Section 2g - Object FIFOを使わないデータ移動
すべてのデータ移動パターンがObject FIFOで記述できるわけではありません。この高度なセクションでは、AIEタイルのDirect Memory Access チャネル(またはDMA)を使用してデータ移動を表現する方法について詳しく説明します。このセクションで紹介されるコードと概念をより理解するために、まずSection 2aの高度なトピック - DMAについてを読むことをお勧めします。
このガイドの部分は、明示的配置レベルIRONで説明されています。
AIEアーキテクチャには現在3つの異なるタイプのタイルがあります:「tile」と呼ばれるコンピュートタイル、「Mem tiles」と呼ばれるメモリタイル、「Shim tiles」と呼ばれる外部メモリインターフェイスタイルです。これらのタイルはそれぞれ、演算能力とメモリ容量に関して独自の属性を持っていますが、DMAの基本設計は同じです。異なるタイプのDMAは、aie.pyのコンストラクタを使用して初期化できます:
@mem(tile) # コンピュートタイルのDMA
@shim_dma(tile) # ShimタイルのDMA
@memtile_dma(tile) # MemタイルのDMA
DMAハードウェアコンポーネントには、一定数の入力および出力channels(チャネル)があり、それぞれに方向とポートインデックスがあります。入力チャネルはキーワードS2MMで示され、出力チャネルはMM2Sで示されます。ポートインデックスはタイルごとに異なります。たとえば、コンピュートタイルとShimタイルには2つの入力ポートと2つの出力ポートがありますが、Memタイルには6つの入力ポートと6つの出力ポートがあります。
任意のタイルのDMAのチャネルは、統一されたdmaコンストラクタを使用して初期化できます:
def dma(
channel_dir,
channel_index,
*,
num_blocks=1,
loop=None,
repeat_count=None,
sym_name=None,
loc=None,
ip=None,
)
各チャネルでのデータ移動は、バッファディスクリプタ(または「BD」)のチェーンによって記述されます。各BDは、移動されるデータを記述し、その同期メカニズムを設定します。dmaコンストラクタは、num_blocks=1というデフォルト値の入力で見られるように、すでにそのようなBDのためのスペースを1つ作成します。
以下のコードスニペットは、tile_aのDMAを設定して、入力チャネル0に入ってくるデータをbuff_inに書き込む方法を示しています:
tile_a = tile(1, 3)
prod_lock = lock(tile_a, lock_id=0, init=1)
cons_lock = lock(tile_a, lock_id=1, init=0)
buff_in = buffer(tile=tile_a, datatype=np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
@mem(tile_a)
def mem_body():
@dma(S2MM, 0) # 入力チャネル、ポート0
def dma_in_0():
use_lock(prod_lock, AcquireGreaterEqual)
dma_bd(buff_in)
use_lock(cons_lock, Release)
ロックprod_lockとcons_lockは、AIE-MLアーキテクチャのセマンティクスに従います。それらのタスクは、タイルとそのDMAの実行における同期ポイントをマークすることです。たとえば、タイルが現在buff_inを使用している場合、それが完了したときのみprod_lockを解放し、その時にDMAがbuff_inの新しい入力でデータを上書きすることが許可されます。同様に、タイルのコアはcons_lockを照会して、新しいデータが読み取り可能になったこと(つまり、DMAがロックを解放してコアが取得できるようになったとき)を知ることができます。
前のコードでは、チャネルにはチェーン内に1つのBDしかありませんでした。チェーンに追加のBDを追加するには、ユーザーは以下のコンストラクタを使用できます。このコンストラクタは、追加されるチェーン内の前のBDを入力として受け取ります:
@another_bd(dma_bd)
次のコードスニペットは、前のコンストラクタを使用して、前の入力チャネルをダブル(またはピンポン)バッファで拡張する方法を示しています:
tile_a = tile(1, 3)
prod_lock = lock(tile_a, lock_id=0, init=2) # プロデューサロックが2つのトークンを持つことに注意
cons_lock = lock(tile_a, lock_id=1, init=0)
