemタイル)に24xi32データを持ち込む点が異なります。次に、of_in1を使用して、MemTileからmy_workerにデータのより小さな8xi32スライスを持ち込みます。2つのFIFOが、最初にof_out1を介してL2に8xi32テンソルとしてデータを持ち込み、次にof_out0を介して外部メモリに24xi32テンソルとして持ち込みます。すべてのFIFOはダブルバッファを使用します。

# ObjectFifosを使用したデータフロー
# 入力
of_in0 = ObjectFifo(tile24_ty, name="in0")
of_in1 = of_in0.cons().forward(name="in1", obj_type=tile8_ty)
# 出力
of_out1 = ObjectFifo(tile8_ty, name="out1")
of_out0 = of_out1.cons().forward(name="out0", obj_type=tile24_ty)
Worker上のプロセスは、前のデザインと同じです。プロデューサプロセスは、消費するためにof_in1から1つのオブジェクトをacquireし、生成するためにof_out1から1つのオブジェクトをacquireします。次に、入力オブジェクトの値を読み取り、両方のオブジェクトをreleaseする前に、そのすべてのエントリに1を追加します。
このデザインをコンパイル、実行、テストするには、次のコマンドを使用できます:
make
make run
このデザインの明示的に配置されたレベルのIRONプログラミングは、ext_to_core_L2_placed.pyで利用できます。次のコマンドでコンパイル、実行、テストできます:
env use_placed=1 make
make run
test.cppおよびデザインコードの# To/from AIE-array data movementセクションについては、セクション2dで詳しく説明されます。
このデータ移動パターンを含む他の例は、programming_examples/matrix_multiplication/で利用できます。
注意: より詳細な情報については、公式ドキュメントを参照してください。
L2からの分散
distribute_L2.pyのデザインは、Object FIFO of_inを使用して外部メモリからL2に24xi32テンソルとしてデータを持ち込みます。そこから、データはより小さな8xi32部分で3つのObject FIFOに分散されます。各Workerは、アクセスする3つのObject FIFOのどれであるかに基づいて、より大きなデータの異なる部分を受け取ります。

# ObjectFifosを使用したデータフロー
# 入力
of_offsets = [8 * worker for worker in range(n_workers)]
of_in = ObjectFifo(tile24_ty, name="in")
of_ins = (
of_in
.cons()
.split(
of_offsets,
obj_types=[tile8_ty] * n_workers,
names=[f"in{worker}" for worker in range(n_workers)],
)
)
すべてのWorkerは、それぞれの入力Object FIFOから消費するために1つのオブジェクトをacquireし、そのすべてのエントリに1を追加し、オブジェクトをreleaseするという同じプロセスを実行しています。join designは、データが外部メモリに送り返され、テストされる方法を示しています。
このデザインをコンパイルするには、次のコマンドを使用できます:
make
このデザインの明示的に配置されたレベルのIRONプログラミングは、distribute_L2_placed.pyで利用できます。次のコマンドでコンパイルできます:
env use_placed=1 make
このデータ移動パターンを含む他の例は、programming_examples/matrix_multiplication/で利用できます。
注意: より詳細な情報については、公式ドキュメントを参照してください。
L2での結合
join_L2.pyのデザインには3つのWorkerがあり、それぞれが3つのObject FIFOのうちの1つを介してL2に8xi32のデータを送信します。そこで、データは各Object FIFOのオフセットに基づいて24xi32テンソルに結合されます。次に、of_outを使用してデータが外部メモリに送信されます。

# ObjectFifosを使用したデータフロー
# 出力
of_offsets = [8 * worker for worker in range(n_workers)]
of_out = ObjectFifo(tile24_ty, name="out")
of_outs = (
of_out.prod().join(
of_offsets,
obj_types=[tile8_ty] * n_workers,
names=[f"out{worker}" for worker in range(n_workers)],
)
)
すべてのWorkerは、それぞれの入力Object FIFOから生成するために1つのオブジェクトをacquireし、そのすべてのエントリに1を書き込み、オブジェクトをreleaseするという同じプロセスを実行しています。
このデザインは、前のdistributeデザインと組み合わされて、外部メモリからAIE配列への完全なデータ移動とその逆を実現します。結果のコードは、distribute_and_join_L2.pyで利用できます。次のコマンドでコンパイル、実行、テストできます:
make
make run
このデザインの明示的に配置されたレベルのIRONプログラミングは、distribute_and_join_L2_placed.pyで利用できます。次のコマンドでコンパイル、実行、テストできます:
env use_placed=1 make
make run
test.cppおよびデザインコードの# To/from AIE-array data movementセクションについては、セクション2dで詳しく説明されます。
注意: distribute_and_join_L2.pyのデザインは、ext_to_coreを取り、入力データのより小さな部分を3つのWorkerに分散します。このパターンは通常、入力データが単一のコアのメモリモジュールに対して大きすぎて、より小さなチャンクで処理する必要がある場合に使用され、その結果が結合されて最終的な出力が生成されます。
このデータ移動パターンを含む他の例は、programming_examplesで利用できます。注目すべき例はvector_expです。
注意: より詳細な情報については、公式ドキュメントを参照してください。
Section 2g - Object FIFOを使わないデータ移動
すべてのデータ移動パターンがObject FIFOで記述できるわけではありません。この高度なセクションでは、AIEタイルのDirect Memory Access チャネル(またはDMA)を使用してデータ移動を表現する方法について詳しく説明します。このセクションで紹介されるコードと概念をより理解するために、まずSection 2aの高度なトピック - DMAについてを読むことをお勧めします。
このガイドの部分は、明示的配置レベルIRONで説明されています。
AIEアーキテクチャには現在3つの異なるタイプのタイルがあります:「tile」と呼ばれるコンピュートタイル、「Mem tiles」と呼ばれるメモリタイル、「Shim tiles」と呼ばれる外部メモリインターフェイスタイルです。これらのタイルはそれぞれ、演算能力とメモリ容量に関して独自の属性を持っていますが、DMAの基本設計は同じです。異なるタイプのDMAは、aie.pyのコンストラクタを使用して初期化できます:
@mem(tile) # コンピュートタイルのDMA
@shim_dma(tile) # ShimタイルのDMA
@memtile_dma(tile) # MemタイルのDMA
DMAハードウェアコンポーネントには、一定数の入力および出力channels(チャネル)があり、それぞれに方向とポートインデックスがあります。入力チャネルはキーワードS2MMで示され、出力チャネルはMM2Sで示されます。ポートインデックスはタイルごとに異なります。たとえば、コンピュートタイルとShimタイルには2つの入力ポートと2つの出力ポートがありますが、Memタイルには6つの入力ポートと6つの出力ポートがあります。
任意のタイルのDMAのチャネルは、統一されたdmaコンストラクタを使用して初期化できます:
def dma(
channel_dir,
channel_index,
*,
num_blocks=1,
loop=None,
repeat_count=None,
sym_name=None,
loc=None,
ip=None,
)
各チャネルでのデータ移動は、バッファディスクリプタ(または「BD」)のチェーンによって記述されます。各BDは、移動されるデータを記述し、その同期メカニズムを設定します。dmaコンストラクタは、num_blocks=1というデフォルト値の入力で見られるように、すでにそのようなBDのためのスペースを1つ作成します。
以下のコードスニペットは、tile_aのDMAを設定して、入力チャネル0に入ってくるデータをbuff_inに書き込む方法を示しています:
tile_a = tile(1, 3)
prod_lock = lock(tile_a, lock_id=0, init=1)
cons_lock = lock(tile_a, lock_id=1, init=0)
buff_in = buffer(tile=tile_a, datatype=np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
@mem(tile_a)
def mem_body():
@dma(S2MM, 0) # 入力チャネル、ポート0
def dma_in_0():
use_lock(prod_lock, AcquireGreaterEqual)
dma_bd(buff_in)
use_lock(cons_lock, Release)
ロックprod_lockとcons_lockは、AIE-MLアーキテクチャのセマンティクスに従います。それらのタスクは、タイルとそのDMAの実行における同期ポイントをマークすることです。たとえば、タイルが現在buff_inを使用している場合、それが完了したときのみprod_lockを解放し、その時にDMAがbuff_inの新しい入力でデータを上書きすることが許可されます。同様に、タイルのコアはcons_lockを照会して、新しいデータが読み取り可能になったこと(つまり、DMAがロックを解放してコアが取得できるようになったとき)を知ることができます。
前のコードでは、チャネルにはチェーン内に1つのBDしかありませんでした。チェーンに追加のBDを追加するには、ユーザーは以下のコンストラクタを使用できます。このコンストラクタは、追加されるチェーン内の前のBDを入力として受け取ります:
@another_bd(dma_bd)
次のコードスニペットは、前のコンストラクタを使用して、前の入力チャネルをダブル(またはピンポン)バッファで拡張する方法を示しています:
tile_a = tile(1, 3)
prod_lock = lock(tile_a, lock_id=0, init=2) # プロデューサロックが2つのトークンを持つことに注意
cons_lock = lock(tile_a, lock_id=1, init=0)
buff_ping = buffer(tile=tile_a, datatype=np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
buff_pong = buffer(tile=tile_a, datatype=np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
@mem(tile_a)
def mem_body():
@dma(S2MM, 0, num_blocks=2) # 追加のBDに注意
def dma_in_0():
use_lock(prod_lock, AcquireGreaterEqual)
dma_bd(buff_ping)
use_lock(cons_lock, Release)
@another_bd(dma_in_0)
def dma_in_1():
use_lock(prod_lock, AcquireGreaterEqual)
dma_bd(buff_pong)
use_lock(cons_lock, Release)
注意: このDMA設定は、ダブルバッファのObject FIFO低レベル化の形式と同等です。
上記のコードは、次の図のように視覚化できます。ここで、2つのBDが相互にピンポンします:
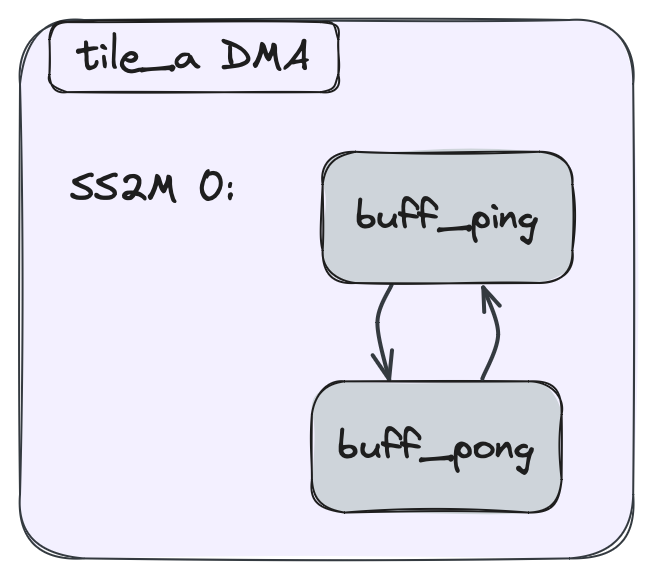
データ移動を設定する最後のステップは、Object FIFOがプロデューサタイルとコンシューマタイルを持つのと同様に、そのエンドポイントを確立することです。これを行うには、ユーザーはflowコンストラクタを使用する必要があります:
def flow(
source,
source_bundle=None,
source_channel=None,
dest=None,
dest_bundle=None,
dest_channel=None,
)
flowは、2つのDMAのチャネル間で確立されます(他のエンドポイントも利用可能ですが、このセクションの範囲を超えています)。そのため、以下が必要です:
sourceとdestタイルsource_bundleとdest_bundle(エンドポイントのタイプを表し、我々の範囲ではWireBundle.DMAになります)source_channelとdest_channel(チャネルのインデックスを表します)
たとえば、タイルtile_aとタイルtile_bの間にフローを作成し、tile_aがその出力チャネル0でtile_bの入力チャネル1にデータを送信する場合、ユーザーは以下のように記述できます:
aie.flow(tile_a, WireBundle.DMA, 0, tile_b, WireBundle.DMA, 1)
2つのチャネルの方向はフローで必要とされず、インデックスのみであることに注意してください。これは、フローの低レベル化がsourceとdest入力に基づいて方向を推論できるためです。
次のコードスニペットは、tile_aがtile_bにデータを送信する2つのタイルの完全な例を示しています:
tile_a = tile(1, 2)
tile_b = tile(1, 3)
prod_lock_a = lock(tile_a, lock_id=0, init=1)
cons_lock_a = lock(tile_a, lock_id=1, init=0)
buff_a = buffer(tile=tile_a, np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
prod_lock_b = lock(tile_b, lock_id=0, init=1)
cons_lock_b = lock(tile_b, lock_id=1, init=0)
buff_b = buffer(tile=tile_b, np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
aie.flow(tile_a, WireBundle.DMA, 0, tile_b, WireBundle.DMA, 1)
