Section 2a - はじめに
Object FIFOの初期化
Object FIFOは、ソースと1つまたは複数の宛先間のデータ移動接続を表します。Object FIFOのエンドポイントは、プログラムの残りの部分での使用方法に基づいて推論されます。IRONでは、ObjectFifoクラスコンストラクタ(objectfifo.pyで定義)を使用してObject FIFOを初期化できます:
class ObjectFifo(Resolvable):
def __init__(
self,
obj_type: type[np.ndarray],
depth: int | None = 2,
name: str | None = None,
dims_to_stream: list[Sequence[int]] | None = None,
dims_from_stream_per_cons: list[Sequence[int]] | None = None,
plio: bool = False,
)
Object FIFOは、depth個のオブジェクトのカウントを持つ順序付けバッファとして機能します。デフォルトでは2に設定されており、これはダブルまたはピンポンバッファリングを表します。Object FIFO内のすべてのオブジェクトは、同じobj_typeデータ型である必要があります。データ型はテンソルのような属性で、テンソルのサイズと個々の要素の型が同時に指定されます(例:np.ndarray[(16,), np.dtype[np.int32]])。name入力は一意である必要があり、ユーザーが指定するか、コンパイラが完成させるために空のままにすることができます。これは、コンパイラフローの後続の変換ステップに必要です。
AIE配列を横断する際、Direct Memory Access(DMA)チャネルの機能を使用してデータを再構成できます。これらのコンポーネントについてはこちらで詳しく説明していますが、簡単な紹介として、DMAは配列の各タイルに存在し、AXIストリーム相互接続に到着するデータをタイルのローカルメモリに書き込む責任があります(逆も同様)。DMAには、Object FIFOのプロデューサ(dims_to_stream入力を使用)または各コンシューマ(dims_from_stream_per_cons入力を使用)によってAXIストリームに送信されるデータの順序を表現するアクセスパターンを与えることができます。これらの入力には専用のセクションがあります(section-2cのデータレイアウト変換を参照)。plio入力は、Object FIFOのエンドポイントの1つがシムタイルである場合に使用でき、通信が専用のplioポートを介して配線されることをコンパイラに示します。
以下は、データ型<256xi32>で深さ3のinという名前のObject FIFOを初期化する例です:
# テンソル型を定義
line_size = 256
line_type = np.ndarray[(line_size,), np.dtype[np.int32]]
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(line_type, name="in", depth=3)
Object FIFOのエンドポイントはプロデューサとコンシューマに分けられ、Object FIFOは1つのプロデューサと1つまたは複数のコンシューマのみを持つことができます。これらのエンドポイントは、データフロー理論の用語に基づいて、Object FIFOの「アクター」とも呼ばれます。この抽象化レベルでは、エンドポイントは通常、ObjectFifoHandleにアクセスできるWorkerです。もう1つの使用例は、実行時にObject FIFOが外部メモリから満たされる、または外部メモリに排出される場合です(ランタイムデータ移動セクションで説明)。
以下のコードスニペットは、core_fnとcore_fn2で定義されたプロセスを実行する2つのWorkerを示しており、それぞれof_inのプロデューサハンドルまたはコンシューマハンドルを入力として受け取ります:
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(line_type, name="in", depth=3)
# 外部バイナリカーネル定義
test_fn = Kernel(
"test_func",
"test_func.cc.o",
[line_type, np.int32],
)
test_fn2 = Kernel(
"test_func2",
"test_func2.cc.o",
[line_type, np.int32],
)
# コアが実行するタスク
def core_fn(of_in, test_func):
# ...
def core_fn2(of_in, test_func2):
