Object FIFOブロードキャストパターン
導入セクションで説明したように、Object FIFOは1つまたは複数のコンシューマを持つことができます。最高レベルの抽象化では、cons()を呼び出すたびに、そのコンシューマ用の新しいObjectFifoHandleが返されます。明示的に配置された抽象化レベルでは、consumerTiles入力は単一のタイルまたはタイルの配列のいずれかになります。入力がタイルの配列として指定されている場合、これは単一のプロデューサタイルから複数のコンシューマタイルへのブロードキャスト通信を作成します。プロデューサタイルのメモリモジュールからのデータは、AXIストリームインターコネクトを介して各コンシューマタイルのメモリモジュールに送信されます。AXIストリームインターコネクトは、実行時間が異なるコンシューマからのバックプレッシャーを処理します。AXIストリームは、各コンシューマに送信される前にデータの低レベルコピーが作成される場所でもあります。ブロードキャストを実現するために、低レベル化ではプロデューサタイルの1つの出力ポートを使用してすべてのコンシューマタイルへの接続を確立します。以下の図に示すとおりです:
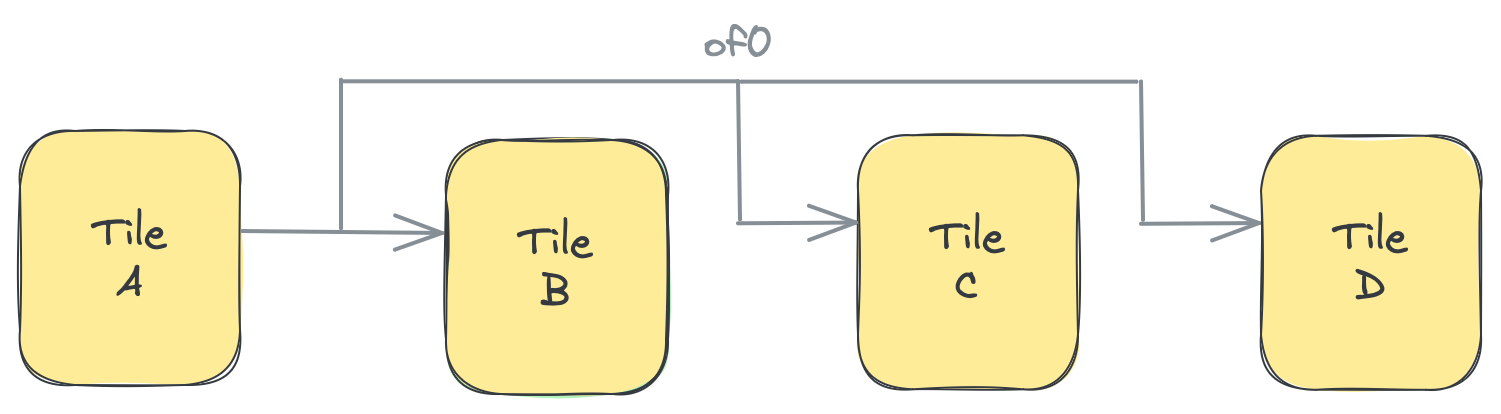
Object FIFOのオブジェクトがプロデューサおよびコンシューマタイルのDMAを介してAXIストリームを通じて転送される方法の詳細については、mlir-aieのチュートリアルを参照してください。ただし、Object FIFO APIを理解または使用するために必要ではありません。
以下は、前の図に示されているObject FIFO of0の例です。深さは3で、1つのWorkerがプロデューサプロセスを実行し、3つのWorkerがコンシューマプロセスを実行します:
# ObjectFifosを使用したデータフロー
of0 = ObjectFifo(line_type, name="objfifo0", depth=3)