@mem(tile_a)
def mem_body():
@dma(MM2S, 0) # 出力チャネル、ポート0
def dma_in_0():
use_lock(cons_lock_a, AcquireGreaterEqual)
dma_bd(buff_a)
use_lock(prod_lock_a, Release)
@mem(tile_b)
def mem_body():
@dma(S2MM, 1) # 入力チャネル、ポート1
def dma_in_0():
use_lock(prod_lock_b, AcquireGreaterEqual)
dma_bd(buff_b)
use_lock(cons_lock_b, Release)
注意: より詳細な情報については、公式ドキュメントを参照してください。
Section 3 - My First Program

このセクションでは、AIE配列用の最初の完全なプログラムを作成します。ここでは、デバイスバイナリとホストバイナリの2つの異なるバイナリアーティファクトをコンパイルします。デバイスバイナリは、AIE配列の構成を含むXCLBINファイル(コンピュートコアのプログラムメモリ、データムーバーのバッファディスクリプタ、スイッチボックス設定など)と、外部メモリとの間のデータ移動を実行するシーケンス命令を含むinsts.binで構成されます。ホストバイナリは、デバイスバイナリをロードし、insts.binシーケンスをトリガーし、何らかのテストベンチチェックを実行して結果を検証する実行可能プログラムです。
セクション1とセクション2で学んだ構造設計とデータ移動の概念を組み合わせて、ホストバイナリは主にC++またはPythonで作成され、Xilinx RunTime (XRT)およびAMD XDNA Driverを使用してデバイスと通信します。セクション4では、ホストコードを使用した性能測定とトレースについて詳しく説明します。

このセクションで使用する例は、ベクトルスカラー乗算(c = a * factor)です。これは、basic programming_examplesディレクトリにあります。このガイドセクションのコードスニペットの完全版は、programming_examplesディレクトリで見つけることができます。入力ベクトルaは合計4096個のint32要素で構成され、1024個の要素を持つ4つのチャンクに分割されて処理されます。
AIE配列の構造記述

設計の記述はaie2.pyファイルにあります。その構造はセクション1で紹介したhigh-level IRONスタイルを使用しており、Workerタスクを配置し、ホストからAIE配列へのシーケンスを定義します。この設計では、乗算を実行するコンピュートコアとともにshimDMAユニットを配置し、入力と出力データを外部メモリとの間で移動させます。簡単にするために、この設計例では外部関数として定義されたバイナリカーネル(つまり、構造記述の外部でコンパイルされたカーネル)を使用します。
tensor_size = 4096
tile_size = tensor_size // 4
# テンソル型の定義
tensor_ty = np.ndarray[(tensor_size,), np.dtype[np.int32]]
tile_ty = np.ndarray[(tile_size,), np.dtype[np.int32]]
scalar_ty = np.ndarray[(1,), np.dtype[np.int32]]
# 外部バイナリカーネルの定義
scale_fn = Kernel(
"vector_scalar_mul_aie_scalar",
"scale.o",
[tile_ty, tile_ty, scalar_ty, np.int32],
)
データ移動

次に、データ移動を設定する必要があります。これはセクション2で詳しく説明されているObject FIFOを使用します。この例では、3つのObject FIFOがあります:2つの入力FIFO(入力ベクトルa用に1つとスカラー係数用に1つ)と1つの出力FIFO(出力ベクトルc用)です。各Object FIFOの深さは2です。これにより、ShimのDMAとCompute TileのDMAが並行して実行でき、一方がバッファへの書き込みを行っている間に、もう一方がバッファからの読み取りを行うことができます。
# 入力データ移動
of_in = ObjectFifo(tile_ty, name="in")
of_factor = ObjectFifo(scalar_ty, name="infactor")
# 出力データ移動
of_out = ObjectFifo(tile_ty, name="out")
Object FIFOは、shimDMAと外部メモリ間のデータ転送を実行する際に使用されます。このデータ転送の実装は、ランタイムシーケンスで定義されます。ランタイムシーケンスについては、セクション2dで詳しく説明されています。現在の例では、Runtime()クラスを使用して、入力データ(rt.fill())と出力データ(rt.drain())のshimDMA操作を設定します。また、Workerタスクを開始します(rt.start())。
# AIE配列との間でデータを移動するランタイム操作
rt = Runtime()
with rt.sequence(tensor_ty, scalar_ty, tensor_ty) as (a_in, f_in, c_out):
rt.start(my_worker)
rt.fill(of_in.prod(), a_in)
rt.fill(of_factor.prod(), f_in)
rt.drain(of_out.cons(), c_out, wait=True)
コンピュートコアのアクセスパターン
最後に、各Object FIFOのオブジェクトにアクセスするパターンを定義します。Object FIFOオブジェクトへのアクセスは、プロデューサとコンシューマのハンドルを介して実行されます。コンピュートコアは、Object FIFOオブジェクトのacquire(取得)とrelease(解放)を行います。
入力Object FIFO of_inと出力Object FIFO of_outについては、各要素を取得し、外部カーネル関数scale_fnを介して処理し、それぞれのObject FIFOに解放します。これらの操作は、全4096要素を完全に処理するために、各反復で1024要素のチャンクを処理する4回のループで繰り返されます。スカラー係数Object FIFO of_factorについては、コアがループを開始する前に要素を取得し、処理が完了した後に解放します。
# コアが実行するタスク
def core_fn(of_in, of_factor, of_out, scale_scalar):
elem_factor = of_factor.acquire(1)
for _ in range_(4):
elem_in = of_in.acquire(1)
elem_out = of_out.acquire(1)
scale_scalar(elem_in, elem_out, elem_factor, 1024)
of_in.release(1)
of_out.release(1)
of_factor.release(1)
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of_in.cons(), of_factor.cons(), of_out.prod(), scale_fn])
カーネルコード
カーネルコードはvector_scalar_mul.ccファイルにあります。この例では、汎用C++コードを使用したスカラープロセッサバージョンを使用します。関数シグネチャは次のとおりです:
void vector_scalar_mul_aie_scalar(int32_t *a_in, int32_t *c_out,
int32_t *factor, int32_t N) {
for (int i = 0; i < N; i++) {
c_out[i] = *factor * a_in[i];
}
}
スカラー係数が配列ポインタとして渡されることに注意してください。これは、Object FIFO通信メカニズムが、スカラー係数をメモリ内の要素の配列として送信するためです。そのため、カーネルコード内で参照解除する必要があります。AIEコアのベクトルプロセッサ機能を活用する、より最適化されたベクトル化されたカーネル実装の例については、セクション4を参照してください。
ホストコード
概要
ホストコード設計は、C++(test.cpp)またはPython(test.py)で記述できます。詳細についてはセクション4bを参照してください。一般的に、C++ホストコードはC++ test utilitiesを、PythonホストコードはPython test utilitiesを利用して、コードを簡潔に保ちます。C++とPythonの両方のホストコードには、7つの主要なステップがあります。ここでは、C++バージョンに焦点を当てます。
1. プログラム引数の解析
C++ホストコードは、3つの必須引数を受け入れます:XCLBINファイルへのパス、カーネル名、シーケンス命令ファイルへのパス。オプションでverbosityフラグも受け入れます。この例では、test_utils.hを使用して引数を解析します。
// プログラム引数の解析
po::options_description desc("Allowed options");
po::variables_map vm;
test_utils::add_default_options(desc);
test_utils::parse_options(argc, argv, desc, vm);
int verbosity = vm["verbosity"].as<int>();
// 設計定数の宣言
constexpr bool VERIFY = true;
constexpr int IN_SIZE = 4096;
constexpr int OUT_SIZE = IN_SIZE;
2. 命令シーケンスの読み込み
次に、シーケンス命令ファイルを読み込みます。このファイルには、外部メモリとの間のデータ移動を実行する命令が含まれています。
// 命令シーケンスのロード
std::vector<uint32_t> instr_v =
test_utils::load_instr_sequence(vm["instr"].as<std::string>());
3. XRT環境の作成
XRTランタイムを初期化し、デバイスとカーネルをロードします。
xrt::device device;
xrt::kernel kernel;
test_utils::init_xrt_load_kernel(device, kernel, verbosity,
vm["xclbin"].as<std::string>(),
vm["kernel"].as<std::string>());
4. XRTバッファオブジェクトの作成
XRTは最大5つのinoutバッファをサポートし、3から始まる連続したgroup_id値を使用してマッピングされます。この例では、命令シーケンス用に1つ、入力ベクトル用に1つ、スカラー係数用に1つ、出力ベクトル用に1つの、合計4つのバッファオブジェクトを作成します。番号付けは、シーケンス定義の順序に従います。最初の引数がgroup_id(3)を受け取り、2番目がgroup_id(4)を受け取る、というように続きます。この番号付けの詳細については、Python utils documentationを参照してください。
// バッファオブジェクトの設定
auto bo_instr = xrt::bo(device, instr_v.size() * sizeof(int),
XCL_BO_FLAGS_CACHEABLE, kernel.group_id(1));
auto bo_inA = xrt::bo(device, IN_SIZE * sizeof(int32_t),
XRT_BO_FLAGS_HOST_ONLY, kernel.group_id(3));
auto bo_inFactor = xrt::bo(device, 1 * sizeof(int32_t),
XRT_BO_FLAGS_HOST_ONLY, kernel.group_id(4));
auto bo_outC = xrt::bo(device, OUT_SIZE * sizeof(int32_t),
XRT_BO_FLAGS_HOST_ONLY, kernel.group_id(5));
5. データの初期化と同期
バッファオブジェクトをデータで初期化し、ホストからデバイスのメモリに同期します。
// 命令ストリームをxrtバッファオブジェクトにコピー
void *bufInstr = bo_instr.map<void *>();
memcpy(bufInstr, instr_v.data(), instr_v.size() * sizeof(int));
// バッファbo_inAを初期化
int32_t *bufInA = bo_inA.map<int32_t *>();
for (int i = 0; i < IN_SIZE; i++)
bufInA[i] = i + 1;
// バッファbo_inFactorを初期化
int32_t *bufInFactor = bo_inFactor.map<int32_t *>();
int32_t scaleFactor = 3;
*bufInFactor = scaleFactor;
// バッファbo_outCをゼロクリア
int32_t *bufOut = bo_outC.map<int32_t *>();
memset(bufOut, 0, OUT_SIZE * sizeof(int32_t));
// ホストからデバイスのメモリに同期
bo_instr.sync(XCL_BO_SYNC_BO_TO_DEVICE);
bo_inA.sync(XCL_BO_SYNC_BO_TO_DEVICE);
bo_inFactor.sync(XCL_BO_SYNC_BO_TO_DEVICE);
bo_outC.sync(XCL_BO_SYNC_BO_TO_DEVICE);
6. AIEで実行して同期
カーネルを実行し、完了を待ち、結果をデバイスからホストのメモリに同期します。
unsigned int opcode = 3;
auto run =
kernel(opcode, bo_instr, instr_v.size(), bo_inA, bo_inFactor, bo_outC);
run.wait();
// デバイスからホストのメモリに同期
bo_outC.sync(XCL_BO_SYNC_BO_FROM_DEVICE);
7. テストベンチチェックの実行
最後に、出力をゴールデンリファレンスと比較して結果を検証します。
// 出力をゴールデンと比較
int errors = 0;
if (verbosity >= 1) {
std::cout << "Verifying results ..." << std::endl;
}
for (uint32_t i = 0; i < IN_SIZE; i++) {
int32_t ref = bufInA[i] * scaleFactor;
int32_t test = bufOut[i];
if (test != ref) {
if (verbosity >= 1)
std::cout << "Error in output " << test << " != " << ref << std::endl;
errors++;
} else {
if (verbosity >= 1)