# ...
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of_in.prod(), test_fn])
my_worker = Worker(core_fn2, [of_in.cons(), test_fn2])
Object FIFOは1つのプロデューサプロセスのみを持つことができるため、prod()への各呼び出しは同じObjectFifoHandleへの参照を返しますが、cons()の各呼び出しは、そのコンシューマプロセス用の新しいObjectFifoHandleへの参照を返します。
このセクションの冒頭で、コンパイラは使用方法に基づいてObject FIFOのエンドポイントを推論できると述べました。これは具体的には、Object FIFOのプロデューサとコンシューマを収集するために使用できるObjectFifoHandleの使用を指します。したがって、次のセクションの主題である異なるデータ移動パターンを観察できます。
コンパイラフローの次のステップでは、Object FIFOプロデューサとコンシューマのWorkerプロセスは、Placerを使用して明示的なAIEタイルにマッピングされます(Section 1 - AI Engineの基本構成要素を参照)。内部的には、異なるタイプのタイル(シムタイル、メモリタイル、コンピュートタイル)のデータ移動設定は異なりますが、Object FIFOを使用する場合、それらの間に違いはありません。
より低レベルのIRON APIを使用してObject FIFOを初期化するには、object_fifoクラスコンストラクタ(aie.pyで定義)を使用できます:
class object_fifo:
def __init__(
self,
name,
producerTile,
consumerTiles,
depth,
datatype: MemRefType | type[np.ndarray],
dimensionsToStream=None,
dimensionsFromStreamPerConsumer=None,
initValues=None,
via_DMA=None,
plio=None,
disable_synchronization=None,
)
一部の入力は高レベルと同じですが、他の入力はわずかに異なります。各入力が何を表し、なぜ抽象化に必要なのかを説明します。まず必須の入力に焦点を当て、後でデフォルト値を持つ入力について説明します。dimensionsToStreamとdimensionsFromStreamPerConsumer入力には専用のセクションがあります(section-2cのデータレイアウト変換を参照)。
最高レベルの抽象化と同様に、Object FIFOは、指定されたdatatypeのdepth個のオブジェクトのカウントを持つ順序付けバッファとして機能します。現在、Object FIFO内のすべてのオブジェクトは同じデータ型である必要があります。datatypeはテンソルのような属性で、テンソルのサイズと個々の要素の型が同時に指定されます(例:<16xi32>)。以前とは異なり、depthは整数または整数の配列として定義できます。後者については、このセクションで後述します。
Object FIFOは、プロデューサまたはソースタイルと、コンシューマまたは宛先タイル間で作成されます。タイルは、Object FIFOにアクセスするプロデューサおよびコンシューマプロセスが実行される場所です。これらのプロセスは、データフロー理論の用語に基づいて、Object FIFOの「アクター」とも呼ばれます。以下は、プロデューサタイルAとコンシューマタイルB間に深さ3でof_inが作成される例です:
A = tile(1, 3)
B = tile(2, 4)
of_in = object_fifo("in", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]])
以下の図は、タイルとObject FIFOリソースがどこに配置されるかについて仮定を立てないof_inの論理ビューを表しています:

「主要なObject FIFOパターン」セクションで説明するように、Object FIFOは複数のコンシューマタイルを持つことができ、これはソースタイルからすべてのコンシューマタイルへのブロードキャスト接続を記述します。そのため、consumerTiles入力は単一のタイルまたはタイルの配列のいずれかになります。これはproducerTile入力には当てはまりません。現在、Object FIFOは複数のプロデューサをサポートしていません。
Object FIFOのオブジェクトへのアクセス
