Object FIFO間の暗黙的コピー:DistributeとJoinパターン
Object FIFOの暗黙的コピー
設計上、Object FIFOはプロデューサとコンシューマ間のデータ移動の構成と、Workerのメモリモジュール上のオブジェクトの割り当ての両方を処理します。1つのObject FIFOから消費されたデータは、2つのFIFO間で共有されるWorkerのコアコードで別のObject FIFOに明示的にコピーできます。これは、以下のコードスニペットに示されており、Workerはof_inからof_outにデータをコピーします:
of_in = ObjectFifo(line_type, name="in")
of_out = ObjectFifo(line_type, name="out")
def core_fn(of_in, of_out, copy_fn):
elem_in = of_in.acquire(1)
elem_out = of_out.acquire(1)
copy_fn(elem_in, elem_out)
of_in.release(1)
out.release(1)
my_worker = Worker(core_fn, [of_in.cons(), of_out.prod(), copy_fn])
ただし、目標がデータを変更せずに単に1つのObject FIFOから別のObject FIFOにコピーすることである場合、上記の方法で行うと、必要以上に多くのオブジェクトを割り当てることになります。つまり、2番目のObject FIFOにコピーされるデータは、最初のObject FIFOですでに利用可能です。さらに、ShimタイルとMemタイルには、コピーを明示的に実行できるコアがありません。
明示的コピーの代わりに、Object FIFO APIはforward()関数(objectfifo.pyで定義)を介して暗黙的コピーを提供します。ここで、コンシューマ型のObjectFifoHandleが新しく構築されたObject FIFOのプロデューサに転送されます:
def forward(
self,
placement: PlacementTile = AnyMemTile,
obj_type: type[np.ndarray] | None = None,
depth: int | None = None,
name: str | None = None,
dims_to_stream: list[Sequence[int]] | None = None,
dims_from_stream: list[Sequence[int]] | None = None,
plio: bool = False,
)
forward()関数は、ユーザーが通常のObject FIFOと同じ入力を追加で指定できる新しいObject FIFOを作成します。placementタイルは暗黙的コピーが実行される場所であり、デフォルトではMemタイルに設定されています。
暗黙的コピーを使用すると、前のコードは次のように記述できます:
of_in = ObjectFifo(line_type, name="in")
of_out = of_in.cons().forward(obj_type=line_type, name="out")
ここで、of_inへのコンシューマObjectFifoHandleがof_outのプロデューサとして転送されます。
この機能は、明示的に配置された抽象化レベルでも使用できます。Object FIFO APIは、object_fifo_linkを介して暗黙的コピーを提供します。これは、クラスコンストラクタ(aie.pyで定義)を使用して初期化できます:
class object_fifo_link(ObjectFifoLinkOp):
def __init__(
self,
fifoIns,
fifoOuts,
srcOffsets=[],
dstOffsets=[],
)
リンクを使用すると、ユーザーはfifoIns入力を介して入力Object FIFOのセットを指定し、fifoOuts入力を介して出力Object FIFOのセットを指定できます。各Object FIFOは、そのnameまたはそのPythonオブジェクトのいずれかを使用して指定できます。両方の入力は、単一のObject FIFOまたはそれらの配列のいずれかになります。リンクが有効であるためには、fifoInsのコンシューマタイルとfifoOutsのプロデューサタイルの間に少なくとも1つの共有タイルが存在する必要があります。これは、データの暗黙的コピーがそのタイルのダイレクトメモリアクセスチャネル(DMA)を使用して行われるためです。
以下は、2つのFIFO of_inとof_outの間に作成されたリンクの例です。ここで、タイルBはそれらの間の共有タイルです:
A = tile(1, 0)
B = tile(1, 1)
C = tile(1, 3)
of_in = object_fifo("in", A, B, 2, np.ndarray[(256,), np.dtype[np.int32]])
of_out = object_fifo("out", B, C, 2, np.ndarray[(256,), np.dtype[np.int32]])
object_fifo_link(of_in, of_out)