std::cout << "Correct output " << test << " == " << ref << std::endl;
}
}
プログラムの実行
設計をコンパイルして実行するには、次のコマンドを使用します:
make
make run
これにより、C++ホストコードを使用して設計がコンパイルおよび実行されます。Pythonテストベンチバリアントを実行するには、次のコマンドを使用します:
make
make run_py
C++とPythonの両方のテストベンチバリアントは、同じinsts.binファイルと同じXCLBINファイルを使用します。
ホストコードテンプレートと設計プラクティス
すべてのホストコード設計は、同じ7つのステップに従います。設計がコンパイルされてハングしないようにするために、設計パラメータ(IN_SIZE、OUT_SIZEなど)が、構造記述ファイル、カーネルソースファイル、ホストコードファイル全体で一貫していることを確認することが重要です。これらのパラメータは通常、Makefileで定義され、必要に応じて他のファイルに渡されます。これらのパラメータが一貫していない場合、システムがハングしたり、デバッグが非常に困難な動作が発生する可能性があります。詳細については、セクション4bを参照してください。この設計例を参照として使用して、独自の設計を作成できます。
注意: より詳細な情報と完全なコード例については、公式ドキュメントを参照してください。
Section 4 - 性能測定とベクトルプログラミング
セクション3でRyzen™ AIハードウェアでのプログラムのコンパイルと実行のコンポーネントを理解したので、次は性能測定の方法と、AI Engineの並列計算能力を最大限に活用するためのベクトルプログラミング技術について見ていきます。
ベクトルプログラミングに入る前に、まず性能測定を確認することが有用です。これにより、アプリケーション性能のベースラインを得ることができます。性能に寄与する要因には、レイテンシ、スループット、電力効率など多くのものがあります。性能測定は、ユーザーがAIE上でのアプリケーションの高速化を測定するための、より強力なツールを提供する活発な研究分野です。セクション4aとセクション4bでは、タイマーとトレースの観点から性能を見ていきます。次にセクション4cでは、AIEカーネルコードのベクトル化方法をより詳しく見ていきます。
注意: 各サブセクションの詳細については、公式ドキュメントを参照してください。
Section 4a - タイマー
AMD AI Engineアクセラレータでのアプリケーション性能測定にタイマーを使用できます。このタイマーは、OS、カーネルドライバ、AIE配列への作業のディスパッチ、AIEコアでの計算など、ソフトウェアスタック全体のオーバーヘッドを含む「ウォールクロック」時間を測定します。このオーバーヘッドは含まれますが、複数回の反復を実行する場合や計算集約的なワークロードを実行する場合に、意味のある実用的な性能上限データを提供します。
アプリケーションタイマー - test.cppの修正
アプリケーションタイマーを追加するには、test.cppを修正します。chronoライブラリを使用して、カーネル関数の実行前後で時刻をキャプチャします。単一のカーネル実行の場合、次のようになります:
auto start = std::chrono::high_resolution_clock::now();
unsigned int opcode = 3;
auto run = kernel(opcode, bo_instr, instr_v.size(), bo_inA, bo_inFactor, bo_outC);
run.wait();
auto stop = std::chrono::high_resolution_clock::now();
float npu_time = std::chrono::duration_cast<std::chrono::microseconds>(stop - start).count();
std::cout << "NPU time: " << npu_time << "us." << std::endl;
複数回の反復
複数回の反復を使用すると、定常状態のカーネル実行時間をよりよくキャプチャできます。基本的なforループは次のようになります:
unsigned num_iter = n_iterations + n_warmup_iterations;
for (unsigned iter = 0; iter < num_iter; iter++) {
<... kernel run code ...>
}
ウォームアップ反復
初期のカーネル実行はしばしば起動オーバーヘッドを示すため、いくつかのウォームアップ反復を実行することをお勧めします。これにより、代表的な定常状態のタイミングを達成し、外れ値を減らすことができます。ウォームアップ反復は平均実行時間にカウントしないでください。
for (unsigned iter = 0; iter < num_iter; iter++) {
<... kernel run code ...>
if (iter < n_warmup_iterations) {
/* Warmup iterations do not count towards average runtime. */
continue;
}
<... verify and measure timers ...>
}
タイマーデータの蓄積
各反復でタイマーデータを蓄積して、平均、最小、最大の実行時間を計算できます:
for (unsigned iter = 0; iter < num_iter; iter++) {
<... kernel run code, warmup conditional, verify, and measure timers ...>
npu_time_total += npu_time;
npu_time_min = (npu_time < npu_time_min) ? npu_time : npu_time_min;
npu_time_max = (npu_time > npu_time_max) ? npu_time : npu_time_max;
}
結果の計算と出力
すべての反復を実行した後、結果を計算して出力します:
std::cout << "Avg NPU time: " << npu_time_total / n_iterations << "us." << std::endl;
std::cout << "Min NPU time: " << npu_time_min << "us." << std::endl;
std::cout << "Max NPU time: " << npu_time_max << "us." << std::endl;
カーネルのMAC(乗算累算)数がわかっている場合は、GFLOPSなどの追加の性能メトリクスを計算できます。詳細については、matrix_multiplication/test.cppを参照してください。
演習
-
test.cppをビルドして実行します(
makeとmake run)。Avg NPU timeの値はどの範囲ですか?答えを見る
答えは300-600usのどこかです -
n_iterationsを1から10に変更して再度実行します。Avg NPU timeの値はどうなりましたか?答えを見る
答えは依然として300-600usのどこかですが、以前とは異なる可能性が高いです -
n_warmup_iterationsを0から4に変更します。Avg NPU timeの値はどうなりましたか?答えを見る
今回は、300-400usの狭い範囲が表示されます -
n_iterationsを10から100に変更します。Avg NPU timeの値はどうなりましたか?答えを見る
今回は、200-300usのより低い平均範囲が表示されます
注意: より詳細な情報と完全なコード例については、公式ドキュメントを参照してください。
Section 4b - トレース
セクション4aでは、タイマーを使用した性能測定について説明しましたが、AIEハードウェアを最大限に最適化したいカーネルプログラマにとって、AIEコアとデータムーバーがどれだけ効率的に実行されているかを確認できることは重要です。AIE2トレースユニットは、サイクル精度のハードウェアイベント可視性を提供します。詳細については、AM020仕様書を参照してください。
トレースサポートを有効にする手順
- AIEトレースユニットを有効にして構成する
- トレースデータを読み取ってテキストファイルに書き込むようにホストコードを構成する
- テキストファイルを解析して波形JSONファイルを生成する
- JSONファイルをPerfettoなどの可視化ツールで開く
- 追加のデバッグヒント
1. AIEトレースユニットを有効にして構成する
トレースは、セクション3で使用したvector_scalar_mul設計(aie2.py)を例として使用します。AIE構造設計でトレースを有効にするには、Runtimeクラスでenable_traceメソッドを使用します。最も単純な形式では、トレースデータのサイズと、トレースするWorkerのリストを提供します。
rt = Runtime()
rt.enable_trace(trace_size=8192, workers=[my_worker])
または、Workerを宣言する際にtrace=1引数を使用することもできます。その場合、enable_traceメソッドにワーカーを明示的に渡す必要はありません。
# Task for the core to perform
def core_fn(of_in, of_factor, of_out, scale_scalar):
...
# Create a worker to perform the task
my_worker = Worker(
core_fn,
[of_in.cons(), of_factor.cons(), of_out.prod(), scale_fn],
trace=1,
)
rt.enable_trace(trace_size=8192)
重要: ランタイムシーケンスのenable_traceのworkers引数は、常にWorkerのtrace=1引数よりも優先されます。両方が指定されている場合、enable_traceのworkersリストに従います。
トレース動作のカスタマイズ
enable_traceメソッドには、トレース動作をカスタマイズするための追加のオプション引数があります:
trace_offset: トレースバッファのオフセット(バイト単位)。デフォルトは0。ddr_id: どのXRTバッファにトレースデータを書き込むか。デフォルトは7(XRT group_id 7)。coretile_events: コアタイルで監視する8つのイベント。memtile_events: メモリタイルで監視する8つのイベント。shimtile_events: シムタイルで監視する8つのイベント。
カスタムトレース設定の例:
from aie.extras.dialects.ext.arith import constant
from aie.dialects.aie import *
rt = Runtime()
rt.enable_trace(
trace_size=16384,
workers=[my_worker],
trace_offset=0,
ddr_id=7,
coretile_events=[
CoreEvent.INSTR_EVENT_0,
CoreEvent.INSTR_EVENT_1,
CoreEvent.INSTR_VECTOR,
CoreEvent.PORT_RUNNING_0,
CoreEvent.PORT_RUNNING_1,
CoreEvent.PORT_RUNNING_2,
CoreEvent.PORT_RUNNING_3,
CoreEvent.PORT_RUNNING_7,
],
)
トレース可能なイベントの完全なリストについては、README-placed.mdを参照してください。
2. トレースデータを読み取ってテキストファイルに書き込むようにホストコードを構成する
AIE構造設計コード(aie2.py)
ホストコードを理解するには、まずAIE構造設計が何を生成するかを理解する必要があります。aie2.pyでトレースを有効にすると(enable_traceの呼び出しによって)、XRTバッファ(BO)の1つがトレースデータの書き込み用に予約されます。enable_traceのddr_idパラメータで、どのXRTバッファを使用するかを指定します。デフォルトはXRT group_id 7(またはinout4)です。この設計例では、inout0からinout4までの5つのXRTバッファ(group_id 3から7)が利用可能です。
XRTバッファマッピング
| XRTバッファインデックス | XRT group_id | 設定されたグローバルバッファ名 |
|---|---|---|
| inout0 | 3 | N/A |
| inout1 | 4 | N/A |
| inout2 | 5 | N/A |
| inout3 | 6 | N/A |
| inout4 | 7 | N/A |
デフォルトでは、すべてのXRTバッファは使用可能で、設定されたグローバルバッファがないため、ランタイムシーケンスで使用される順序に基づいてマッピングされます。test.cppでは、ランタイムシーケンスは次のようになります:
with rt.sequence(tensor_ty, scalar_ty, tensor_ty) as (inp, factor, out):
rt.start(my_worker)
rt.fill(of_in.prod(), inp)
rt.fill(of_factor.prod(), factor)
rt.drain(of_out.cons(), out, wait=True)
最初の引数が最初の使用可能なXRTバッファ(group_id 3)にマッピングされます。2番目の引数はgroup_id 4に、3番目はgroup_id 5にマッピングされます。このマッピングは以下のようになります:
| XRTバッファインデックス | XRT group_id | 設定されたグローバルバッファ名 | ランタイムシーケンス引数 |
|---|---|---|---|
| inout0 | 3 | N/A | inp(入力ベクトル) |
| inout1 | 4 | N/A | factor(スカラー係数) |
| inout2 | 5 | N/A | out(出力ベクトル) |
| inout3 | 6 | N/A | N/A |
| inout4 | 7 | N/A | trace(トレースバッファ) |
2a. C/C++ホストコード
test.cppでは、トレース用の追加のXRTバッファオブジェクトを作成する必要があります。これは他の入出力バッファと同じように作成されますが、group_idは7(inout4)を使用します:
size_t tmp_trace_size = trace_size;
if (tmp_trace_size < TRACE_SIZE_MIN)
tmp_trace_size = TRACE_SIZE_MIN;
auto bo_trace = xrt::bo(device, tmp_trace_size, XRT_BO_FLAGS_HOST_ONLY, kernel.group_id(7));
char *bufTrace = bo_trace.map<char *>();
memset(bufTrace, 0, tmp_trace_size);
bo_trace.sync(XCL_BO_SYNC_BO_TO_DEVICE);
...カーネル実行...