Object FIFOは、それに登録されたプロデューサおよびコンシューマプロセスによってアクセスできます。プロセスがオブジェクトにアクセスする前に、Object FIFOからそれらを取得する必要があります。これは、Object FIFOが、2つのプロセスが同時に同じオブジェクトにアクセスできないことを保証するために、ターゲットハードウェアアーキテクチャで利用可能な同期メカニズムを活用する同期通信プリミティブであるためです。プロセスがオブジェクトの使用を終え、それ以上必要がなくなったら、別のプロセスがそれを取得してアクセスできるように解放する必要があります。プロデューサまたはコンシューマプロセスがObject FIFOからオブジェクトを取得および解放するパターンは、「アクセスパターン」と呼ばれます。取得パターンと解放パターンを具体的に参照することもできます。
_acquire()関数は、Object FIFOから1つまたは複数のオブジェクトを取得するために使用されます:
def _acquire(
self,
port: ObjectFifoPort,
num_elem: int,
)
取得された要素の数を表すnum_elem入力に基づいて、関数はオブジェクトを直接返すか、オブジェクトの配列を返します。port入力については、このセクションで後述します。
Object FIFOは順序付けられたプリミティブであり、APIは各プロセスについて、取得および解放した数に基づいて、取得時に次にアクセスできるオブジェクトを追跡します。具体的には、プロセスが初めてオブジェクトを取得すると、Object FIFOの最初のオブジェクトにアクセスでき、それを解放して新しいものを取得すると、2番目のオブジェクトにアクセスでき、最後のオブジェクトまで続き、その後、順序は最初のものから再び始まります。複数のオブジェクトを取得し、返された配列でそれらにアクセスする場合、インデックス0のオブジェクトは常に、そのプロセスがアクセスできる最も古いオブジェクトになります。これは、そのObject FIFOのプール内の最初のオブジェクトではない可能性があります。
_release()関数は、1つまたは複数のオブジェクトを解放するために使用されます:
def _release(
self,
port: ObjectFifoPort,
num_elem: int,
)
プロセスは、取得したオブジェクトの1つ、一部、またはすべてを解放できます。解放関数は、取得された順序で最も古いものから最も新しいものへオブジェクトを解放します。プロセスが取得したすべてのオブジェクトを解放しない場合、次にオブジェクトを取得するときに、最も古いオブジェクトは解放されなかったものになります。この機能は、Object FIFOプリミティブを通じてスライディングウィンドウの動作を実現することを目的としています。これについては、「主要なObject FIFOパターン」セクションで詳しく説明します。
Object FIFOのオブジェクトを取得する際に注意すべき重要な点は、以前の取得から解放されていないオブジェクトも最新の取得呼び出しによって返されることです。解放されていないオブジェクトは、プロセスが以前の取得から解放されていないオブジェクトへの単独アクセス権をすでに持つように、内部で使用される同期メカニズムがすでに設定されているという意味で再取得されません。そのため、間に解放呼び出しがない場合、連続して2回の取得呼び出しを行うと、両方の取得呼び出しで同じオブジェクトが返されます。この決定は、取得関数呼び出し間のオブジェクト解放の理解を容易にし、Object FIFOプリミティブを通じた適切な変換を確保するために行われました。この動作のコード例は、「主要なObject FIFOパターン」セクションで入手できます。
取得関数と解放関数の両方のport入力は、そのプロセスがObject FIFO抽象化の低レベルでプロデューサプロセスかコンシューマプロセスかを表し、基盤となる同期メカニズムを適切に活用するためのObject FIFO変換の重要な指標です。その値はObjectFifoPort.ProduceまたはObjectFifoPort.Consumeのいずれかです。ただし、注意すべき重要な点は、プロデューサとコンシューマという用語は、主に人間のユーザーがどのプロセスがデータ移動のどの端にあるかを追跡するための論理的な参照を提供する手段として使用されますが、そのプロセスの動作を制限するものではないということです。つまり、プロデューサプロセスは単にオブジェクトを読み取るためにアクセスすることができ、それを変更する必要はありません。