buff_ping = buffer(tile=tile_a, datatype=np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
buff_pong = buffer(tile=tile_a, datatype=np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
@mem(tile_a)
def mem_body():
@dma(S2MM, 0, num_blocks=2) # 追加のBDに注意
def dma_in_0():
use_lock(prod_lock, AcquireGreaterEqual)
dma_bd(buff_ping)
use_lock(cons_lock, Release)
@another_bd(dma_in_0)
def dma_in_1():
use_lock(prod_lock, AcquireGreaterEqual)
dma_bd(buff_pong)
use_lock(cons_lock, Release)
注意: このDMA設定は、ダブルバッファのObject FIFO低レベル化の形式と同等です。
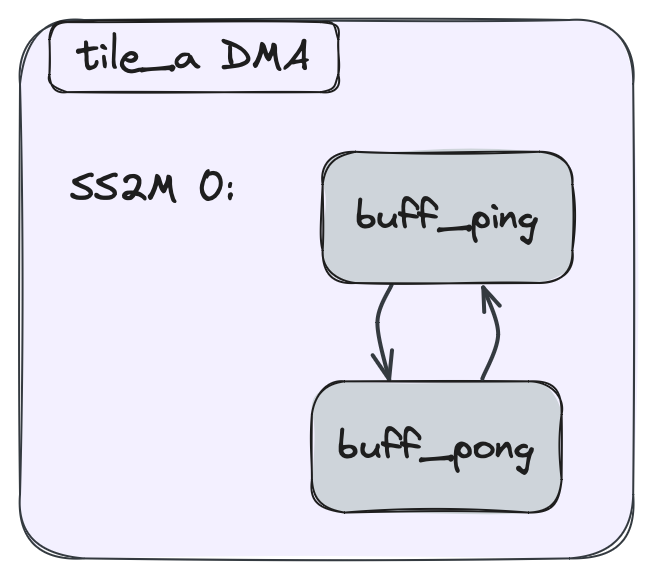
上記のコードは、次の図のように視覚化できます。ここで、2つのBDが相互にピンポンします:
データ移動を設定する最後のステップは、Object FIFOがプロデューサタイルとコンシューマタイルを持つのと同様に、そのエンドポイントを確立することです。これを行うには、ユーザーはflowコンストラクタを使用する必要があります:
def flow(
source,
source_bundle=None,
source_channel=None,
dest=None,
dest_bundle=None,
dest_channel=None,
)
flowは、2つのDMAのチャネル間で確立されます(他のエンドポイントも利用可能ですが、このセクションの範囲を超えています)。そのため、以下が必要です:
sourceとdestタイルsource_bundleとdest_bundle(エンドポイントのタイプを表し、我々の範囲ではWireBundle.DMAになります)source_channelとdest_channel(チャネルのインデックスを表します)
たとえば、タイルtile_aとタイルtile_bの間にフローを作成し、tile_aがその出力チャネル0でtile_bの入力チャネル1にデータを送信する場合、ユーザーは以下のように記述できます:
aie.flow(tile_a, WireBundle.DMA, 0, tile_b, WireBundle.DMA, 1)
2つのチャネルの方向はフローで必要とされず、インデックスのみであることに注意してください。これは、フローの低レベル化がsourceとdest入力に基づいて方向を推論できるためです。
次のコードスニペットは、tile_aがtile_bにデータを送信する2つのタイルの完全な例を示しています:
tile_a = tile(1, 2)
tile_b = tile(1, 3)
prod_lock_a = lock(tile_a, lock_id=0, init=1)
cons_lock_a = lock(tile_a, lock_id=1, init=0)
buff_a = buffer(tile=tile_a, np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
prod_lock_b = lock(tile_b, lock_id=0, init=1)
cons_lock_b = lock(tile_b, lock_id=1, init=0)
buff_b = buffer(tile=tile_b, np.ndarray[(256,), np.dtype[np.int32]]) # 256xi32
aie.flow(tile_a, WireBundle.DMA, 0, tile_b, WireBundle.DMA, 1)
@mem(tile_a)
def mem_body():
@dma(MM2S, 0) # 出力チャネル、ポート0
def dma_in_0():
use_lock(cons_lock_a, AcquireGreaterEqual)
dma_bd(buff_a)
use_lock(prod_lock_a, Release)
@mem(tile_b)
def mem_body():
@dma(S2MM, 1) # 入力チャネル、ポート1
def dma_in_0():
use_lock(prod_lock_b, AcquireGreaterEqual)
dma_bd(buff_b)
use_lock(cons_lock_b, Release)
注意: より詳細な情報については、公式ドキュメントを参照してください。