bo_trace.sync(XCL_BO_SYNC_BO_FROM_DEVICE);
トレースバッファをデバイスから同期した後、テキストファイルに書き出します:
test_utils::write_out_trace((char *)bufTrace, trace_size, trace_file);
Makefileでのバッファサイズ設定
Makefileでは、トレースサイズと他のバッファサイズがCMakeに渡されます:
trace_size ?= 8192
M ?= 512
K ?= 512
N ?= 512
データ型の一貫性
Pythonのaie2.pyで定義されたデータ型は、test.cppのデータ型と一致する必要があります。
Python(aie2.py):
tensor_ty = np.ndarray[(tensor_size,), np.dtype[np.int32]]
C++(test.cpp):
using DATATYPE = std::int32_t;
バッファの初期化と検証
test.cppでは、トレースデータをキャプチャしながら、CMakeLists.txtで定義されたバッファサイズとデータ型に基づいてバッファを初期化し、検証します:
DATATYPE *bufInA = bo_inA.map<DATATYPE *>();
std::vector<DATATYPE> AVec(IN_SIZE);
for (int i = 0; i < IN_SIZE; i++)
AVec[i] = i + 1;
memcpy(bufInA, AVec.data(), (AVec.size() * sizeof(DATATYPE)));
DATATYPE *bufInFactor = bo_inFactor.map<DATATYPE *>();
bufInFactor[0] = 3;
DATATYPE *bufOut = bo_outC.map<DATATYPE *>();
bo_inA.sync(XCL_BO_SYNC_BO_TO_DEVICE);
bo_inFactor.sync(XCL_BO_SYNC_BO_TO_DEVICE);
bo_outC.sync(XCL_BO_SYNC_BO_TO_DEVICE);
...カーネル実行...
bo_outC.sync(XCL_BO_SYNC_BO_FROM_DEVICE);
bool pass = true;
for (uint32_t i = 0; i < IN_SIZE; i++) {
int32_t ref = bufInA[i] * 3;
if (*(bufOut + i) != ref) {
std::cout << "Error in output " << *(bufOut + i) << " != " << ref << std::endl;
pass = false;
}
}
std::cout << (pass ? "PASS!" : "FAIL.") << std::endl;
ビルド
make
make run
2b. Pythonホストコード
Pythonホストコードの場合、test.pyでトレースバッファを登録し、xrt.pyのユーティリティ関数を使用してトレースデータを処理します。トレースバッファは、register_bufferメソッドを使用してAppに登録されます:
app.register_buffer(7, shape=trace_buf_shape, dtype=trace_buf_dtype)
トレースバッファをファイルに書き出すには:
trace_buffer = trace_buffer.view(np.uint32)
write_out_trace(trace_buffer, str(opts.trace_file))
3. テキストファイルを解析して波形JSONファイルを生成する
ホストコードがトレースをテキストファイル(例:trace.txt)に書き出した後、parse_trace.pyを使用してJSONファイルに変換します。このスクリプトはutilsディレクトリにあり、Makefileターゲット経由で呼び出すことができます:
trace:
../../python/parse_trace.py --filename trace.txt --mlir build/aie_trace.mlir --colshift 1 > trace_4b.json
parse_trace.pyの詳細については、utils READMEを参照してください。または、トレースの要約を取得するためにget_trace_summary.pyを使用することもできます。
4. JSONファイルをPerfettoなどの可視化ツールで開く
JSONファイルが生成されたら、Perfettoなどの可視化ツールで開くことができます。PerfettoのUIでは、A/Dキーでパン、W/Sキーでズームできます。
追加のデバッグヒント
-
トレースファイルが空の場合:
enable_traceのXRTバッファがtest.cppの対応するgroup_idと一致していることを確認してください。デフォルトはgroup_id 7(またはinout4)です。 -
読み取り可能なトレースデータが非常に少ない場合: コアの設計が最小限のイベントしか生成しない可能性があります。その場合、ShimTileも追加してトレースしてください。または、DMAバースト長を64Bに削減して、より頻繁なイベントを生成してみてください。
-
トレースオフセットの設定: トレースバッファを別のバッファと共有する場合、
trace_offsetを適切に設定してください。通常、trace_offsetは他のバッファのサイズと等しくなります。 -
マルチコア設計でのタイルのトレースルーティング: マルチコア設計では、各タイルからそのシムDMAへの接続を確認してください。
-
colshift: Phoenixデバイスの場合は
colshift=1、Strixデバイスの場合はcolshift=0を使用してください。 -
XRTバッファの割り当て: トレースサイズの4倍でXRTバッファを割り当てることをお勧めします。これは間欠的な問題を回避するための実験的な回避策です。
-
トレースデータの解析が失敗する場合: trace_events_enum.pyでイベントが正しく定義されているか確認してください。
演習
-
test.cppをビルドして実行します(
makeとmake run)。次に、make traceを実行してトレースJSONファイルを生成します。https://ui.perfetto.devでtrace_4b.jsonを開きます。以下のスクリーンショットのような波形が表示されるはずです。A/Dキーでパン、W/Sキーでズームできます。
-
トレースには、コアとDMAのイベントの混合が表示されます。一般的なトレースイベントには以下が含まれます:
INSTR_EVENT_0とINSTR_EVENT_1(カーネルの開始と終了をマークする)、INSTR_VECTOR(ベクトル演算の実行)、PORT_RUNNING_0からPORT_RUNNING_7(ポートアクティビティ)、LOCK_STALL、INSTR_LOCK_ACQUIRE_REQ、INSTR_LOCK_RELEASE_REQ(ロック操作)などがあります。トレースイベントの完全なリストについては、trace_events_enum.pyを参照してください。 -
波形を見て、以下の質問に答えてください:
a. カーネルはどのくらい実行されましたか(
INSTR_EVENT_0からINSTR_EVENT_1まで)?答えを見る
約1500サイクルb. ポート0の実行とポート1の実行の間にはどのような関係がありますか?これらのポートは何を表していますか?ヒント:ポート0と1は通常、DMAチャネル0と1に対応します。aie2.pyで、DMAチャネルの設定方法を確認してください。
of_in = ObjectFifo(tile_ty, name="in") # DMAチャネル0 of_out = ObjectFifo(tile_ty, name="out") # DMAチャネル1答えを見る
ポート0(入力DMA)とポート1(出力DMA)は同時に実行され、データフローパイプラインを示しています
注意: より詳細な情報と完全なコード例については、公式ドキュメントを参照してください。
Section 4c - カーネルのベクトル化と最適化
アプリケーション全体の実行時間を測定する方法(セクション4a)を学び、トレースを使用してカーネル性能を確認する方法(セクション4b)を見てきました。次は、カーネルのベクトル化をより詳しく見て、トレースを使用して性能を比較します。カーネルのベクトル化の概念を説明するために、以前のセクション4の例のローカルコピーではなく、ベクトルスカラー乗算の例に切り替えます。なお、このデザイン例はデフォルトで16ビットデータを使用しており(以前のセクション4の例では32ビット)、vectorized=Trueに設定されています。
まずベクトルスカラー乗算のデザイン例の概要を読んで、この例のさまざまなコンポーネントのアイデアを把握してください。次に、カーネルソースファイル(scale.cc)をより詳しく見てみましょう。
scale.ccでは、スカラーコードが比較的単純で、セクション4bで使用したスカラーコードに似ていることがわかります:
template <typename T>
void scale_scalar(T *a, T *c, T factor, const int32_t N) {
event0();
for (int i = 0; i < N; i++) {
c[i] = factor * a[i];
}
event1();
}
ここでは、コードが入力ベクトル(a)を反復処理し、ベクトルの各要素をスカラー値(factor)で乗算してから、結果を出力ベクトル(c)に格納します。このシンプルなC/C++コードは、forループと、ループ内の単純な読み取りとスカラー乗算演算で構成されています。
AIE API
これをベクトル化するには、まずAIE APIに慣れる必要があります。AIE APIは、基礎となるAIEプロセッサと関連する低レベルイントリンシクスを、より高レベルのC++ APIで抽象化します。AIE API(2023.2 Vitisツール)のドキュメントはこちらにあります。ベクトル×スカラー乗算の詳細を表示するには、左側のペインでAI Engine API User Guide -> API Reference -> Arithmeticに移動し、最初のaie::mulを選択します。これはVec * Eを示しており、Eはスカラーintのような基本データ型です。
カーネルコードでこのAIE API関数を使用できるようにするには、まずカーネルソースにAIE APIヘッダーをインクルードする必要があります。
#include <aie_api/aie.hpp>
ベクトルレジスタ
次に、ベクトルを次のように宣言します:
aie::vector<T, vec_factor> my_vector
- T -
int16_tなどのデータ型 - vec_factor - ベクトル化ファクタまたはベクトルサイズ(例:32)
ベクトルのサイズは型によって異なります。たとえば、AIE2の標準ベクトルレジスタは512ビットです。int16_tの場合、1つの512bベクトルレジスタに32個格納できます。これを他のサポートされているデータ型に拡張すると、次の簡略表があります:
| データ型 | ベクトルサイズ |
|---|---|
| int32_t | 16 |
| int16_t | 32 |
| int8_t | 64 |
| int4_t | 128 |
サポートされているベクトルのより完全な表は、AIE APIユーザーガイドのこちらにあります。リストされているデータ型×ベクトルサイズが512ビットより大きい場合は、1つではなく2つ以上のベクトルレジスタに格納されることに注意してください。
ベクトルロード
ローカルL1メモリからaie::load_v関数を使用してベクトルレジスタをロードできます。次のように定義されます:
T *__restrict pA1 = a;
aie::vector<T, vec_factor> A0 = aie::load_v<vec_factor>(pA1);
ここでは、__restrictを使用してポインタを修飾し、そのポインタが基礎となるオブジェクトにアクセスする唯一のものであることを示します。これにより、ポインタエイリアシングの可能性が排除され、コンパイラによるより優れた最適化が可能になります。
ベクトルロードには、aie::vector宣言で使用されるものと一致するテンプレート引数vec_factorがあります。
ベクトル乗算とストア
最後に、ベクトルとスカラーを引数として受け取るaie::mul呼び出しに到達し、結果を次のように指定されたアキュムレータレジスタに格納します:
aie::accum<acc32, vec_factor> cout
この場合のアキュムレータデータ型は、32個の32ビットアキュムレータです。ベクトルストア関数aie::store_vを使用して、アキュムレータから計算された結果をローカルメモリに格納します。int32_tデータ型の入力引数を使用した乗算または加算には、16個の出力レーンしかない、より大きな64ビットアキュムレータ(acc64)が必要になることに注意してください。
T *__restrict pC1 = c;
aie::store_v(pC1, cout.template to_vector<T>(0));
ここで、アキュムレータ型は.template to_vector<T>(0)呼び出しを使用してベクトルレジスタにシフト-ラウンド-飽和できます。ここでTはベクトルレジスタ型で、単一の整数引数(0)はシフト量です。
ベクトルブロック全体は次のようになります:
template <typename T>
void scale_vectorized(T *a, T *c, int32_t factor, const int32_t N) {
event0();
constexpr int vec_factor = 32;
T *__restrict pA1 = a;
T *__restrict pC1 = c;
const int F = N / vec_factor;
T fac = factor;
AIE_PREPARE_FOR_PIPELINING
AIE_LOOP_MIN_ITERATION_COUNT(16)
for (int i = 0; i < F; i++)
{