以下は、前のセクションで初期化したof_inというObject FIFOのオブジェクトを反復処理する2つのプロセスの例です。1つはプロデューサハンドルにアクセスし、もう1つはコンシューマハンドルにアクセスします。これを行うために、プロデューサプロセスはof_inの深さに等しい3回の反復のループを実行し、各反復中にof_inから1つのオブジェクトを取得し、取得したオブジェクトに対してtest_func関数を呼び出し、オブジェクトを解放します。コンシューマプロセスは1回だけ実行され、of_inから3つのオブジェクトすべてを一度に取得し、elems配列に格納します。そこから、任意の順序で各オブジェクトに個別にアクセスできます。その後、test_func2関数を3回呼び出し、各呼び出しで取得したオブジェクトの1つを入力として与え、最後に3つのオブジェクトすべてを解放します。
# ObjectFifosを使用したデータフロー
of_in = ObjectFifo(line_type, name="in", depth=3)
# 外部バイナリカーネル定義
# ...
# コアが実行するタスク
def core_fn(of_in, test_func):
for _ in range_(3):
elemIn = of_in.acquire(1)
test_func(elemIn, line_size)
of_in.release(1)
def core_fn2(of_in, test_func2):
elems = of_in.acquire(3)
test_func2(elems[0], line_size)
test_func2(elems[1], line_size)
test_func2(elems[2], line_size)
of_in.release(3)
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of_in.prod(), test_fn])
my_worker = Worker(core_fn2, [of_in.cons(), test_fn2])
object_fifoクラスのacquire()およびrelease()関数の低レベルAPIバリアントを以下に示します:
def acquire(self, port, num_elem)
def release(self, port, num_elem)
以下のコードスニペットは、上記と同じ例が明示的に配置されたエンドポイントを持つより低い抽象化レベルでどのように記述されるかを示しています。
A = tile(1, 3)
B = tile(2, 4)
of_in = object_fifo("in", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]])
@core(A)
def core_body():
for _ in range_(3):
elem0 = of_in.acquire(ObjectFifoPort.Produce, 1)
test_func(elem0)
of_in.release(ObjectFifoPort.Produce, 1)
@core(B)
def core_body():
elems = of_in.acquire(ObjectFifoPort.Consume, 3)
test_func2(elems[0])
test_func2(elems[1])
test_func2(elems[2])
of_in.release(ObjectFifoPort.Consume, 3)
以下の図は、このコードを示しています:4つの図のそれぞれは、実行の1回の反復中のシステムの状態を表しています。最初の3回の反復では、青で描かれたタイルA上のプロデューサプロセスが、of0の要素を1つずつ段階的に取得および解放します。4回目の反復で3番目の要素が解放されると、緑で描かれたタイルB上のコンシューマプロセスが3つのオブジェクトすべてを一度に取得できます。
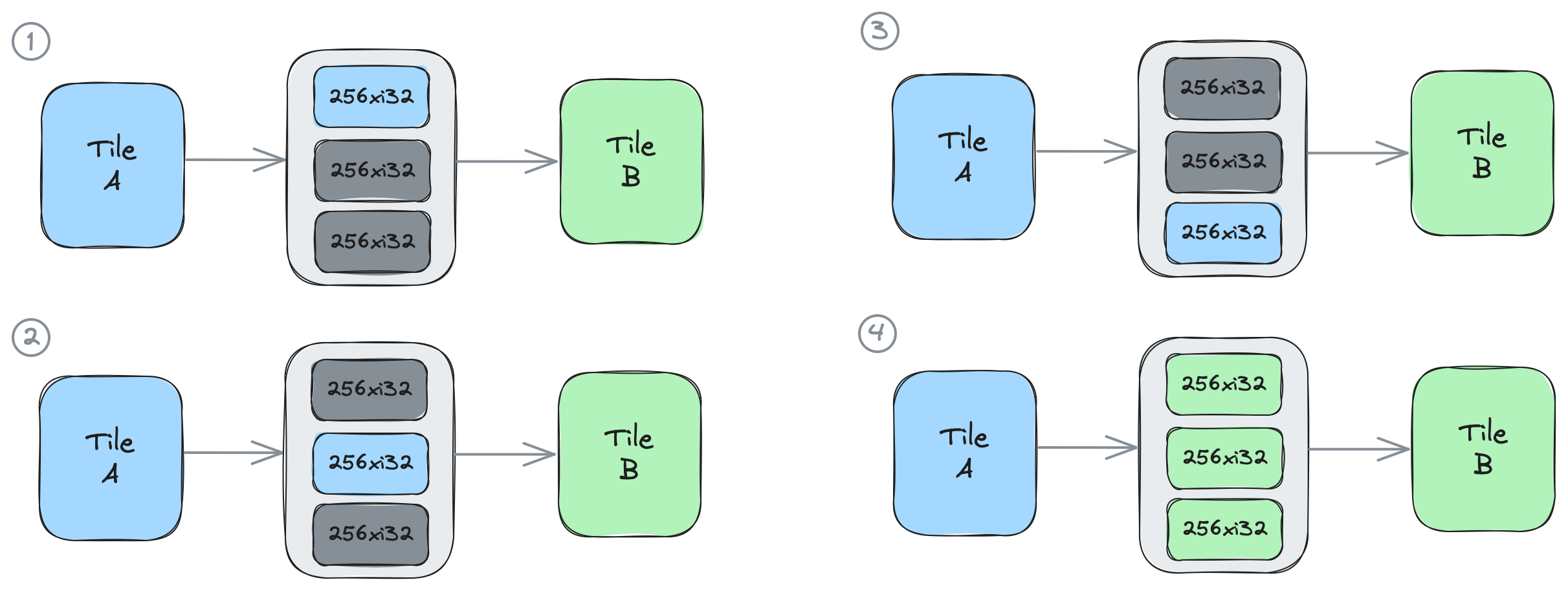
これらの機能を使用する設計の例は、Section 2fの01_single_double_bufferおよび02_external_mem_to_coreで入手できます。
同じプロデューサ/コンシューマを持つObject FIFO
Object FIFOは、同じタイルをプロデューサタイルとコンシューマタイルの両方として作成できます。これは主に、これまでの例で見てきたような異なるタイル上で実行される複数のプロセス間の同期とは対照的に、プロセス自体内で適切な同期を確保するために行われます。共有バッファへのアクセスを持つ2つのカーネルを構成することは、Object FIFOのこのプロパティを活用するアプリケーションです。以下のコードスニペットで示されているように、test_funcとtest_func2はof0を使用して構成されています:
# ObjectFifosを使用したデータフロー
of0 = ObjectFifo(line_type, name="objfifo0", depth=3)