# 外部バイナリカーネル定義
# ...
# コアが実行するタスク
# ...
# タスクを実行するWorkerを作成
my_worker = Worker(core_fn, [of0.prod(), test_fn])
my_worker2 = Worker(core_fn2, [of0.cons(), test_fn2])
my_worker3 = Worker(core_fn3, [of0.cons(), test_fn2])
my_worker4 = Worker(core_fn4, [of0.cons(), test_fn2])
次のコードスニペットは、上記と同じ例を、プロデューサWorkerがタイルAにマッピングされ、コンシューマWorkerがタイルB、C、Dにマッピングされている、エンドポイントが明示的に配置されたより低レベルの抽象化でどのように記述されるかを示しています:
A = tile(1, 1)
B = tile(1, 3)
C = tile(2, 3)
D = tile(3, 3)
of0 = object_fifo("objfifo0", A, [B, C, D], 3, np.ndarray[(256,), np.dtype[np.int32]])
スキップ接続を伴うブロードキャスト
明示的に配置された抽象化レベルでは、Object FIFOのdepth入力も整数の配列として指定できます。これは、Object FIFOにアクセスするときに各タイル(プロデューサタイルと各コンシューマタイル)が利用できるオブジェクトの数を記述します。前の例では、4つのタイルのそれぞれが、of_0のデータ移動を実行するために利用可能な3つのオブジェクトのリソースプールを持っています。
注意: Object FIFOプリミティブのこの機能は、ブロードキャストのためにデータ移動が確立されたときにハードウェアレベルで実際に何が起こっているかを公開します。Object FIFOのオブジェクトプールは単一の構造ではなく、データ移動に関与する各タイルのメモリモジュールに割り当てられたオブジェクトのいくつかのプールで構成されています。
depthを整数の配列として指定すると、ユーザーは各個別タイルのプールのサイズを設定するための完全な制御を得ることができます。詳細については、セクション2aを参照してください。
この機能の主な利点は、以下の例に示すような状況で明らかになります。これをスキップ接続を伴うブロードキャストと呼びます。以下の例では、2つのObject FIFOが作成されています:of0はプロデューサタイルAからコンシューマタイルBおよびCへのブロードキャストであり、of1はプロデューサタイルBからコンシューマタイルCへの1対1のデータ移動です。A → B → Cチェーンでbを飛び越してA → Cを接続するため、of0をスキップ接続と呼びます。
A = tile(1, 3)
B = tile(2, 3)
C = tile(2, 4)
of0 = object_fifo("objfifo0", A, [B, C], 1, np.ndarray[(256,), np.dtype[np.int32]])