aie::vector<T, vec_factor> A0 = aie::load_v<vec_factor>(pA1);
pA1 += vec_factor;
aie::accum<acc32, vec_factor> cout = aie::mul(A0, fac);
aie::store_v(pC1, cout.template to_vector<T>(0));
pC1 += vec_factor;
}
event1();
}
この例では、ベクトル化戦略は比較的単純でした。値のベクトルを反復処理して単一のスカラー乗算を行う代わりに、入力値のベクトルをロードし、より小さいループ(ベクトル化ファクタで除算)を反復処理してAIE API関数を使用してベクトル×スカラー演算を実行し、結果のベクトルをローカルメモリに戻します。
注意 - AIE APIは、世代固有の効率的な低レベルイントリンシクスに変換される型と演算を提供する、C++ヘッダーオンリーライブラリとして実装されたポータブルプログラミングインターフェースです。AIEカーネルは、これらの低レベルC++イントリンシクスで直接プログラムすることもできます:AIE1 Intrinsics User Guide - v2023.2およびAIE2 Intrinsics User Guide - v2023.2
ベクトル化演習
-
ベクトルスカラーデザインのトレースを見てみましょう。まず、vector_scalar_mul designを編集して、vector_scalar_mul.pyソースファイルで
vectorized=Falseに設定します。vector_scalar_mul.pyソースコードで、カーネル関数のスカラーバージョンを選択しました。また、環境変数int_bit_width=32をmakefileコマンドに渡すことで、デザインの32ビット整数バージョンをビルドします(make int_bit_width=32 traceを実行)。このmakefile引数は、デザインコード(vector_scalar_mul.py)とホストコード(test.cpp)のデータ型とバッファサイズをカスタマイズするためにmakefileで定義されています。トレースコンパイルが完了したら、https://ui.perfetto.dev でtrace_vector_scalar_mul.jsonを開き、event 0とevent 1の間のデルタを測定します。Perfetto波形では、1 usが1クロックサイクルに等しいことに注意してください。何サイクル測定しましたか?答えを見る
約12,297サイクルvector_scalar_mulの例では、python/utils/get_trace_summary.pyを呼び出して、生成されたjsonファイルを自動的に分析し、event 0とevent 1の間のデルタを測定し、カーネル呼び出しの数、および最初/最小/平均/最大サイクル数を提供していることに気付くかもしれません。これは、シングルコア設計のカーネル性能を要約するための便利なユーティリティです。 -
次に、
vectorized=Trueに変更してベクトル化を有効にします。ただし、その効果を確認するために、最初にプラグマガイド付き最適化を無効にします。scale.ccで、for loopの前にあるAIE_PREPARE_FOR_PIPELINING AIE_LOOP_MIN_ITERATION_COUNT(16)という行をコメントアウトします。注意 次にそのケースをテストするため、一般的なテンプレートとint32_tテンプレートの特殊化の両方を編集してください。次に、コンパイルを再実行します(make clean; make int_bit_width=32 trace)。再びevent 0とevent 1の間のデルタを測定します。今度は何が表示されますか?答えを見る
約1490サイクルかなりの改善です。計算レイテンシが約8倍削減されました。ただし、ベクトルコードでさらに最適化できることがあり、それには最適化プラグマが含まれます。
-
scale.ccに戻り、
AIE_PREPARE_FOR_PIPELINING AIE_LOOP_MIN_ITERATION_COUNT(16)の行のコメントを外してこれらのプラグマを有効にします。次に、コンパイルを再実行します(make clean; make int_bit_width=32 trace)。再びevent 0とevent 1の間のデルタを測定します。今度は何が表示されますか?答えを見る
339サイクル今、本当に大きな節約が見られます(さらに約4倍の節約、またはスカラーバージョンと比較して約36倍)。追加した行は、コンパイラが最適なスケジュールを見つけるのに役立ちます。カーネルループの場合、
AIE_PREPARE_FOR_PIPELININGとAIE_LOOP_MIN_ITERATION_COUNT(16)が特に役立ちます:AIE_PREPARE_FOR_PIPELINING- 最内ループで使用して、ソフトウェアパイプライニングを有効にするようコンパイラに指示します。これは、後続のループ最適化プラグマを有効にするために必要です。AIE_LOOP_MIN_ITERATION_COUNT(MIN)- 非常に役立つプラグマです。これは、このループが持つと予想される最小反復回数をコンパイラに伝えます。最小反復回数と最大反復回数の両方を指定したい場合は、, AIE_LOOP_RANGE(MIN,MAX)を使用できます。多くの場合、サイズに基づいてループ境界をパラメータ化し、ループサイズがconstとして宣言されていても、それは依然としてランタイムで計算される値です。このプラグマでMIN値を指定すると、反復回数がわかるため、スケジューラがそのガイドとなり、最悪の場合の1ではなく、その数に対してループ命令を適切にスケジュールできるため、特に役立ちます。
-
最後に、ベクトル化を有効にし、カーネルコードの最適化プラグマを有効にした状態で、デザインの16ビット整数バージョンでコンパイルを再実行します。これは
vector_scalar_mulデザインのデフォルト設定です(make clean; make trace)。再びevent 0とevent 1の間のデルタを測定します。今度は何が表示されますか?答えを見る
78サイクル反復ごとに2倍のデータを処理でき、反復ごとに必要なベクトル乗算が少なくて済むため、さらに4倍の改善が見られ、スカラーバージョンから合計約157倍の改善が得られました。
最適化 - アーキテクチャを考慮したコーディング
この時点で、AIEハードウェアをより有効に活用するためにコードをベクトル化し、大幅な性能向上を確認しましたが、デザインは完全に最適化されていますか?強力なAIEハードウェアをそのフルポテンシャルまで使用したかどうかをどのように知るのでしょうか?これには、基礎となるAIEアーキテクチャのより深い理解と、ハードウェアを念頭に置いた性能のためのコーディングが必要です。この次のセクションでは、Ryzen™ AI NPUの中核にあるAIE2(別名AIE-ML)に焦点を当てます。AIE2はMLワークロードに最適化されています。つまり、行列乗算スタイルの計算のような乗算累算演算がハードウェアを最もよく活用します。また、ベクトルスカラー乗算の例を続けて探索を開始します。すべての最適化を活用するのに十分な計算量を公開していませんが、最適なデザインをコーディングするために必要な設計上の考慮事項を理解するための良い出発点を提供します。
ベクトルユニット - ロード
コードをさらに最適化する最初のステップは、AIEベクトルユニットの全体像を持つことです。これはAIE-MLアーキテクチャマニュアル(am020)にあります。以下は、マニュアルからのベクトルユニットの図です。

ご覧のとおり、ベクトルレジスタは2つの並列ロードユニットからロードされ、それぞれがローカルL1メモリからクロックサイクルあたり256ビットをロードできます。12個の512ビットベクトルレジスタがあり、各Permuteブロックに供給され、最終的にMultiplierブロックに供給されます。したがって、クロックサイクルあたり2×256ビットの並列ロードの観点から常に考えることが重要です。たとえば、計算を行うためにクロックあたり2048ビットのデータをロードしようとすると、複数のサイクルが必要になるため、効率が低下します。もう1つの重要な注意点は、ロードは異なるL1メモリバンクから行う必要があることです。そうしないと、バンク競合が発生します。バンク競合のペナルティは1サイクルですが、最適な性能が低下します。
ベクトルユニット - 乗算と加算(MAC)
データがロードされて並べ替えられると、幅広いAIEデータ型をサポートするMultiplierブロックに渡されます。乗算結果は、オプションのポスト加算ステップ(行列乗算で非常に一般的)を通過してから、最終的にアキュムレータレジスタに格納されます。9個の512ビットアキュムレータレジスタがあります。アキュムレータレジスタはより大きいため、データ精度を維持できます。適切に最適化されたコードは、サイクルごとに1つのベクトルMAC(VMAC)をスケジュールするよう努力します。
ベクトルユニット - SRSとストア
データが計算されると(1サイクルで、または複数のサイクルにわたって累算されて)、結果はStore Unitを介してローカルL1メモリに書き戻すことができます。これは2つのロードユニットを反映していますが、ストアユニットは1つだけです。アキュムレータレジスタとベクトルレジスタまたはローカルL1メモリの間のブリッジングには、SRSユニット(shift-round-saturate)を利用します。これは、多数の設定可能な丸めおよび飽和モードを使用してシフト、丸め、飽和を行います。

SRSパスは上図の右側にあり、相関するパスであるUpshift(UPS)パスは左側にあります。Upshiftはベクトルレジスタからアキュムレータレジスタにデータを移動します。
ベクトルユニット - Shift/Shuffle/Adderパス
最後に、シフト、シャッフル、単純な加算、比較、およびその他の多数のベクトル関数を実行する追加の並列処理パスがあります。このパスは、メイン整数ベクトルデータパスと並行して実行され、VMACデータパスを必要とせずに前述の関数を実行するようにタスク化される場合があります。

この処理データパスと、データがローカルメモリとの間でロードおよび格納される方法を念頭に置いておくことは非常に役立ちます。次のステップは、アプリケーションで理想的な性能にどれだけ近いかを確認し、結果をより詳細に調べて、改善できる場所をよりよく理解することです。
乗算器の利用効率
アーキテクチャをよりよく理解したので、ハードウェア効率をより詳しく見てみましょう。次の図は、説明したさまざまなAIEアーキテクチャブロックと、一般化された計算の表を示しています。

注意 - 行列乗算モードの表は、AIE APIユーザーガイドのこちらにあります。さまざまなビット精度の合計MAC数を確認する別の方法は、AM020仕様の
Table: Supported Precision Width of the Vector Data Pathです。
この表は、16ビット×16ビット計算の場合、サイクルあたり64個のMACが利用可能であることを示しています。ただし、これらのMACは行列乗算(付随するポスト加算ステップを含む)を対象としています。実際には、32個のアキュムレータレーンが利用可能です。つまり、要素ごとの演算の場合、サイクルあたり32個のMACしか使用できません。
MAC効率
この情報とベクトルスカラー乗算の例を使用すると、カーネルへの各呼び出しが1024個の16ビットデータの配列を渡すことがわかります。32個のMACが利用可能で、vector_factorは32であるため、32 MACsパークロック要素ごとのベクトルMAC構成を考えると、このデータ量を処理するために理想的には1024 / 32 = 32サイクルが必要です。カーネルの最終的な最適化されたサイクルカウントは72サイクルで、理想的なサイクル数の約2倍です。
合計MAC効率は、(MACスケジュール効率)×(クロックあたりのMAC利用効率)の積です。
- (MACスケジュール効率または理想的なMACサイクル)/(実際のMACサイクル)、例:32/ 72 = 44%
- (クロックあたりのMAC利用効率または使用されたMACの数)/(利用可能なMACの総数)、例:32/ 64 = 50% したがって、合計MAC効率は44% × 50% = 22%です。
この結果をファイルしておきますが、ロード/ストア帯域幅の観点からアルゴリズムを見てみましょう。
ロード/ストア帯域幅効率
32個のint16値のベクトルにスカラーを乗算して処理するには、スカラーロードを無視して、ベクトルのみに焦点を当てましょう。32 int16 = 512ビットで、2×256ビットロードまたは2サイクルかかります。データがバンク間でインターリーブされている場合、1サイクルで実行できる可能性があります。また、2×256ビットを格納する必要があり、ストアユニットが1つしかないため、2サイクルかかります。つまり、サイクルごとにVMACを実行できたとしても、入力をロードするために2サイクル、出力を格納するために2サイクルが必要です。この2サイクル要件に基づいて、データサイズの最小サイクルが64サイクルであるため、最適化されたベクトル結果が72である理由がわかります。残りの6サイクルは、ループプリアンブル、ループポストアンブル、および関数の初期化とクリーンアップのオーバーヘッドです。
データルーティング効率
ロード/ストア帯域幅は、16ビットベクトルスカラー乗算の例では、計算にとって既にボトルネックです。しかし、ストリームとDMAを介したデータ移動についてはどうでしょうか。1024チャンクの16ビットデータ、または512個の32ビット量を処理する必要があります。ストリームスイッチが32ビット粒度でデータを移動するため、データをL1にロードし、L1からL2/L3にデータを移動するには512サイクルが必要です。
ハードウェア効率の要約
| コンポーネント | サイクル数 | 効率 |
|---|---|---|
| MAC | 72 | 22% |
| ロード/ストア | 64 | 50% / 100% |
| DMA | 512 | 100% |
この表を見ると、データ移動が全体的なカーネルのボトルネックであることがすぐにわかります。
最適化演習 - パート1
-
最終的な最適化されたコードを再実行して、結果の波形を見てください。

PortRunning0とPortRunning1のブロックにマウスを合わせると、チャンクあたりの測定サイクル数はどれくらいですか?