# 外部バイナリカーネル定義
# ...
# コアが実行するタスク
def core_fn(of_in, of_out, test_func, test_func2):
for _ in range_(3):
elemIn = of_in.acquire(1)
test_func(elemIn, line_size)
of_in.release(1)
elemOut = of_out.acquire(1)
test_func2(elemIn, line_size)
of_out.release(1)
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of0.prod(), of0.cons(), test_fn, test_fn2])
以下のコードスニペットは、上記と同じ例が明示的に配置されたエンドポイントを持つより低い抽象化レベルでどのように記述されるかを示しています:
A = tile(1, 3)
of0 = object_fifo("objfifo0", A, A, 3, np.ndarray[(256,), np.dtype[np.int32]])
@core(A)
def core_body():
for _ in range_(3):
elem0 = of0.acquire(ObjectFifoPort.Produce, 1)
test_func(elem0)
of0.release(ObjectFifoPort.Produce, 1)
elem1 = of0.acquire(ObjectFifoPort.Consume, 1)
test_func2(elem1)
of0.release(ObjectFifoPort.Consume, 1)
Object FIFO深さを配列として指定
AIEアーキテクチャは、明示的なデータ移動を必要とする空間アーキテクチャです。そのため、Object FIFOの概念的な設計は2つ以上のAIEタイル間の順序付けバッファですが、実際には、その概念的な深さは、メモリ階層の異なるレベルに配置され、異なるタイル上にある可能性のある複数のリソースプールに分散されています。
Object FIFOの深さのより詳細でありながら抽象的なビューは、プロデューサと各コンシューマが、Object FIFOによって記述されるデータ移動に関してデータを送受信するために使用できる独自の作業リソースプールをローカルメモリモジュールで利用できるというものです。Object FIFOプリミティブとその変換は通常、これらのプールの深さを、結果の動作が概念的な深さと一致するように割り当てます。
ただし、ユーザーはこれらのプールの深さを手動で選択する可能性があります。この機能が利用可能なのは、Object FIFOプリミティブがAIE配列全体でのデータ移動の統一表現を提供しようとする一方で、パフォーマンスプログラマーがそれをより細かく制御するためのツールを提供することも目的としているためです。この機能は、Object FIFO抽象化の明示的に配置されたレベルで利用できます。
たとえば、以下のコードスニペットでは、of0はプロデューサAとコンシューマB間のデータ移動を記述しています:
A = tile(1, 3)
B = tile(2, 4)
of0 = object_fifo("objfifo0", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]])
Object FIFOの概念的な深さは3です。この深さの選択の背後にある理由は、2つのアクターの取得および解放パターンを見ることで理解できます:
@core(A)
def core_body():
for _ in range_(9):
elem0 = of0.acquire(ObjectFifoPort.Produce, 1)
produce_func(elem0)
of0.release(ObjectFifoPort.Produce, 1)
@core(B)
def core_body():
for _ in range_(9):
elems = of0.acquire(ObjectFifoPort.Consume, 2)
consume_func(elems[0], elems[1])
of0.release(ObjectFifoPort.Consume, 2)
各反復:
- プロデューサAは、プロデュースする1つのオブジェクトを取得し、カーネル関数
produce_funcを呼び出してBが消費する新しいデータを格納し、オブジェクトを解放します。 - コンシューマBは、消費する2つのオブジェクトを取得し、データを読み取ってカーネル関数
consume_funcを適用し、両方のオブジェクトを解放します。
このシステムがデッドロックせずに機能するには、概念的な深さ2で十分でした。ただし、深さが3の場合、AとBは同時に実行できます。つまり、Bが2つのオブジェクトを消費してカーネル関数を適用している間、Aは同時にプロデュースできる1つのオブジェクトが利用可能です。
深さの配列を使用したこの概念的な深さ3の同等物は次のとおりです:
of0 = object_fifo("objfifo0", A, B, [2, 3], np.ndarray[(256,), np.dtype[np.int32]])
ここで、2はプロデューサAにローカルで利用可能なリソースの数であり、3はコンシューマBで利用可能な数です。
注意: 正しい変換のために、この機能は、Object FIFOのプロデューサとコンシューマが異なるタイル上で実行されている状況で使用する必要があります。
異なるObject FIFOのアクター用のリソースプールの深さを指定する機能は、複数のObject FIFOを使用する場合に発生する可能性のある特定の依存関係をサポートするために使用され、「主要なObject FIFOパターン」セクションでさらに説明されています。
Object FIFOの追加入力
これまで、このセクションではObject FIFOの必須入力を紹介してきました。ガイドのこの部分では、残りの入力に焦点を当て、Object FIFO変換をガイドする上でどのような役割を果たすかを説明します。
class object_fifo:
def __init__(
...