fifoInsとfifoOutsで指定されているObject FIFOの数に応じて、2つの異なるデータパターンを実現できます:DistributeまたはJoinです。これらは次の2つのサブセクションで説明されています。現在、両方のパターンを一度に実行することはできません。つまり、fifoInsが配列の場合、fifoOutsは単一のObject FIFOのみであり、その逆も同様です。最高レベルの抽象化では、これらのパターンも利用可能です。
この機能を使用する完全なデザイン例は、セクション2fで利用できます:03_external_mem_to_core_L2。
Distribute
ユーザーは、Object FIFO APIを使用して、プロデューサからのすべてのオブジェクトのデータの一部が複数のコンシューマに分散されるdistributeパターンを記述できます。これはsplit()関数(objectfifo.pyで定義)で実行できます:
def split(
self,
offsets: list[int],
placement: PlacementTile = AnyMemTile,
depths: list[int] | None = None,
obj_types: list[type[np.ndarray]] = None,
names: list[str] | None = None,
dims_to_stream: list[list[Sequence[int]]] | None = None,
dims_from_stream: list[list[Sequence[int]]] | None = None,
plio: bool = False,
) -> list[ObjectFifo]
split()関数は、ユーザーが通常のObject FIFOと同じ入力を追加で指定できる複数のコンシューマObject FIFOを作成します。offsetsは、プロデューサObject FIFOの割り当てられたメモリのどの場所から各コンシューマObject FIFOにデータを送信するかを指定するために使用されます。
以下は、Object FIFOのコンシューマObjectFifoHandleが2つのコンシューマに分割される例です。つまり、デザインで使用されるコアの数です。split()関数には、各コンシューマObject FIFOにデータが送信されるオフセット、そのオブジェクトのデータ型、およびそれらの名前が追加で与えられます。
of0 = ObjectFifo(mem_tile_ty, name="objfifo0")
n_cores = 2
of_offsets = [
(np.prod(np_ndarray_type_get_shape(mem_tile_ty)) // n_cores) * i
for i in range(n_cores)
]
of0_fifos = of0.cons().split(
of_offsets,
obj_types=[aie_tile_ty] * n_cores,
names=[f"objfifo{i}" for i in range(n_cores)],
)
コンシューマ型のObjectFifoHandleのみを分割できます。出力FIFOのobj_typesは入力FIFOよりも小さいサイズである必要があり、出力FIFOのサイズの合計は入力FIFOのobj_typeのサイズと等しくなければなりません。
1つの入力Object FIFOと複数の出力Object FIFOを持つリンクを使用することで、ユーザーはプロデューサタイルからのすべてのオブジェクトのデータの一部が各出力FIFOに分散されるdistributeパターンを記述できます。出力FIFOのdatatypeは入力FIFOよりも小さいサイズである必要があり、出力FIFOのサイズの合計は入力FIFOのdatatypeのサイズと等しくなければなりません。
現在、Object FIFOの低レベル化では、fifoOutsで出力FIFOが指定されている順序を使用して、入力オブジェクトのどの部分が各出力FIFOに行くべきかを知ります。distributeを実現するために、低レベル化では、共有タイルの1つの出力ポートを使用して、以下の図のように出力FIFOごとに接続を確立します:

次のコードスニペットは、上記の図を説明しています。3つのObject FIFOがあります:of0はプロデューサタイルAとコンシューマタイルBを持ち、of1とof2はBをプロデューサタイルとし、それぞれCとDをコンシューマタイルとして持ちます。リンクは、of0からのデータがof1とof2に分散されることを指定します。このリンクでは、BはBのDMAを介して暗黙的データコピーが行われる共有タイルです。また、of1とof2のデータ型がof0の半分であることにも注意できます。これは、of0のオブジェクトの前半がof1に、後半がof2に行くことを意味します。これはリンク内の順序に基づいています。これは、リンクのdstOffsetsオプションを指定することで明示的に設定されます。
A = tile(1, 0)
B = tile(1, 1)
C = tile(1, 3)
D = tile(2, 3)
of0 = object_fifo("objfifo0", A, B, 2, np.ndarray[(256,), np.dtype[np.int32]])
of1 = object_fifo("objfifo1", B, C, 2, np.ndarray[(128,), np.dtype[np.int32]])
of2 = object_fifo("objfifo2", B, D, 2, np.ndarray[(128,), np.dtype[np.int32]])