答えを見る
512サイクルこれは期待どおりです。ただし、計算と比較してデータ移動がどれほど支配的であるかが波形から明らかであることに注意してください。
-
デザインがデータ移動と計算の間で不均衡であることは既にわかっています。計算に72サイクル、データ移動に512サイクルがあります。行列乗算の例を見て、改善できるかどうかを確認しましょう。説明では、カーネルの各反復がデフォルトで64x64x64のMxKxN値に対して構成されており、262,144個のMACが得られることが説明されています。
int16_tデータ型を使用しており、クロックあたり64個のMACがある場合、理想的なケースは何サイクルかかりますか?答えを見る
2048サイクル = 262,144 / 64AとB行列はそれぞれ64x64 ×
int16_tで、ストリームスイッチチャネルは32ビット幅です。計算タイルにデータを移動するのに何サイクルかかりますか(AとBは別々のチャネルを介して並行して移動できることに注意してください)。答えを見る
2048サイクル = 64x64 / 2 -
この例は、計算とデータ移動の間で完全にバランスが取れているはずです!行列乗算の例に移動して、トレースビルドを実行します(
make clean; make -f Makefile.chess use_placed=1 trace)。次に、生成された波形json(trace_mm.json)を開き、最初の実行でevent 0とevent 1の間のデルタを測定します。どんな値が得られましたか、そしてそれは理想にどれほど近いですか?答えを見る
約2535サイクル、これは2048の80%です計算サイクルとデータ移動サイクルがはるかに近く一致していることがわかるはずです!
深く掘り下げる - マイクロコードの検査
vector_scalar_mul designの結果をもう一度見てみましょう。また、1ステップ戻ってAIE_PREPARE_FOR_PIPELINING AIE_LOOP_MIN_ITERATION_COUNT(16)をコメントアウトし、コンパイルを再実行します(make clean; make trace)。
この時点で、実際に逆アセンブリコードを見ることができます。逆アセンブリは、カーネルプログラムを実行するためにAIEが実行する正確な命令のスケジュールです。逆アセンブリを取得するには、生成されたオブジェクトまたはelfファイルでllvm-objdumpを実行できます。
<mlir-aie>/ironenv/lib/python<ver>/site-packages/llvm-aie/bin/llvm-objdump -dr build/core_0_2.elf > disassembly_0_2.txt
elfファイルの場合、命名にはcore名が含まれ、コアの2つの数字はそれぞれ列と行の位置を示します。したがって、デザインに複数のコアがある場合、各コアには逆アセンブルできる独自の.elfファイルがあります。逆アセンブリファイルを生成して開くと、多くの情報が表示されます。コメント行の前には.があります。他の行は命令であり、次のように構成されています:
命令行番号 ---- エンコードされた命令 ---- 1つ以上のスロットのISAコマンド
| ISAコマンドの例 | 説明 |
|---|---|
| NOP .. | No op |
| JL #XXX | 命令行番号#にジャンプしてリンク |
| MOV r1, r2 | レジスタ値をr2からr1に移動 |
| LD .. | スカラーロード |
| ST .. | スカラーストア |
| VLDA | ベクトルロードユニットA |
| VLDB | ベクトルロードユニットB |
| VMUL .. | ベクトル乗算 |
| VMAC .. | ベクトル乗算累算 |
| VST .. | ベクトルストア |
| VSRS .. | ベクトルSRS |
| VSHUFFLE .. | ベクトルシャッフル |
このマイクロコードを完全に分析して理解することは、このプログラミングガイドの範囲を超えていますが、特に3種類のコメントでラベル付けされたこのマイクロコードの主要部分に焦点を当てます:
<8桁の数字> <label> ここで<label>は<main>または<vector_scalar_mul_vector>のような関数名です - 関心のある関数の開始。
<8桁の数字> <.LBB?_?>: - ゼロオーバーヘッドループの開始。
<8桁の数字> <.L_LEnd?> - ゼロオーバーヘッドループの終了。
注意 このラベルの後の行がループ内の最後の行であり、
<.LBB?_?>と.L_LEnd?の間の行だけではありません。一般に、ラベルはラベルの後の行に対するものです。
例でこれをより詳しく調べてみましょう。
最適化演習 - パート2
-
戻ってプラグマ行(
AIE_PREPARE_FOR_PIPELINING AIE_LOOP_MIN_ITERATION_COUNT(16))を再度コメントアウトし、ビルドを再実行します(make clean; make trace)。逆アセンブラを実行してdisassembly_0_2.txtを開き、ファイルを見てください。vector_scalar_mul_vectorを検索します。次に、その後の最初のLBB行が表示されるまでスクロールダウンします。次のLBBまたはL_LEnd行に到達するまでの行数をカウントします。次の行がL_LEndの場合は、合計カウントに1を追加してください。この内部ループには何行ありますか?答えを見る
9サイクル -
次に、各行を見て、
VMULまたはVMACを含む行がいくつあるかをカウントします。どんな数字が得られますか?答えを見る
VMULは1つだけ -
得られた数値は、アルゴリズムの最内ループがどれほど最適化されているかの大まかなアイデアを提供します。この場合、9サイクル中1つのVMACがあり、MAC利用率は約11%です。内部ループが11サイクルかかり、32回反復する場合、このバージョンは何サイクルかかり、測定されたサイクルカウントにどれだけ近いですか?
答えを見る
11*32=352サイクル、測定された約309サイクルのうち。かなり近いです。オーバーヘッドは約15サイクルです -
次に、戻ってプラグマ行を再度コメント解除し、ビルドとクリーンアップスクリプトを再実行します(
make clean; make trace; <mlir-aie>/ironenv/lib/python<ver>/site-packages/llvm-aie/bin/llvm-objdump -dr build/core_0_2.elf > disassembly_0_2.txt)。再びvector_scalar_mul_vectorを検索し、内部ループの行数とVMUL/VMAC行を再度カウントします。何が見えますか?答えを見る
内部ループ行は2行。VMULは1つ。これは、ベクトルストアのために内部ループが2に制限されているという手計算と一致します。
注意: より詳細な情報、完全なコード例、および高度な最適化技術については、公式ドキュメントを参照してください。
Section 5 - ベクトル設計の例
プログラミング例は、Ryzen™ AIのAI EngineとNPU配列の独自機能をさらに説明するための多数のサンプル設計です。
最もシンプルな例
Passthrough
passthrough例は、最もシンプルな「入門」例です。ベクトル化されたロードとストアを使用して、入力から出力へ4096バイトをコピーします。この設計例は、他の例でも簡単に再現できる典型的なプロジェクト構成を示しています。ここで重要なファイルは実質4つだけです。
passthrough_kernel.py- 外部メモリに接続されたシムタイルと、コピーを実行する単一のAIEコアを含むAIE構造設計。セクション2で説明されているObject FIFOの簡単な使用例も示しています。passthrough.cc- ベクトル化されたコピー操作を実行するC++ファイル。test.cppまたはtest.py- 設計を実行し、CPUリファレンスと比較するためのC++またはPythonメインアプリケーション。Makefile- 様々なアーティファクトのビルドプロセスを文書化(および実装)するMakefile。
passthrough DMAs例は、コアを使わずにループバックを実行してコピーを行う別の方法を示しています。
基本設計
| 設計名 | データ型 | 説明 |
|---|---|---|
| Vector Scalar Add | i32 | ベクトルの各要素に1を加算 |
| Vector Scalar Mul | i32 | ベクトルにスケールファクタを乗算 |
| Vector Vector Add | i32 | 2つのベクトルを加算 |
| Vector Vector Modulo | i32 | ベクトル同士の剰余演算 |
| Vector Vector Multiply | i32 | 2つのベクトルの要素ごとの乗算 |
| Vector Reduce Add | bfloat16 | ベクトルの全要素の合計値を返す |
| Vector Reduce Max | bfloat16 | ベクトルの全要素の最大値を返す |
| Vector Reduce Min | bfloat16 | ベクトルの全要素の最小値を返す |
| Vector Exp | bfloat16 | 入力のexを表すベクトルを返す |
| DMA Transpose | i32 | npu_dma_memcpy_ndを使用してShim DMAで行列を転置 |
| Matrix Scalar Add | i32 | 行列とスカラーの乗算 |
| Single core GEMM | bfloat16 | 単一コアの行列-行列乗算 |
| Multi core GEMM | bfloat16 | オペランドブロードキャストを使用した16個のAIEによる行列-行列乗算。シンプルな「その場で累積」戦略を使用 |
| GEMV | bfloat16 | ベクトルを返すベクトル-行列乗算 |
機械学習カーネル
| 設計名 | データ型 | 説明 |
|---|---|---|
| Eltwise Add | bfloat16 | 2つのベクトルの要素ごとの加算 |
| Eltwise Mul | i32 | 2つのベクトルの要素ごとの乗算 |
| ReLU | bfloat16 | ベクトルに対する正規化線形ユニット(ReLU)活性化関数 |
| Softmax | bfloat16 | 行列に対するSoftmax演算 |
| Conv2D | i8 | CNN用の単一コア2次元畳み込み |
| Conv2D+ReLU | i8 | ベクトルレジスタレベルでReLUが融合されたConv2D |
演習問題
-
passthrough設計を変更して、より多く(または少なく)データをコピーできますか?
答えを見る
Makefileを確認してください。in1_sizeとout_sizeを変更します。 -
Vector Exp例のtest.cppのテストベンチを見てください。データ型とテストベクトルのサイズに注目してください。何に気づきますか?
答えを見る
65536個の値、つまり2^16個をテストしています。したがって、すべての可能なbfloat16値を近似を通してテストしています。 -
ReLUにおける通信対計算比は何ですか?
答えを見る
トレースによると約6です。これが、Conv2DやGEMMとのカーネル融合が機械学習において有効な理由です。 -
難問 どの基本例がSoftmaxのコンポーネントになっていますか?
答えを見る
Vector Exp
Section 6 - 大規模設計の例
Ryzen™ AIのAI EngineとNPU配列の独自機能をさらに説明するための多数の設計例が利用可能です。このセクションでは、ビジョンと機械学習のユースケース向けの、より複雑なアプリケーション設計を紹介します。特に、Ryzen™ AI上のResNet実装について説明します。
ビジョンカーネル
| 設計名 | データ型 | 説明 |
|---|---|---|
| Vision Passthrough | i8 | 1つのpassThroughカーネルのみを含むシンプルなパイプライン。このパイプラインは主に、グレースケール画像をコピーするためのデータ移動が正しく動作するかをテストすることを目的としています。 |
| Color Detect | i32 | マルチカーネル、マルチコアパイプラインで、RGBA画像内の色を検出します。 |
| Edge Detect | i32 | マルチカーネル、マルチコアパイプラインで、画像内のエッジを検出し、元の画像に検出結果を重ね合わせます。 |
| Color Threshold | i32 | RGBA画像のカラーしきい値処理のマルチコア、データ並列実装。 |
機械学習設計
| 設計名 | データ型 | 説明 |
|---|---|---|
| bottleneck | ui8 | ボトルネック残差ブロックは、1x1、3x3、1x1のフィルタサイズを使用する3つの畳み込みを利用する残差ブロックの変種です。この実装は、複数のカーネルの融合とデータフロー最適化を特徴とし、AI Engineの独自のアーキテクチャ機能を強調しています。 |
| resnet | ui8 | conv2_x層をオフロードしたResNet。この実装は、複数のNPU列にわたる複数のボトルネックブロックの深さ優先実装を特徴としています。 |
演習問題
-
bottleneck設計では、何種類の融合計算が観察できますか?