initValues=None,
via_DMA=None,
plio=None,
disable_synchronization=None,
)
念のため、dimensionsToStreamおよびdimensionsFromStreamPerConsumer入力には専用のセクションがあります(section-2cのデータレイアウト変換を参照)。
Object FIFOのインスタンス化時に、initValues入力に初期値の配列を提供することで、そのオブジェクトを初期化することができます。これは、以下のコードスニペットで示されており、of0の2つのオブジェクトがそれぞれ配列[0, 1, 2, 3]と[4, 5, 6, 7]で初期化されています:
A = tile(1, 3)
B = tile(2, 4)
of0 = object_fifo(
"of0",
A,
B,
2,
np.ndarray[(2, 2), np.dtype[np.int32]],
initValues=[
np.arange(4, dtype=np.int32),
np.arange(4, 8, dtype=np.int32)
],
)
初期値はObject FIFOのdatatypeと一致する必要があることに注意することが重要です。このプロセスを支援するために、Object FIFO APIは指定された初期値の形状を変更しようとします。上記の例では、初期値は<2x2xi32>データ型と一致するように[[0, 1], [2, 3]]および[[4, 5], [6, 7]]として形状が変更されます。
Object FIFOが作成時に初期化されると、基盤となる同期メカニズムは、コンシューマが読み取る時間を持つ前に初期値が新しいデータで上書きされないように、Object FIFOのプロデューサがすぐに新しいオブジェクトを取得できないように設定されます。
Object FIFOの残りの入力は高度なトピックと見なされ、このガイドの残りの部分を理解するために必要ありません。
Object FIFOのvia_DMA入力は、主にデバッグまたはベンチマークの目的で使用されます。変換されたデータ移動設定がタイルのDirect Memory Access(DMA)チャネルを使用することを強制するために、trueに設定できます。DMAについては、以下の高度なトピックセクションでさらに説明します。Object FIFO変換とvia_DMA属性がそれにどのように影響するかについての詳細は、ローカルメモリまたはDMAを使用した通信に関するMLIR-AIEチュートリアルのセクションを参照してください。
plio入力は、Object FIFO変換にデータ移動設定に関する情報を提供するために使用されます。Object FIFOが変換されると、そのタイル間で確立される通信フローは専用のplioポートを介して配線されます。
