Section 4b - トレース
セクション4aでは、タイマーを使用した性能測定について説明しましたが、AIEハードウェアを最大限に最適化したいカーネルプログラマにとって、AIEコアとデータムーバーがどれだけ効率的に実行されているかを確認できることは重要です。AIE2トレースユニットは、サイクル精度のハードウェアイベント可視性を提供します。詳細については、AM020仕様書を参照してください。
トレースサポートを有効にする手順
- AIEトレースユニットを有効にして構成する
- トレースデータを読み取ってテキストファイルに書き込むようにホストコードを構成する
- テキストファイルを解析して波形JSONファイルを生成する
- JSONファイルをPerfettoなどの可視化ツールで開く
- 追加のデバッグヒント
1. AIEトレースユニットを有効にして構成する
トレースは、セクション3で使用したvector_scalar_mul設計(aie2.py)を例として使用します。AIE構造設計でトレースを有効にするには、Runtimeクラスでenable_traceメソッドを使用します。最も単純な形式では、トレースデータのサイズと、トレースするWorkerのリストを提供します。
rt = Runtime()
rt.enable_trace(trace_size=8192, workers=[my_worker])
または、Workerを宣言する際にtrace=1引数を使用することもできます。その場合、enable_traceメソッドにワーカーを明示的に渡す必要はありません。
# Task for the core to perform
def core_fn(of_in, of_factor, of_out, scale_scalar):
...
# Create a worker to perform the task
my_worker = Worker(
core_fn,
[of_in.cons(), of_factor.cons(), of_out.prod(), scale_fn],
trace=1,
)
rt.enable_trace(trace_size=8192)
重要: ランタイムシーケンスのenable_traceのworkers引数は、常にWorkerのtrace=1引数よりも優先されます。両方が指定されている場合、enable_traceのworkersリストに従います。
トレース動作のカスタマイズ
enable_traceメソッドには、トレース動作をカスタマイズするための追加のオプション引数があります:
trace_offset: トレースバッファのオフセット(バイト単位)。デフォルトは0。ddr_id: どのXRTバッファにトレースデータを書き込むか。デフォルトは7(XRT group_id 7)。coretile_events: コアタイルで監視する8つのイベント。memtile_events: メモリタイルで監視する8つのイベント。shimtile_events: シムタイルで監視する8つのイベント。
カスタムトレース設定の例:
from aie.extras.dialects.ext.arith import constant
from aie.dialects.aie import *
rt = Runtime()
rt.enable_trace(
trace_size=16384,
workers=[my_worker],
trace_offset=0,
ddr_id=7,
coretile_events=[
CoreEvent.INSTR_EVENT_0,
CoreEvent.INSTR_EVENT_1,
CoreEvent.INSTR_VECTOR,
CoreEvent.PORT_RUNNING_0,
CoreEvent.PORT_RUNNING_1,
CoreEvent.PORT_RUNNING_2,
CoreEvent.PORT_RUNNING_3,
CoreEvent.PORT_RUNNING_7,
],
)
トレース可能なイベントの完全なリストについては、README-placed.mdを参照してください。
2. トレースデータを読み取ってテキストファイルに書き込むようにホストコードを構成する
AIE構造設計コード(aie2.py)
ホストコードを理解するには、まずAIE構造設計が何を生成するかを理解する必要があります。aie2.pyでトレースを有効にすると(enable_traceの呼び出しによって)、XRTバッファ(BO)の1つがトレースデータの書き込み用に予約されます。enable_traceのddr_idパラメータで、どのXRTバッファを使用するかを指定します。デフォルトはXRT group_id 7(またはinout4)です。この設計例では、inout0からinout4までの5つのXRTバッファ(group_id 3から7)が利用可能です。
XRTバッファマッピング
| XRTバッファインデックス | XRT group_id | 設定されたグローバルバッファ名 |
|---|---|---|
| inout0 | 3 | N/A |
| inout1 | 4 | N/A |
| inout2 | 5 | N/A |
| inout3 | 6 | N/A |
| inout4 | 7 | N/A |
デフォルトでは、すべてのXRTバッファは使用可能で、設定されたグローバルバッファがないため、ランタイムシーケンスで使用される順序に基づいてマッピングされます。test.cppでは、ランタイムシーケンスは次のようになります:
with rt.sequence(tensor_ty, scalar_ty, tensor_ty) as (inp, factor, out):
rt.start(my_worker)
rt.fill(of_in.prod(), inp)
rt.fill(of_factor.prod(), factor)
rt.drain(of_out.cons(), out, wait=True)
最初の引数が最初の使用可能なXRTバッファ(group_id 3)にマッピングされます。2番目の引数はgroup_id 4に、3番目はgroup_id 5にマッピングされます。このマッピングは以下のようになります:
| XRTバッファインデックス | XRT group_id | 設定されたグローバルバッファ名 | ランタイムシーケンス引数 |
|---|---|---|---|
| inout0 | 3 | N/A | inp(入力ベクトル) |
| inout1 | 4 | N/A | factor(スカラー係数) |
| inout2 | 5 | N/A | out(出力ベクトル) |
| inout3 | 6 | N/A | N/A |
| inout4 | 7 | N/A | trace(トレースバッファ) |
2a. C/C++ホストコード
test.cppでは、トレース用の追加のXRTバッファオブジェクトを作成する必要があります。これは他の入出力バッファと同じように作成されますが、group_idは7(inout4)を使用します:
size_t tmp_trace_size = trace_size;
if (tmp_trace_size < TRACE_SIZE_MIN)
tmp_trace_size = TRACE_SIZE_MIN;
auto bo_trace = xrt::bo(device, tmp_trace_size, XRT_BO_FLAGS_HOST_ONLY, kernel.group_id(7));
char *bufTrace = bo_trace.map<char *>();
memset(bufTrace, 0, tmp_trace_size);
bo_trace.sync(XCL_BO_SYNC_BO_TO_DEVICE);
...カーネル実行...