答えを見る
2種類。ReLUと融合された畳み込みと、要素ごとの加算と融合された畳み込みです。なお、隣接する畳み込み層とバッチ正規化層の融合は、推論時の別の最適化であり、この実装でも処理できます。 -
bottleneck設計でデータフローアプローチに従う場合、3x3畳み込み演算が計算を進めるために1x1畳み込みコアからいくつの要素を必要としますか?
答えを見る
3要素。これにより、畳み込みカーネルが処理に必要な近傍情報が利用可能になります。 -
入力次元が32x32x256のボトルネックブロックがあるとします。1x1畳み込み層を通過した後、出力次元は32x32x64になります。その後の3x3畳み込み層(ストライド1、パディングなし、出力チャネル64)を通過した後の出力次元はどうなりますか?
答えを見る
30×30×64。パディングがないため、3x3畳み込み演算により各次元で2ピクセルずつ空間次元が縮小します。
IRONミニチュートリアル
主要コンポーネント:Workers、ObjectFifos、Runtime
IRONは、NPUプログラミングのための非配置(遅延配置)APIを提供します。以下は、AIE計算コードとObject FIFOデータ移動プリミティブを説明する例です:
Workerを使用した計算コード:
# テンソル型を定義
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
def core_fn():
buff = LocalBuffer(
data_ty,
name="buff",
initial_value=np.array(range(data_size), dtype=np.int32),
)
for i in range_(data_size):
buff[i] = buff[i] + 1
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, []) # 配置を強制できます: placement=Tile(1, 3)
Workerの詳細については、プログラミングガイドのセクション1およびworker.pyを参照してください。
Object FIFOデータ移動プリミティブ:
# テンソル型を定義
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(data_ty, name="in") # デフォルトの深さは2
Object FIFOの詳細については、プログラミングガイドのセクション2aおよびobjectfifo.pyを参照してください。
このミニチュートリアルのIRONコード例は、IRONデザインのさまざまな部分を詳述しています。特にRuntimeの詳細については、プログラミングガイドのセクション2dを参照してください。
演習
-
exercise_1に慣れてください。コードには、既にインスタンス化されたローカルバッファを持つ単一のWorkerが含まれており、それを外部メモリに送信します。
python3 exercise_1.pyを実行してプログラムを実行し、出力を確認してください。 -
exercise_1のコードを修正して、Workerがローカルバッファを使用する代わりに外部メモリから入力データを受け取るようにします。つまり、パススルーです。
-
exercise_1のコードを修正して、ObjectFifosのみを使用し、Workerを使用せずに、外部メモリからMemタイルを経由して戻るようにデータをルーティングします。このためには、プログラミングガイドのセクション2b - 暗黙的コピーで説明されている
forward()関数が必要です。セクション2dで説明されているように、ランタイムで入力Object FIFOにデータをfill()することを忘れないでください。 -
exercise_1のコードを修正して、最初に外部メモリからMemタイルを経由してWorkerにデータをルーティングし、Workerがパススルーを実行してから、データを送り返すようにします。
-
exercise_1のコードを修正して、WorkerのoutputがMemタイルを経由してルーティングされるようにします。
複雑なデータ移動パターン:Broadcast、Split、Join
IRONデザインは、複数のWorkerを使用するように簡単にスケーリングできます:
n_workers = 4
# テンソル型を定義
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
def core_fn(...):
# ...カーネルコード...
# タスクを実行するWorkerを作成
workers = []
for _ in range(n_workers):
workers.append(
Worker(core_fn, [...])
)
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, _):
rt.start(*workers)
複数のWorkerのプログラミングの詳細については、プログラミングガイドのセクション2eを参照してください。
broadcast、split、joinなどの複雑なデータ移動パターンは、ObjectFifo、特にプロデューサまたはコンシューマハンドルのいずれかであるObjectFifoHandleを使用してサポートされます。これらは、複数のコンシューマを持つブロードキャストパターンを決定するために使用されます。
Broadcast - ブロードキャストに関する詳細なドキュメントは、プログラミングガイドのセクション2b - Broadcastで利用できます。
n_workers = 4
# テンソル型を定義
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(data_ty, name="in")
def core_fn(of_in):
# ...カーネルコード...
# タスクを実行するWorkerを作成
workers = []
for _ in range(n_workers):
workers.append(
Worker(core_fn, [of_in.cons()]) # of_in.cons()を呼び出すたびに新しいObjectFifoHandleが返されます
)
split()およびjoin()メソッドは、それぞれ複数の出力および入力ObjectFifosを作成するために使用されます。
Split - split()に関する詳細なドキュメントは、プログラミングガイドのセクション2b - 暗黙的コピーで利用できます。
n_workers = 4
# テンソル型を定義
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
tile_size = data_size // n_workers
tile_ty = np.ndarray[(tile_size,), np.dtype[np.int32]]
# ObjectFifosを使用したデータフロー
of_offsets = [tile_size * worker for worker in range(n_workers)]
of_in = ObjectFifo(data_ty, name="in")
of_ins = of_in.cons().split(
of_offsets,
obj_types=[tile_ty] * n_workers,
names=[f"in{worker}" for worker in range(n_workers)],
)
def core_fn(of_in):
# ...カーネルコード...
# タスクを実行するWorkerを作成
workers = []
for worker in range(n_workers):
workers.append(
Worker(core_fn, [of_ins[worker].cons()])
)
Join - join()に関する詳細なドキュメントは、プログラミングガイドのセクション2b - 暗黙的コピーで利用できます。
n_workers = 4
# テンソル型を定義
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
tile_size = data_size // n_workers
tile_ty = np.ndarray[(tile_size,), np.dtype[np.int32]]
# ObjectFifosを使用したデータフロー
of_offsets = [tile_size * worker for worker in range(n_workers)]
of_out = ObjectFifo(data_ty, name="out")
of_outs = of_out.prod().join(
of_offsets,
obj_types=[tile_ty] * n_workers,
names=[f"out{worker}" for worker in range(n_workers)],
)
def core_fn(of_out):
# ...カーネルコード...
# タスクを実行するWorkerを作成
workers = []
for worker in range(n_workers):
workers.append(
Worker(core_fn, [of_outs[worker].prod()])
)
Object FIFOデータ移動パターンの詳細については、プログラミングガイドのセクション2bを参照してください。
演習
-
exercise_2に慣れてください。exercise_2のコードを修正して、入力データが3つのWorker間で分割され、それらの出力が結合されてから最終結果が外部メモリに送信されるようにします。
-
exercise_2のコードを修正して、各Workerのデータサイズが不均等になるようにします。たとえば:tile_sizes = [8, 24, 16]。
ランタイムシーケンス
IRONランタイムシーケンスの引数は、ホスト側で利用可能なバッファを記述します。シーケンスの本体には、ObjectFifosを通じてそれらのバッファがAIE配列にどのように移動されるかを記述するコマンドが含まれています。
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(data_ty, name="in")
of_out = ObjectFifo(data_ty, name="out")
rt = Runtime()
with rt.sequence(tile_ty, tile_ty) as (a_in, c_out):
rt.start(my_worker)
rt.fill(of_in.prod(), a_in)
rt.drain(of_out.cons(), c_out, wait=True)
ランタイムシーケンスでは最大5つのバッファがサポートされており、5番目は通常トレースサポートに使用されます。これについては、プログラミングガイドのセクション4bでさらに説明されています。
ランタイムシーケンスコマンドは、専用のコマンドプロセッサに順番に送信され、実行されます。コマンドプロセッサは、完了に関連付けられたトークンが生成されるまで、waitに設定されているコマンドを待機します。ランタイムシーケンス内のすべてのコマンドが実行されると、コマンドプロセッサはホストプロセッサに割り込みを送信します。
IRONは、task_groupを使用したランタイムシーケンスコマンドのグループ化もサポートしています。同じグループ内のコマンドは同時に実行を開始し、グループの完了はfinish_task_group()コマンドを使用して明示的に同期できます。これらの機能を組み合わせて、並列タスクの待機の最適化されたグループ化を実現できます。これはこのプログラミング例に示されています。
ランタイムシーケンスの詳細については、プログラミングガイドのセクション2dを参照してください。
演習
-
exercise_3に慣れてください。現在、デザインは単純なパススルー、つまり
out_C = in_Aを行っており、ランタイムシーケンス内のdrain()コマンドによって完了時にトークンが発行されます。fill()とdrain()コマンドの場所を入れ替えて、python3 exercise_3.pyを実行してください。何が起こるか観察してください。 -
exercise_3のコードを元のバージョンに復元してください。exercise_3のコードを修正して、外部メモリからの2つの入力テンソルの加算を行うようにします。つまり
out_C = in_A + in_B。
ランタイムパラメータとバリア
IRONは、ランタイム時に設定されWorkerに伝播されるランタイムパラメータをサポートしています。
n_workers = 4
# テンソル型を定義
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
# ランタイムパラメータ
rtps = []
for i in range(n_workers):
rtps.append(
GlobalBuffer(
np.ndarray[(16,), np.dtype[np.int32]],
name=f"rtp{i}",
use_write_rtp=True,
)
)
def core_fn(rtp):
runtime_parameter = rtp
# タスクを実行するWorkerを作成
workers = []
for worker in range(n_workers):
workers.append(
Worker(core_fn, [rtps[worker]])
)
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, _):
# ランタイムパラメータを設定
def set_rtps(*args):
for rtp in args:
rtp[0] = 50
rtp[1] = 255
rtp[2] = 0
rt.inline_ops(set_rtps, rtps)
RTPが早期に読み取られないようにするために、WorkerRuntimeBarriersを使用してWorkerをランタイムシーケンスと同期できます:
n_workers = 4
# テンソル型を定義
data_size = 256
data_ty = np.ndarray[(data_size,), np.dtype[np.int32]]
# ランタイムパラメータ
# ...
# Workerランタイムバリア
workerBarriers = []
for _ in range(n_workers):
workerBarriers.append(WorkerRuntimeBarrier())
def core_fn(rtp, barrier):
barrier.wait_for_value(1)
runtime_parameter = rtp
# タスクを実行するWorkerを作成
workers = []
for worker in range(n_workers):
workers.append(
Worker(core_fn, [rtps[worker], workerBarriers[worker]])
)
rt = Runtime()
with rt.sequence(data_ty, data_ty, data_ty) as (_, _, _):