of1 = object_fifo("objfifo1", B, C, 1, np.ndarray[(256,), np.dtype[np.int32]])
この状況は、以下の図のように見ることができます:
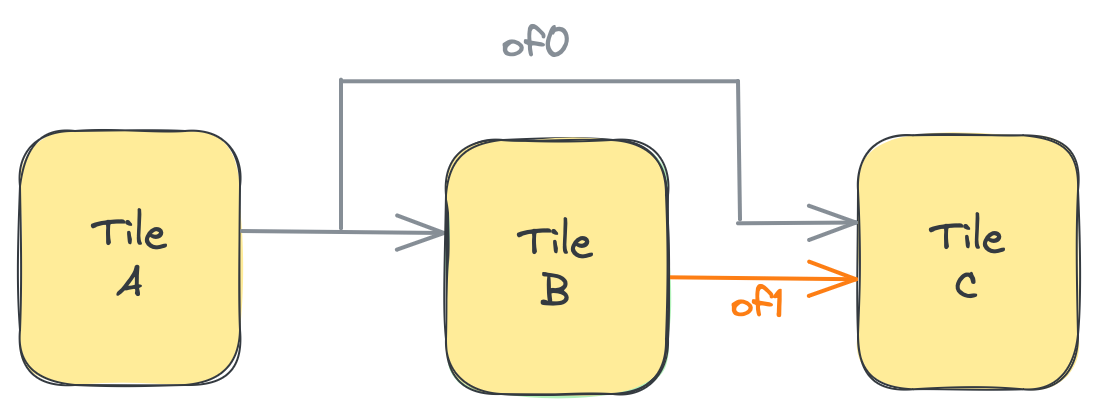
ここで、of0の2つのコンシューマで実行されているプロセスが以下のコードスニペットのようであると仮定します。
@core(B)
def core_body():
elem0 = of0.acquire(ObjectFifoPort.Consume, 1)
elem1 = of1.acquire(ObjectFifoPort.Produce, 1)
test_func2(elem0, elem1)
of0.release(ObjectFifoPort.Consume, 1)
of1.release(ObjectFifoPort.Produce, 1)
@core(C)
def core_body():
elem0 = of0.acquire(ObjectFifoPort.Consume, 1)
elem1 = of1.acquire(ObjectFifoPort.Consume, 1)
test_func2(elem0, elem1)
of0.release(ObjectFifoPort.Consume, 1)
of1.release(ObjectFifoPort.Consume, 1)
Cは実行を進める前にof0とof1の両方から1つのオブジェクトを必要とすることがわかります。ただし、Bもof1のデータを生成する前にof0からオブジェクトを必要とします。CがBを待っているため、2つのタイルはブロードキャスト接続からの消費レートが同じではなく、これによりAの生産レートが影響を受けます。
これをさらに表現するために、コンシューマタイルがそれぞれのObject FIFOに割り当てられたオブジェクトのプールを持っているという、わずかに低レベルの見方をすることができます。簡単にするために、コンシューマが使用するプールのみが表示されています(たとえば、of1の場合、コンシューマタイルC側のプールのみが表示されています)。現在、すべてのプールの深さは1です。
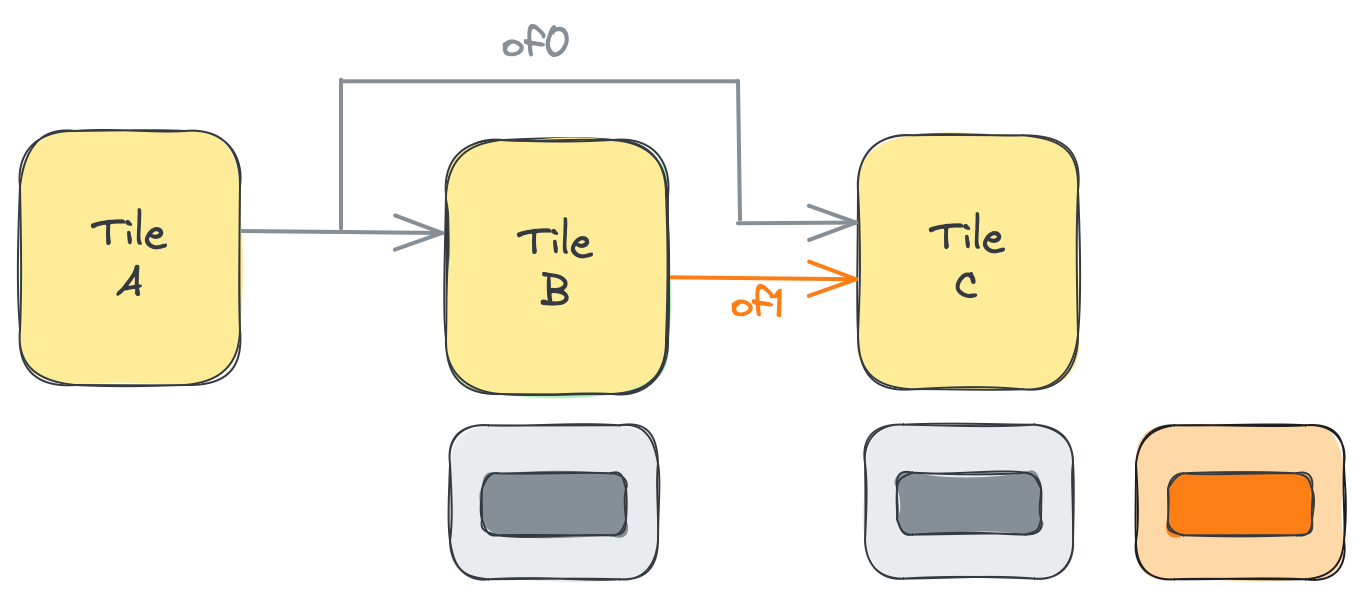
スキップ接続によってAの生産が影響を受けないようにするには、of0のためにCに追加のオブジェクトが必要です。これは、of1を介してBからのデータを待っている間にof0から来るデータのバッファリングスペースとして使用できます。これを実現するために、of0はdepthに整数の配列を使用して作成されます:
of0 = object_fifo("objfifo0", A, [B, C], [1, 1, 2], np.ndarray[(256,), np.dtype[np.int32]])
ここで、タイルAとBは元の深さ1を保持し、Cは深さ2のオブジェクトを持つようになりました。この変更は、以下の図のように視覚化できます。タイルCのof0のオブジェクトプールが増加しています:

注意: より詳細な情報については、公式ドキュメントを参照してください。