Object FIFOは、オブジェクトに専用の同期リソースを結合して、一度に1つのアクターのみがそれらにアクセスできるようにし、データの破損を防ぐ同期データ移動プリミティブです。これらの同期リソースは実行時に追加のサイクルを消費するため、必要ない場合は削除することが望ましい場合があります。そのような状況の1つの例は、同じプロデューサ/コンシューマを持つObject FIFOを使用する場合です。コア内のアクセスは順次実行されるためです。Object FIFOのdisable_synchronization入力はまさにその目的を果たし、trueに設定されると、オブジェクトに結合された同期リソースはありません。
Object FIFOコンパイラフラグ
Object FIFO変換パスは、aiecc.pyコンパイラパイプラインを通じて利用可能な2つのコンパイラフラグを提供します。これらのフラグにより、ユーザーは、オブジェクトアクセス用に生成されるWorkerコードの複雑さと、Object FIFOで表されるデータ移動にどのハードウェア機能が活用されるかに影響を与える変換の決定の一部を駆動できます。
これらのフラグは次のとおりです:
dynamic-objFifos: 有効にすると、コンパイラはMLIRscf.index_switch操作を生成して、Workerの実行中に取得されたオブジェクトと解放されたオブジェクトの数を追跡します。この機能は、Workerの実行の反復間でこれらの数が異なる場合に特に役立ちます。これにより、アクセスされたオブジェクトの数の動的な実行時解決が可能になります。packet-sw-objFifos: 有効にすると、コンパイラは(デフォルトの回路交換フローの代わりに)パケット交換フローを使用してAXIストリームデータ移動を設定します。この機能は開発の初期段階にあり、現在、Worker間およびWorkerと外部メモリ間のObject FIFOのみをサポートしています。
これらのフラグは、次のようにaiecc.pyへの呼び出し、またはObject FIFO変換パスへの直接呼び出しと組み合わせることができます:
aiecc.py --packet-sw-objFifos <MLIRデザインファイルへのパス>
aie-opt --aie-objectFifo-stateful-transform="packet-sw-objFifos" <MLIRデザインファイルへのパス>
高度なトピック:オブジェクトの指向的割り当て
Object FIFO変換は、AIE配列のメモリ内でメモリ要素を割り当てる場所について決定を下します。場合によっては、これらの割り当てに使用する特定のAIEタイルをターゲットにすることが望ましい場合があります。これらのケースでは、allocate()関数を次のように使用できます:
A = tile(1, 2)
B = tile(1, 3)
of_in = object_fifo("in", A, B, 3, np.ndarray[(256,), np.dtype[np.int32]])
of_in.allocate(B)
注意: 現在、Object FIFOのプロデューサとコンシューマの両方が、ターゲットAIEタイルへの直接共有メモリアクセスを持つ必要があります。
高度なトピック:Direct Memory Accessチャネル
以下のトピックは、このガイドの残りの部分を理解するために必要ありません。