# ランタイムパラメータを設定
# ...
rt.inline_ops(set_rtps, rtps)
for worker in range(n_workers):
rt.set_barrier(workerBarriers[worker], 1)
ランタイムパラメータとバリアの詳細については、プログラミングガイドのセクション2dおよびworker.pyを参照してください。
演習
-
exercise_4に慣れてください。83行目を修正して、
USE_INPUT_VEC = Falseに設定してください。python3 exercise_4.pyを実行してください。 -
Workerがランタイムが設定する前にRTPを読み取るため、デザインは失敗します。exercise_4のコードを修正して、WorkerがRTPが設定されるのを待つために
WorkerRuntimeBarrierを使用するようにします。
高度なトピック:データレイアウト変換
AIE配列のDMAは、オンザフライでデータ変換を実行できます。各次元の変換は、(size, stride)のペアとして表現されます。次元は最高から最低まで与えられます:
[(size_2, stride_2), (size_1, stride_1), (size_0, stride_0)]
データレイアウト変換は、ハードウェアにデータのどの場所に次にアクセスするかを指定する方法として見ることができ、そのため、一連のネストされたループを使用してアクセスパターンをモデル化することができます。たとえば、上記のstridesとsizesを使用した変換は、次のように表現できます:
int *buffer;
for(int i = 0; i < size_2; i++)
for(int j = 0; j < size_1; j++)
for(int k = 0; k < size_0; k++)
// buffer[ i * stride_2
// + j * stride_1
// + k * stride_0]の要素にアクセス/格納
ランタイム時のDMAオンザフライデータ変換をより適切にサポートするために、IRONはTensor Access Pattern(taps)の構成要素を提供するtaplibを提供します。sizesとstridesはグループ化され、次元は最高から最低まで与えられる必要があります(最大4次元):
tap = TensorAccessPattern(
tensor_dims=(2, 3),
offset=0,
sizes=[size_1, size_0],
strides=[stride_1, stride_0],
)
tapsにはさらにオフセットがあるため、tensor_dimsは元のテンソルのサイズより小さくなる場合があります。
TensorAccessPatternは、fill()およびdrain()ランタイム操作に適用できます:
rt = Runtime()
with rt.sequence(data_ty, data_ty) as (a_in, c_out):
rt.start(my_worker)
rt.fill(of_in.prod(), a_in, tap)
rt.drain(of_out.cons(), c_out, tap, wait=True)
TensorAccessPatternは、2つの方法で可視化できます:
- 要素がアクセスされる順序を示すヒートマップ
TensorAccessPatternによってテンソル内の各要素がアクセスされる回数を示すヒートマップ
tap.visualize(show_arrows=True, plot_access_count=True)
tapsはTensorAccessSequenceにグループ化でき、各tapは(タイリングパターンからの)異なるタイルを表します:
t0 = TensorAccessPattern((8, 8), offset=0, sizes=[1, 1, 4, 4], strides=[0, 0, 8, 1])
t1 = TensorAccessPattern((8, 8), offset=4, sizes=[1, 1, 4, 4], strides=[0, 0, 8, 1])
t2 = TensorAccessPattern((8, 8), offset=32, sizes=[1, 1, 4, 4], strides=[0, 0, 8, 1])
taps = TensorAccessSequence.from_taps([t0, t1, t2])
次に、tapsはシーケンス内で配列としてアクセスできます:
for t in taps:
tapのsizesとstridesを推測することは、ユーザーにとって困難な場合があります。taplibは、この課題に対処しようとするTensorTiler2Dクラスを導入します。Tilerは、一般的なタイリングパターンのtapsを生成するように設計された探索的機能です。Tilerは、生成されたtapsをTensorAccessSequenceとして返します:
tensor_dims = (8, 8)
tile_dims = (4, 4)
simple_tiler = TensorTiler2D.simple_tiler(tensor_dims, tile_dims)
上記のsimple tilerは、タイリングに対して非常に簡単なアプローチを取り、与えられた次元に基づいてデータの垂直分割を行います。より多くのtilerはtensortiler2d.pyで利用できます。
taplibの詳細については、tiling_explorationを参照してください。
ObjectFifoは、dims_to_streamおよびdims_from_stream_per_cons入力を介してDMAオンザフライデータ変換を表現できます。これらの入力は、ペアのリストとして構造化されており、各ペアはDMA変換の次元に対して(size, stride)として表現されます。次元は最高から最低まで与えられる必要があります:
dims = [(size_2, stride_2), (size_1, stride_1), (size_0, stride_0)]
of_out = ObjectFifo(data_ty, name="out", dims_to_stream=dims)
オフセットは現在Object FIFOレベルでは表現されていないため、次元はオブジェクトのフルサイズに適用可能である必要があります。
Object FIFOデータレイアウト変換の詳細については、プログラミングガイドのセクション2cを参照してください。
演習
-
exercise_5aに慣れてください。ランタイム時に入力データに対して実行されるデータ変換がref_plot.pngに示されているものと一致するように
tapを使用してください。ランタイムfill()操作にtapを追加することを忘れないでください。例を実行する前に、83行目をUSE_REF_VEC = Falseに修正してください。python3 exercise_5a.pyを実行して答えを確認してください。 -
exercise_5aで追加した
tapを、TensorTiler2Dによって生成されたものに置き換えてください。これには、tensortiler2d.pyで定義されているsimple_tiler()コンストラクタが必要です。python3 exercise_5a.pyを実行して答えを確認してください。2つの生成されたプロットも観察できます。 -
exercise_5aのコードを修正して、ランタイム時ではなく、
of_outに直接データ変換が適用されるようにします。python3 exercise_5a.pyを実行して答えを確認してください。 -
exercise_5bに慣れてください。
TensorAccessSequence内のtapsがexercise_5aのものとわずかに異なることを観察してください。python3 exercise_5b.pyを実行し、2つの生成されたプロットを観察してください。
{kind=link}
注意: より詳細な情報については、公式ドキュメントを参照してください。
IRONクイックリファレンス
- Pythonバインディング
- Pythonヘルパー関数
- カーネルプログラミングのための一般的なAIE API関数
- 役立つAI Engineアーキテクチャリファレンスとテーブル
- AI Engineドキュメント
- AIE詳細リファレンス
Pythonバインディング
| 関数シグネチャ | 定義 | パラメータ | 戻り値の型 | 例 |
|---|---|---|---|---|
tile(column, row) | AI Engineタイルを宣言 | column: 列インデックス番号 row: 行インデックス番号 | <tile> | ComputeTile = tile(1,3) |
external_func(name, inputs, output) | AIEコア上で実行される外部カーネル関数を宣言 | name: 外部関数名 input: 入力型のリスト output: 出力型のリスト | <external_func> | scale_scalar = external_func("vector_scalar_mul_aie_scalar", inputs=[tensor_ty, tensor_ty, np.ndarray[(1,), np.dtype[np.int32]]]) |
npu_dma_memcpy_nd(metadata, bd_id, mem, sizes) | 外部メモリにアクセスするn次元DMAを設定 | metadata: ObjectFifo pythonオブジェクトまたはobject_fifoの名前文字列bd_id: 識別番号mem: 転送用メモリsizes: 4Bの粒度での4次元転送サイズ | None | npu_dma_memcpy_nd(metadata="out", bd_id=0, mem=C, sizes=[1, 1, 1, N]) |
dma_wait(object_fifo, ...) | 外部メモリにアクセスするためのホスト-ShimDMA同期を設定 | metadata: 完了を待機しているObjectFifo(Pythonオブジェクトまたは名前文字列)を識別します。これは可変引数関数であり、1つ以上のメタデータを一度に受け取り、与えられた順序で待機します | None | dma_wait(of_out) |
npu_sync(column, row, direction, channel, column_num=1, row_num=1) | 外部メモリにアクセスするためのホスト-ShimDMA同期を設定する代替方法 | columnとrow: 同期を開始するタイル位置を指定 direction: DMAの方向を示します(0はホストへの書き込み、1はホストからの読み取り) channel: 同期トークンのDMAチャネル(0または1)を識別 column_numとrow_num(オプション): 同期を待機するタイルの範囲を定義 | None | npu_sync(column=0, row=0, direction=0, channel=1) |
| Object FIFO | ||||
object_fifo(name, producerTile, consumerTiles, depth, datatype) | Object FIFOを構築 | name: Object FIFO名 producerTile: プロデューサタイルオブジェクト ConsumerTiles: コンシューマタイルオブジェクトのリスト depth: Object FIFO内のオブジェクト数 datatype: Object FIFO内のオブジェクトの型 | <object_fifo> | of0 = object_fifo("objfifo0", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]]) |
<object_fifo>.acquire(port, num_elem) | Object FIFOからacquire | port: ObjectFifoPort.ProduceまたはObjectFifoPort.Consume num_elem: acquireするオブジェクト数 | <objects> | elem0 = of0.acquire(ObjectFifoPort.Produce, 1) |
object_fifo.release(port, num_elem) | Object FIFOからrelease | port: ObjectFifoPort.ProduceまたはObjectFifoPort.Consume num_elem: | None | of0.release(ObjectFifoPort.Consume, 2) |
object_fifo_link(fifoIns, fifoOuts) | Object FIFO間のリンクを作成 | fifoIns: Object FIFOのリスト(変数または名前)fifoOuts: Object FIFOのリスト(変数または名前) | None | object_fifo_link(of0, of1) |
| ルーティングバインディング(トレースと低レベル設計に関連) | ||||
flow(source, source_bundle, source_channel, dest, dest_bundle, dest_channel) | 送信元と宛先の間に回路交換フローを作成 | source: フローの送信元タイル source_bundle: 送信元WireBundleの型(完全なリストはAIEAttrs.tdを参照) source_channel: 送信元チャネルインデックス dest: フローの宛先タイル dest_bundle: 宛先WireBundleの型(完全なリストはAIEAttrs.tdを参照) dest_channel: 宛先チャネルインデックス | None | flow(ComputeTile, WireBundle.DMA, 0, ShimTile, WireBundle.DMA, 1) |
packetflow(pkt_id, source, source_port, source_channel, dest, dest_port, dest_channel, keep_pkt_header) | 送信元と宛先の間にパケット交換フローを作成 | pkt_id: 一意のパケットID source: パケットフローの送信元タイル source_port: 送信元WireBundleの型(完全なリストはAIEAttrs.tdを参照) source_channel: 送信元チャネルインデックス dest: パケットフローの宛先タイル dest_port: 宛先WireBundleの型(完全なリストはAIEAttrs.tdを参照) dest_channel: 宛先チャネルインデックス keep_pkt_header: ヘッダーを保持するブールフラグ | None | packetflow(1, ComputeTile2, WireBundle.Trace, 0, ShimTile, WireBundle.DMA, 1, keep_pkt_header=True) |
注意:
tile: デバイス上で実際に実行されるタイル座標は、ここで宣言されたものと異なる場合があります。例えば、Ryzen AIでは、これらの座標は相対座標である傾向があり、ランタイムスケジューラが利用可能な別の列に割り当てる可能性があります。
注意:
object_fifo:producerTileとconsumerTilesの入力はAI Engineタイルです。consumerTilesは、複数のコンシューマの場合、タイルの配列として指定することもできます。
注意:
<object_fifo>.{acquire,release}: 出力は単一のオブジェクトまたはオブジェクトの配列のいずれかであり、配列のようにインデックスを付けることができます。
注意:
object_fifo_linkリンクで共有タイルとして使用されるタイルは、現在Memタイルである必要があります。入力fifoInsとfifoOutsは、単一のObject FIFOまたはそれらのリストのいずれかです。両方とも、python変数または名前のいずれかを使用して指定できます。現在、2つの入力のいずれかがObjectFIFOのリストである場合、もう一方は単一のObject FIFOのみになります。
Pythonヘルパー関数
| 関数シグネチャ | 説明 |
|---|---|
print(ctx.module) | ctxでラップされた構造コードをmlirに変換し、標準出力に出力します |
ctx.module.operation.verify() | Pythonバインディングされたソースコードに対して追加の構造検証を実行し、結果を標準出力に返します |
カーネルプログラミングのための一般的なAIE API関数
| 関数シグネチャ | 定義 | パラメータ | 戻り値の型 | 例 |
|---|---|---|---|---|
aie::vector<T, vec_factor> my_vector | ベクトル型を宣言 | T: データ型 vec_factor: ベクトル幅 | n/a | aie::vector<int16_t, 32> my_vector; |
aie::load_v<vec_factor>(pA1); | ベクトルロード | vec_factor: ベクトル幅 | aie::vector | aie::vector<int16_t, 32> my_vector; |
役立つAI Engineアーキテクチャリファレンスとテーブル
-
役立つタイルコアトレースイベント
一般的なイベント イベントID 10進数値 True 0x01 1 ストリームストール 0x18 24 コア命令 - イベント0 0x21 33 コア命令 - イベント1 0x22 34 ベクトル命令(例:VMAC、VADD、VCMP) 0x25 37 ロックacquireリクエスト 0x2C 44 ロックreleaseリクエスト 0x2D 45 ロックストール 0x1A 26 コアポート実行中 1 0x4F 79 コアポート実行中 0 0x4B 75 - コアタイル、コアメモリ、メムタイル、shimタイルのイベントのより包括的なリストは、このヘッダーファイルにあります
AI Engineドキュメント
- UG1076のドキュメントリンク概要
- AIE1アーキテクチャマニュアル - AM009
- AIE1レジスタリファレンス - AM015
- AIE2アーキテクチャマニュアル - AM020
- AIE2レジスタリファレンス - AM025
- AIE APIユーザーガイド - v2023.2
- AIE1イントリンシクスユーザーガイド - v2023.2
- AIE2イントリンシクスユーザーガイド - v2023.2