object_fifo_link(of0, [of1, of2], [], [0, 128])
この機能を使用する完全なデザイン例は、セクション2fで利用できます:04_distribute_L2。
Join
joinパターンは、複数のObject FIFOから受信されたデータが結合され、単一の出力Object FIFOに送信されるdistributeパターンの逆です。これはjoin()関数(objectfifo.pyで定義)で実行できます:
def join(
self,
offsets: list[int],
placement: PlacementTile = AnyMemTile,
depths: list[int] | None = None,
obj_types: list[type[np.ndarray]] = None,
names: list[str] | None = None,
dims_to_stream: list[list[Sequence[int] | None]] | None = None,
dims_from_stream: list[list[Sequence[int] | None]] | None = None,
plio: bool = False,
) -> list[ObjectFifo]
join()関数は、ユーザーが通常のObject FIFOと同じ入力を追加で指定できる複数のプロデューサObject FIFOを作成します。offsetsは、各プロデューサObject FIFOからプロデューサObject FIFOの割り当てられたメモリのどの場所にデータを書き込むかを指定するために使用されます。
以下は、2つのObject FIFOが作成され、of0のプロデューサObjectFifoHandleに結合される例です。join()関数には、各プロデューサObject FIFOによってデータが書き込まれるオフセット、そのオブジェクトのデータ型、およびそれらの名前が追加で与えられます。
of0 = ObjectFifo(mem_tile_ty, name="objfifo0")
n_cores = 2
of_offsets = [
(np.prod(np_ndarray_type_get_shape(mem_tile_ty)) // n_cores) * i
for i in range(n_cores)
]
of0_fifos = of0.prod().join(
of_offsets,
obj_types=[aie_tile_ty] * n_cores,
names=[f"objfifo{i}" for i in range(n_cores)],
)
プロデューサ型のObjectFifoHandleのみを結合できます。入力FIFOのobj_typesは出力FIFOよりも小さいサイズである必要があり、入力FIFOのサイズの合計は出力FIFOのobj_typeのサイズと等しくなければなりません。
リンクを使用したjoinパターンは、複数の入力Object FIFOと単一の出力Object FIFOを持ちます。このパターンを使用すると、ユーザーは複数のソースからの小さな入力を単一の大きな出力データ移動に結合できます。入力FIFOのdatatypeは出力FIFOよりも小さいサイズである必要があり、入力FIFOのサイズの合計は出力FIFOのdatatypeのサイズと等しくなければなりません。
同様に、fifoIns内の順序は、どの入力オブジェクトが出力Object FIFOのより大きなオブジェクトのどの部分を構成するかを指定します。joinを実現するために、低レベル化では、共有タイルの1つの入力ポートを使用して、以下の図のように入力FIFOごとに接続を確立します:
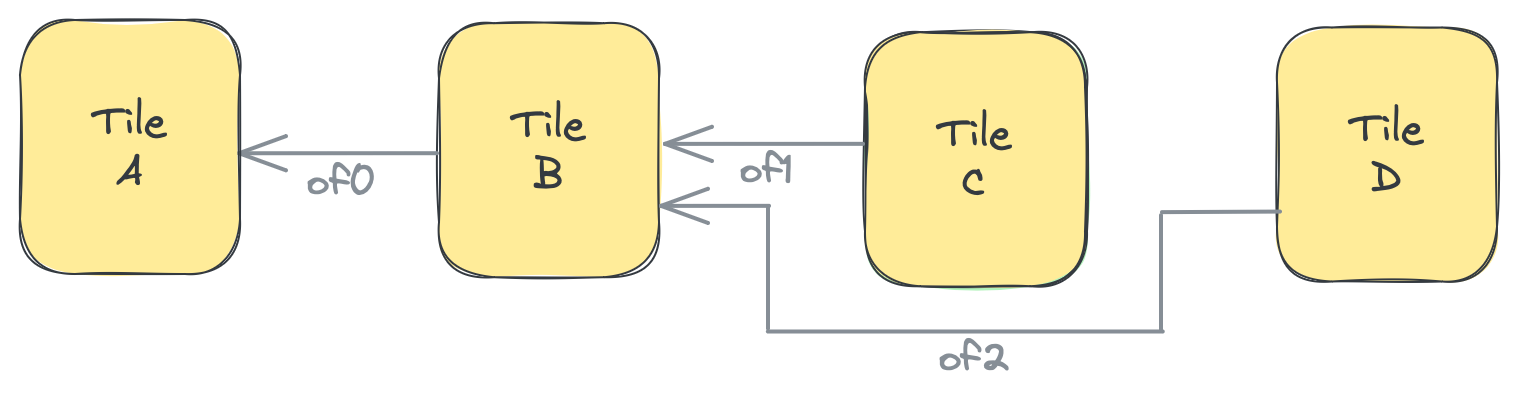
次のコードスニペットは、上記の図を説明しています。3つのObject FIFOがあります:of0はプロデューサタイルBとコンシューマタイルAを持ち、of1とof2はそれぞれCとDをプロデューサタイルとし、Bをコンシューマタイルとして持ちます。リンクは、of1とof2からのデータがof0に結合されることを指定します。このリンクでは、BはBのDMAを介して暗黙的データコピーが行われる共有タイルです。また、of1とof2のデータ型がof0の半分であることにも注意できます。これは、of1からのオブジェクトがof0のオブジェクトの前半になり、of2のオブジェクトが後半になることを意味します。これはリンク内の順序に基づいています。
A = tile(1, 0)
B = tile(1, 1)
C = tile(1, 3)
D = tile(2, 3)
of0 = object_fifo("objfifo0", B, A, 2, np.ndarray[(256,), np.dtype[np.int32]])
of1 = object_fifo("objfifo1", C, B, 2, np.ndarray[(128,), np.dtype[np.int32]])
of2 = object_fifo("objfifo2", D, B, 2, np.ndarray[(128,), np.dtype[np.int32]])
object_fifo_link([of1, of2], of0, [0, 128], [])
これらの機能を使用する完全なデザイン例は、セクション2fで利用できます:05_join_L2。
注意: より詳細な情報については、公式ドキュメントを参照してください。