ガイドのこの部分では、AIEハードウェアのいくつかの低レベル概念を紹介し、各タイル上の個々のリソースプールとその深さの背後にある理由を詳しく見ていきます。
AIE配列の各タイルには、専用のDirect Memory Access(DMA)があります。DMAは、タイルのメモリモジュールからAXIストリーム相互接続へ、またはストリームからメモリモジュールへデータを移動する責任があります。コンピュートタイルの場合、コンピュートコアとタイルのDMAの両方がタイルのメモリモジュールにアクセスできます。このため、データの破損を避けるために、コンピュートコアとDMAが相互にデータが読み取りまたは書き込み可能であることを信号できるようにする同期メカニズムが必要です。これは、プロデューサとコンシューマがオブジェクトにアクセスする前にまずオブジェクトを取得し、他の当事者が取得できるように完了したら解放する必要があるObject FIFOの概念と非常に似ています。
以下の図は、コンピュートタイルの高レベルビューを示しており、コンピュートコアとDMAの両方がローカルメモリモジュール内の場所buffにデータを読み書きしています:
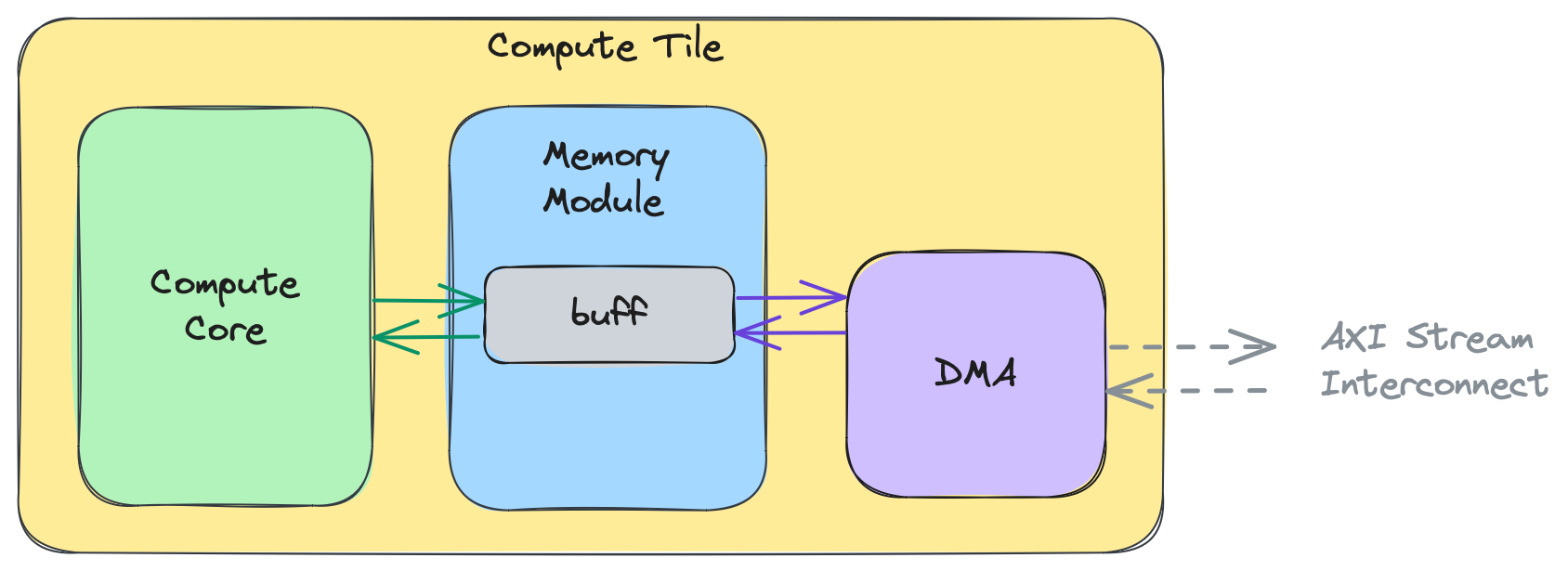
この高レベルビューの意図は、コアが同時にメモリバッファにアクセスしている間、DMAがメモリバッファと対話できることを示すことです。DMAはバッファからAXIストリームにデータを送信し、ストリームからデータを受信してコアが処理しているバッファに書き込むことができます。この並行性はデータ競合につながる可能性があるため、単一のバッファの代わりにピンポンバッファ(ダブルバッファとも呼ばれます)がよく使用されます。これは以下の図で示されており、buffがbuff_pingとbuff_pongに拡張されています:
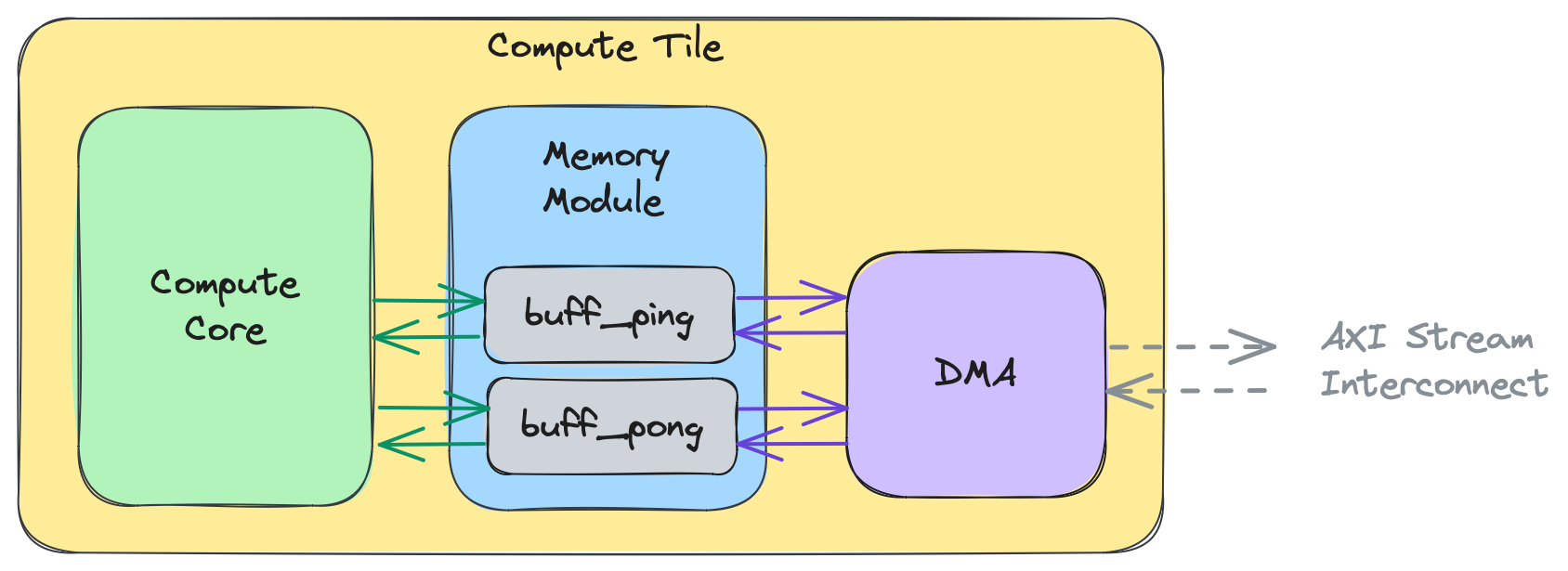
注意: Object FIFOプリミティブを使用せずにDMAを直接設定して、タイル間のデータ移動をセットアップすることができます。これについてはSection 2gで説明します。
演習
-
前のサブセクションでは、
of0の概念的な深さ3を深さの配列[2, 3]として表すことができると説明しました。DMAに関する高度な知識があれば、これらがデッドロックせずに設計を実行するために必要な最小の深さだと思いますか?答えを見る
いいえ。プロデューサAの場合、単一のオブジェクトのみを割り当てる必要があります。その場合、コンピュートコアとDMAは、他の当事者がそれぞれ計算またはデータを移動している間待機する必要があります。これはコンシューマBでも同様で、深さ2で十分です。したがって、デッドロックせずに設計を実行するための最小の深さは[1, 2]です。 -
深さ
[2, 3]は、AとB両方のコンピュートコアがDMAと同時に実行するのに十分だと思いますか?答えを見る
プロデューサAは、DMAと同時に機能するためにピンポンバッファを必要とします。同様に、コンシューマBは、Bが計算している間にDMAが新しいデータを書き込むことができる2つの追加オブジェクトを必要とします。更新された深さは[2, 4]です。