bo_trace.sync(XCL_BO_SYNC_BO_FROM_DEVICE);
トレースバッファをデバイスから同期した後、テキストファイルに書き出します:
test_utils::write_out_trace((char *)bufTrace, trace_size, trace_file);
Makefileでのバッファサイズ設定
Makefileでは、トレースサイズと他のバッファサイズがCMakeに渡されます:
trace_size ?= 8192
M ?= 512
K ?= 512
N ?= 512
データ型の一貫性
Pythonのaie2.pyで定義されたデータ型は、test.cppのデータ型と一致する必要があります。
Python(aie2.py):
tensor_ty = np.ndarray[(tensor_size,), np.dtype[np.int32]]
C++(test.cpp):
using DATATYPE = std::int32_t;
バッファの初期化と検証
test.cppでは、トレースデータをキャプチャしながら、CMakeLists.txtで定義されたバッファサイズとデータ型に基づいてバッファを初期化し、検証します:
DATATYPE *bufInA = bo_inA.map<DATATYPE *>();
std::vector<DATATYPE> AVec(IN_SIZE);
for (int i = 0; i < IN_SIZE; i++)
AVec[i] = i + 1;
memcpy(bufInA, AVec.data(), (AVec.size() * sizeof(DATATYPE)));
DATATYPE *bufInFactor = bo_inFactor.map<DATATYPE *>();
bufInFactor[0] = 3;
DATATYPE *bufOut = bo_outC.map<DATATYPE *>();
bo_inA.sync(XCL_BO_SYNC_BO_TO_DEVICE);
bo_inFactor.sync(XCL_BO_SYNC_BO_TO_DEVICE);
bo_outC.sync(XCL_BO_SYNC_BO_TO_DEVICE);
...カーネル実行...
bo_outC.sync(XCL_BO_SYNC_BO_FROM_DEVICE);
bool pass = true;
for (uint32_t i = 0; i < IN_SIZE; i++) {
int32_t ref = bufInA[i] * 3;
if (*(bufOut + i) != ref) {
std::cout << "Error in output " << *(bufOut + i) << " != " << ref << std::endl;
pass = false;
}
}
std::cout << (pass ? "PASS!" : "FAIL.") << std::endl;
ビルド
make
make run
2b. Pythonホストコード
Pythonホストコードの場合、test.pyでトレースバッファを登録し、xrt.pyのユーティリティ関数を使用してトレースデータを処理します。トレースバッファは、register_bufferメソッドを使用してAppに登録されます:
app.register_buffer(7, shape=trace_buf_shape, dtype=trace_buf_dtype)
トレースバッファをファイルに書き出すには:
trace_buffer = trace_buffer.view(np.uint32)
write_out_trace(trace_buffer, str(opts.trace_file))
3. テキストファイルを解析して波形JSONファイルを生成する
ホストコードがトレースをテキストファイル(例:trace.txt)に書き出した後、parse_trace.pyを使用してJSONファイルに変換します。このスクリプトはutilsディレクトリにあり、Makefileターゲット経由で呼び出すことができます:
trace:
../../python/parse_trace.py --filename trace.txt --mlir build/aie_trace.mlir --colshift 1 > trace_4b.json
parse_trace.pyの詳細については、utils READMEを参照してください。または、トレースの要約を取得するためにget_trace_summary.pyを使用することもできます。
4. JSONファイルをPerfettoなどの可視化ツールで開く
JSONファイルが生成されたら、Perfettoなどの可視化ツールで開くことができます。PerfettoのUIでは、A/Dキーでパン、W/Sキーでズームできます。
追加のデバッグヒント
-
トレースファイルが空の場合:
enable_traceのXRTバッファがtest.cppの対応するgroup_idと一致していることを確認してください。デフォルトはgroup_id 7(またはinout4)です。 -
読み取り可能なトレースデータが非常に少ない場合: コアの設計が最小限のイベントしか生成しない可能性があります。その場合、ShimTileも追加してトレースしてください。または、DMAバースト長を64Bに削減して、より頻繁なイベントを生成してみてください。
-
トレースオフセットの設定: トレースバッファを別のバッファと共有する場合、
trace_offsetを適切に設定してください。通常、trace_offsetは他のバッファのサイズと等しくなります。 -
マルチコア設計でのタイルのトレースルーティング: マルチコア設計では、各タイルからそのシムDMAへの接続を確認してください。
-
colshift: Phoenixデバイスの場合は
colshift=1、Strixデバイスの場合はcolshift=0を使用してください。 -
XRTバッファの割り当て: トレースサイズの4倍でXRTバッファを割り当てることをお勧めします。これは間欠的な問題を回避するための実験的な回避策です。
-
トレースデータの解析が失敗する場合: trace_events_enum.pyでイベントが正しく定義されているか確認してください。
演習
-
test.cppをビルドして実行します(
makeとmake run)。次に、make traceを実行してトレースJSONファイルを生成します。https://ui.perfetto.devでtrace_4b.jsonを開きます。以下のスクリーンショットのような波形が表示されるはずです。A/Dキーでパン、W/Sキーでズームできます。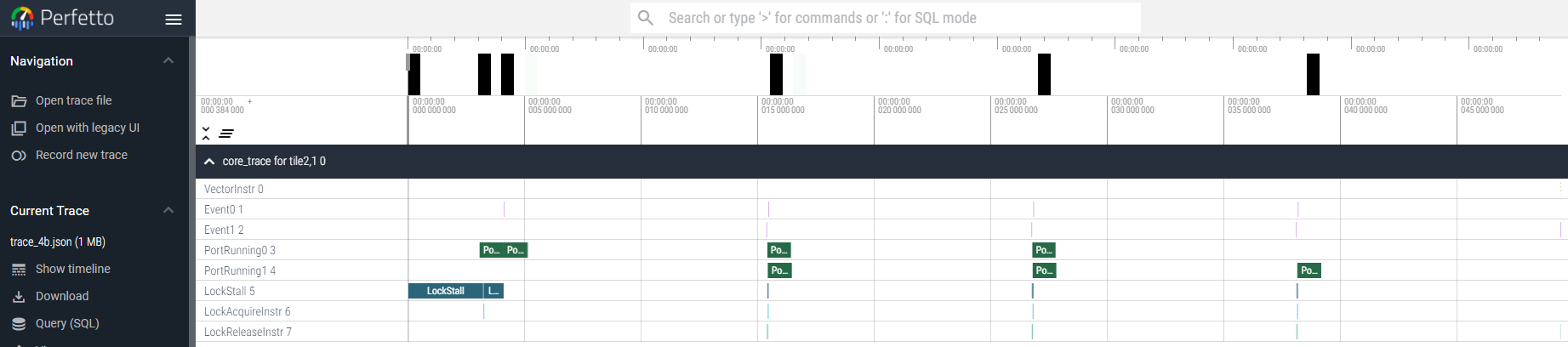
-
トレースには、コアとDMAのイベントの混合が表示されます。一般的なトレースイベントには以下が含まれます:
INSTR_EVENT_0とINSTR_EVENT_1(カーネルの開始と終了をマークする)、INSTR_VECTOR(ベクトル演算の実行)、PORT_RUNNING_0からPORT_RUNNING_7(ポートアクティビティ)、LOCK_STALL、INSTR_LOCK_ACQUIRE_REQ、INSTR_LOCK_RELEASE_REQ(ロック操作)などがあります。トレースイベントの完全なリストについては、trace_events_enum.pyを参照してください。 -
波形を見て、以下の質問に答えてください:
a. カーネルはどのくらい実行されましたか(
INSTR_EVENT_0からINSTR_EVENT_1まで)?答えを見る
約1500サイクルb. ポート0の実行とポート1の実行の間にはどのような関係がありますか?これらのポートは何を表していますか?ヒント:ポート0と1は通常、DMAチャネル0と1に対応します。aie2.pyで、DMAチャネルの設定方法を確認してください。
of_in = ObjectFifo(tile_ty, name="in") # DMAチャネル0 of_out = ObjectFifo(tile_ty, name="out") # DMAチャネル1答えを見る
ポート0(入力DMA)とポート1(出力DMA)は同時に実行され、データフローパイプラインを示しています
注意: より詳細な情報と完全なコード例については、公式ドキュメントを参照してください。